Website Scraping with Python 阅读笔记
第一章
工程涉及的基本工具:requests, beautiful soup, scrapy。
法规与技术约定:read the Terms & Conditions and the Privacy Policy of the website。让不让爬?
See the robots.txt file 。哪些可以爬?
website’s HTML code。目标网页涉及什么技术?
task and the website's structure.。该选什么工具?
Terms and Robots重点读:scraper/scraping
crawler/crawling
bot
spider
program
网页技术:使用python的builtwith库探查网页使用的技术
谷歌浏览器开发者工具:勘察网页
工具选择:small project(简单页面、没有涉及js的) Beautiful Soup + requests or use Scrapy。
有大量数据的,追求性能的 Scrapy + Beautiful Soup。
面对AJAX技术就要打电话摇人了,Selenium and Portia 出场。
第二章 输入请求
确定目标页面,查看目标页的robots.txt文件
对目标页面进行分析,确定找到目标信息的关键步骤
将整个爬取任务分解为几个步骤
整个网站就是一个树形图,域名为主干最终的页面即为叶子,叶子通过分支连接着域名
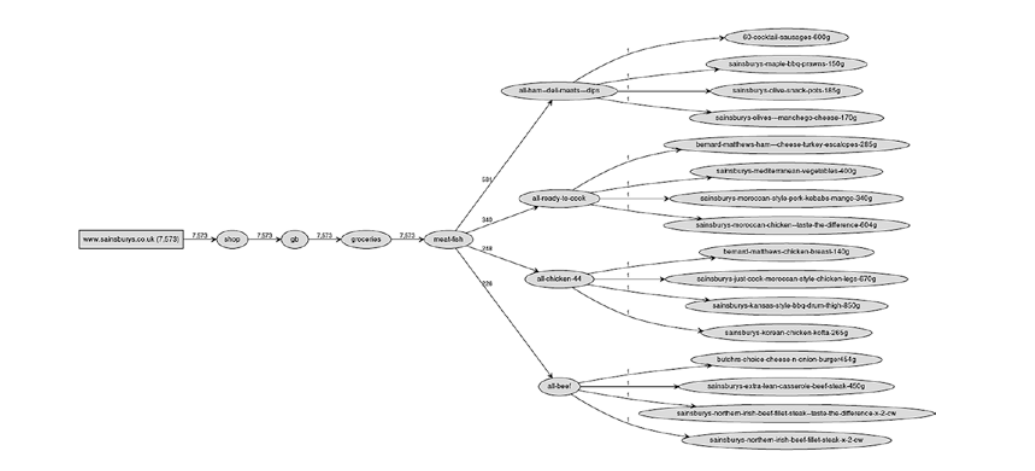
爬虫搜索页面就有了两种方法,一种是广度优先,层层递进式的搜索,另一种是深度优先,一条路走到头,回来再走下一条
第三章 使用BeautifulSoup
导入:from bs4 import BeautifulSoup
它用来解析html内容,提取目标信息
信息保存到csv,json文件
保存到关系数据库
保存到非关系数据库
改进: 1、使用不同的html解析器,html.parser(python自带), lxml(速度快), lxml-xml, html5lib(非常慢)
2、只解析需要的部分,使用SoupStrainer对象,例:
strainer = SoupStrainer(name='ul', attrs={'class':
'productLister gridView'})
soup = BeautifulSoup(content, 'html.parser', parse_only=strainer)
BeautifulSoup(content, 'html.parser', name='ul',
attrs={'class': ['productLister gridView',
'categories shelf', 'categories aisles']})
3、即时保存,减少数据丢失
4、使用缓存中间件保存中间步骤获取的数据,获得更好的性能
5、本地缓存整个网站,缓存的基本思想是创建标识网站的密钥,我们使用它作为键,页面的内容就是值,根据URL创建一个哈希,哈希很短,如果您选择一个好的算法,您可以避免大量页面的冲突。我将使用hashlib.blake2b哈希函数,因为它比常用的哈希(例如MD5)更快,并且它与SHA-313一样安全。此外,该算法生成128个字符,这对于所有三个主导操作系统来说都足够短。

6、基于文件的缓存,将数据保存到文件。数据库缓存,将数据保存到关系数据库或非关系数据库
7、保存空间问题,数据量很大的话就要考虑节省保存空间,保存时压缩页面内容可以节省空间,读取时就需要解压缩,解压缩会增加一些计算时间,我们这里的策略是以时间换空间
8、更新缓存,确定缓存失效时间,超时后更新缓存
Website Scraping with Python 阅读笔记的更多相关文章
- Web Scraping with Python读书笔记及思考
Web Scraping with Python读书笔记 标签(空格分隔): web scraping ,python 做数据抓取一定一定要明确:抓取\解析数据不是目的,目的是对数据的利用 一般的数据 ...
