Website Scraping with Python 阅读笔记
第一章
工程涉及的基本工具:requests, beautiful soup, scrapy。
法规与技术约定:read the Terms & Conditions and the Privacy Policy of the website。让不让爬?
See the robots.txt file 。哪些可以爬?
website’s HTML code。目标网页涉及什么技术?
task and the website's structure.。该选什么工具?
Terms and Robots重点读:scraper/scraping
crawler/crawling
bot
spider
program
网页技术:使用python的builtwith库探查网页使用的技术
谷歌浏览器开发者工具:勘察网页
工具选择:small project(简单页面、没有涉及js的) Beautiful Soup + requests or use Scrapy。
有大量数据的,追求性能的 Scrapy + Beautiful Soup。
面对AJAX技术就要打电话摇人了,Selenium and Portia 出场。
第二章 输入请求
确定目标页面,查看目标页的robots.txt文件
对目标页面进行分析,确定找到目标信息的关键步骤
将整个爬取任务分解为几个步骤
整个网站就是一个树形图,域名为主干最终的页面即为叶子,叶子通过分支连接着域名
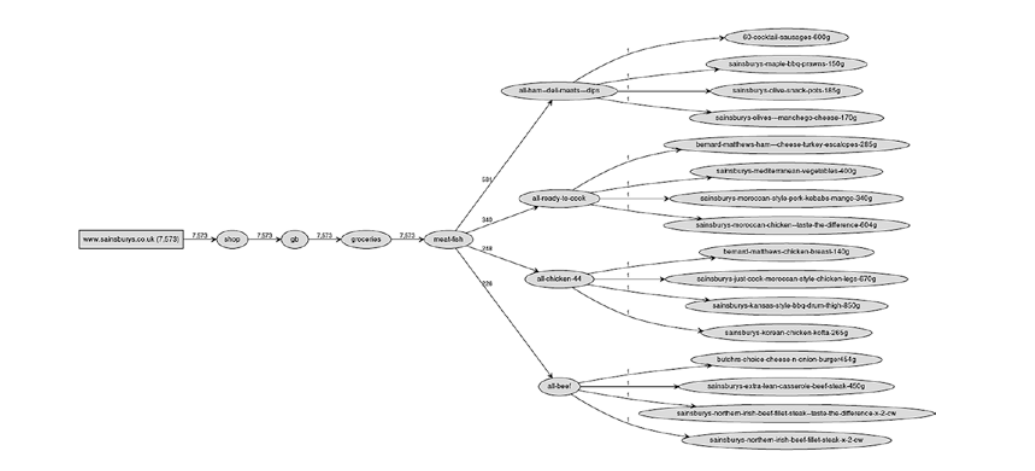
爬虫搜索页面就有了两种方法,一种是广度优先,层层递进式的搜索,另一种是深度优先,一条路走到头,回来再走下一条
第三章 使用BeautifulSoup
导入:from bs4 import BeautifulSoup
它用来解析html内容,提取目标信息
信息保存到csv,json文件
保存到关系数据库
保存到非关系数据库
改进: 1、使用不同的html解析器,html.parser(python自带), lxml(速度快), lxml-xml, html5lib(非常慢)
2、只解析需要的部分,使用SoupStrainer对象,例:
strainer = SoupStrainer(name='ul', attrs={'class':
'productLister gridView'})
soup = BeautifulSoup(content, 'html.parser', parse_only=strainer)
BeautifulSoup(content, 'html.parser', name='ul',
attrs={'class': ['productLister gridView',
'categories shelf', 'categories aisles']})
3、即时保存,减少数据丢失
4、使用缓存中间件保存中间步骤获取的数据,获得更好的性能
5、本地缓存整个网站,缓存的基本思想是创建标识网站的密钥,我们使用它作为键,页面的内容就是值,根据URL创建一个哈希,哈希很短,如果您选择一个好的算法,您可以避免大量页面的冲突。我将使用hashlib.blake2b哈希函数,因为它比常用的哈希(例如MD5)更快,并且它与SHA-313一样安全。此外,该算法生成128个字符,这对于所有三个主导操作系统来说都足够短。

6、基于文件的缓存,将数据保存到文件。数据库缓存,将数据保存到关系数据库或非关系数据库
7、保存空间问题,数据量很大的话就要考虑节省保存空间,保存时压缩页面内容可以节省空间,读取时就需要解压缩,解压缩会增加一些计算时间,我们这里的策略是以时间换空间
8、更新缓存,确定缓存失效时间,超时后更新缓存
Website Scraping with Python 阅读笔记的更多相关文章
- Web Scraping with Python读书笔记及思考
Web Scraping with Python读书笔记 标签(空格分隔): web scraping ,python 做数据抓取一定一定要明确:抓取\解析数据不是目的,目的是对数据的利用 一般的数据 ...