- “编程小白学python”阅读笔记
今天在豆瓣搜索“python”关键字,搜到一本知乎周刊,读来觉得不错 编程小白学python ,作者@萧井陌, @Badger 书中提到的很多书,第一次看惊呆了,记录下来,希望每周回看此博文,坚持学习 ...
- 阅读OReilly.Web.Scraping.with.Python.2015.6笔记---Crawl
阅读OReilly.Web.Scraping.with.Python.2015.6笔记---Crawl 1.函数调用它自身,这样就形成了一个循环,一环套一环: from urllib.request ...
- 阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href
阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href 1.查找以<a>开头的所有文本,然后判断href是否在<a> ...
- 阅读OReilly.Web.Scraping.with.Python.2015.6笔记---BeautifulSoup---findAll
阅读OReilly.Web.Scraping.with.Python.2015.6笔记---BeautifulSoup---findAll 1..BeautifulSoup库的使用 Beautiful ...
- javascript高级程序设计阅读笔记(一)
javascript高级程序设计阅读笔记(一) 工作之余开发些web应用作为兴趣,在交互方面需要掌握javascript和css.HTML5等技术,因此读书笔记是必要的. javascript简介 J ...
- VS2013中Python学习笔记[Django Web的第一个网页]
前言 前面我简单介绍了Python的Hello World.看到有人问我搞搞Python的Web,一时兴起,就来试试看. 第一篇 VS2013中Python学习笔记[环境搭建] 简单介绍Python环 ...
- The Implementation of Lua 5.0 阅读笔记(一)
没想到Lua的作者理论水平这么高,这篇文章读的我顿生高屋建瓴之感.云风分享了一篇中译:http://www.codingnow.com/2000/download/The%20Implementati ...
- python 学习笔记整理
首先自我批评一下,说好的一天写一篇博客,结果不到两天,就没有坚持了,发现自己做什么事情都没有毅力啊!不能持之以恒.但是,这次一定要从写博客开始来改掉自己的一个坏习惯. 可是写博客又该写点什么呢? 反正 ...
随机推荐
- Generative Adversarial Networks overview(2)
Libo1575899134@outlook.com Libo (原创文章,转发请注明作者) 本文章会先从Gan的简单应用示例讲起,从三个方面问题以及解决思路覆盖25篇GAN论文,第二个大部分会进一步 ...
- MongoDB Index
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录. 这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要 ...
- webpack资源管理
一.概况 ①webpack不仅可以打包JavaScript模块,甚至它把网页开发中的一切资源的都可以当作模块来打包处理 ②但是webpack本身不支持,它只是一个打包平台,其他资源,例如css.les ...
- Python 11 提取括号中间的内容
原文:https://blog.csdn.net/your_answer/article/details/80456550 import re string = 'abe(ac)ad)' p1 = r ...
- Git 管理篇(详细)
新建repository 本地目录下,在命令行里新建一个代码仓库(repository) 里面只有一个README.md 命令如下: touch README.md git init 初始化repos ...
- TCP三次握手的过程,accept发生在三次握手的哪一个阶段?
答案是:accept过程发生在三次握手之后,三次握手完成后,客户端和服务器就建立了tcp连接并可以进行数据交互了.这时可以调用accept函数获得此连接. TCP Accept总结 TCP Accep ...
- 【09NOIP提高组】Hankson 的趣味题(信息学奥赛一本通 1856)(洛谷 1072)
题目描述 Hanks 博士是BT (Bio-Tech,生物技术) 领域的知名专家,他的儿子名叫Hankson.现在,刚刚放学回家的Hankson 正在思考一个有趣的问题.今天在课堂上,老师讲解了如何求 ...
- centos7 出现“FirewallD is not running”
原因:没有开启防火墙 #提示没有开启防火墙服务,–permanent #永久生效,没有此参数重启后失效 [root@uJZ ~]# firewall-cmd --permanent --zone=/t ...
- node.js 自启动工具 supervisor
supervisor 会不停的watch 你应用下面的所有文件,发现有文件被修改,就重新载入程序文件这样就实现了部署,修 改了程序文件后马上就能看到变更后的结果.麻麻再也不用担心我的重启 nodejs ...
- Hash算法及java HashMap底层实现原理理解(含jdk 1.7以及jdk 1.8)
现在很多公司面试都喜欢问java的HashMap原理,特在此整理相关原理及实现,主要还是因为很多开发集合框架都不甚理解,更不要说各种其他数据结构了,所以造成面子造飞机,进去拧螺丝. 1.哈希表结构的优 ...