- “编程小白学python”阅读笔记
今天在豆瓣搜索“python”关键字,搜到一本知乎周刊,读来觉得不错 编程小白学python ,作者@萧井陌, @Badger 书中提到的很多书,第一次看惊呆了,记录下来,希望每周回看此博文,坚持学习 ...
- 阅读OReilly.Web.Scraping.with.Python.2015.6笔记---Crawl
阅读OReilly.Web.Scraping.with.Python.2015.6笔记---Crawl 1.函数调用它自身,这样就形成了一个循环,一环套一环: from urllib.request ...
- 阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href
阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href 1.查找以<a>开头的所有文本,然后判断href是否在<a> ...
- 阅读OReilly.Web.Scraping.with.Python.2015.6笔记---BeautifulSoup---findAll
阅读OReilly.Web.Scraping.with.Python.2015.6笔记---BeautifulSoup---findAll 1..BeautifulSoup库的使用 Beautiful ...
- javascript高级程序设计阅读笔记(一)
javascript高级程序设计阅读笔记(一) 工作之余开发些web应用作为兴趣,在交互方面需要掌握javascript和css.HTML5等技术,因此读书笔记是必要的. javascript简介 J ...
- VS2013中Python学习笔记[Django Web的第一个网页]
前言 前面我简单介绍了Python的Hello World.看到有人问我搞搞Python的Web,一时兴起,就来试试看. 第一篇 VS2013中Python学习笔记[环境搭建] 简单介绍Python环 ...
- The Implementation of Lua 5.0 阅读笔记(一)
没想到Lua的作者理论水平这么高,这篇文章读的我顿生高屋建瓴之感.云风分享了一篇中译:http://www.codingnow.com/2000/download/The%20Implementati ...
- python 学习笔记整理
首先自我批评一下,说好的一天写一篇博客,结果不到两天,就没有坚持了,发现自己做什么事情都没有毅力啊!不能持之以恒.但是,这次一定要从写博客开始来改掉自己的一个坏习惯. 可是写博客又该写点什么呢? 反正 ...
随机推荐
- Spark SQL中的Catalyst 的工作机制
Spark SQL中的Catalyst 的工作机制 答:不管是SQL.Hive SQL还是DataFrame.Dataset触发Action Job的时候,都会经过解析变成unresolved的逻 ...
- spring是什么?
spring是什么? 1.编程范式的实践 dsl.注解.aop技术,扩展java语言的表达能力: dsl:xml配置+注解配置,扩展工程的组织能力: 2.基础组件: 常用组件的便捷封装,方便进行二次开 ...
- 严重: Exception sending context initialized event to listener instance of class org.springframework.web.context.ContextLoaderListener
十月 30, 2019 11:12:35 下午 org.apache.catalina.core.StandardContext listenerStart 严重: Exception sending ...
- 洛谷 P3243 [HNOI2015]菜肴制作 题解
每日一题 day60 打卡 Analysis 这道题一看就感觉是个拓扑排序,但因为按字典序最小的排序会有问题(见第三个样例)主要原因是每次选择有后效性,而从后往前就不会存在这个问题,因为每个子任务都是 ...
- Vue的SEO问题汇总
方式一 思否 https://segmentfault.com/q/1010000011824706 SSR 和 Nuxt.js : https://zh.nuxtjs.org/ https://se ...
- nginx return配置说明
该指令一般用于对请求的客户端直接返回响应状态码.在该作用域内return后面的所有nginx配置都是无效的. 可以使用在server.location以及if配置中. 除了支持跟状态码,还可以跟字符串 ...
- JQuery的Ajax标准写法
Ajax的标准写法 $.ajax({ url:"http://www.xxx",//请求的url地址 dataType:"json",//返回的格式为json ...
- python: isdigit int float 使用
>>> num1 = '2.0' >>> print num1.isdigit() False >>> num2 = ' >>> ...
- 图上的并行处理 Parallel Processing of Graphs
Graph 本次学术前沿讲座由邵斌老师主讲,标题已经揭示了主题:Graph.1.5h的talk,听完自觉意犹未尽.本来以为是一节自己没接触过的图形学的talk,没想到讲的很多内容都跟自己学过的很多东西 ...
- FZU Monthly-201906 tutorial
FZU Monthly-201906 tutorial 题目(难度递增) easy easy-medium medium medium-hard hard 思维难度 AE B DG CF H A. X ...