聊聊Lambda架构
定义
在数据分析场景中,我们可能会遇到这样的问题。例如,我们要做一个推荐系统,如果我们用批处理任务去做,一天或者一小时的推荐频次明显延迟太大。如果用流处理任务,虽然延迟的问题解决了,然而只用实时数据而没有历史数据,那么准确性就无法保证。因此需要结合批处理的历史数据和流处理的实时数据进行处理,既能保证准确性,又能保证实时性。再比如反作弊系统,实时识别作弊用户的时候同时需要用到用户的历史行为。
针对上述问题,Storm 的作者 Nathan Marz 提出了 Lambda 架构。根据维基百科的定义,Lambda 架构的设计是为了在处理大规模数据时,同时发挥流处理和批处理的优势。通过批处理提供全面、准确的数据,通过流处理提供低延迟的数据,从而达到平衡延迟、吞吐量和容错性的目的。为了满足下游的即席查询,批处理和流处理的结果会进行合并。
从上面定义可以看出,Lambda 架构包含三层,Batch Layer、Speed Layer 和 Serving Layer。架构图如下:
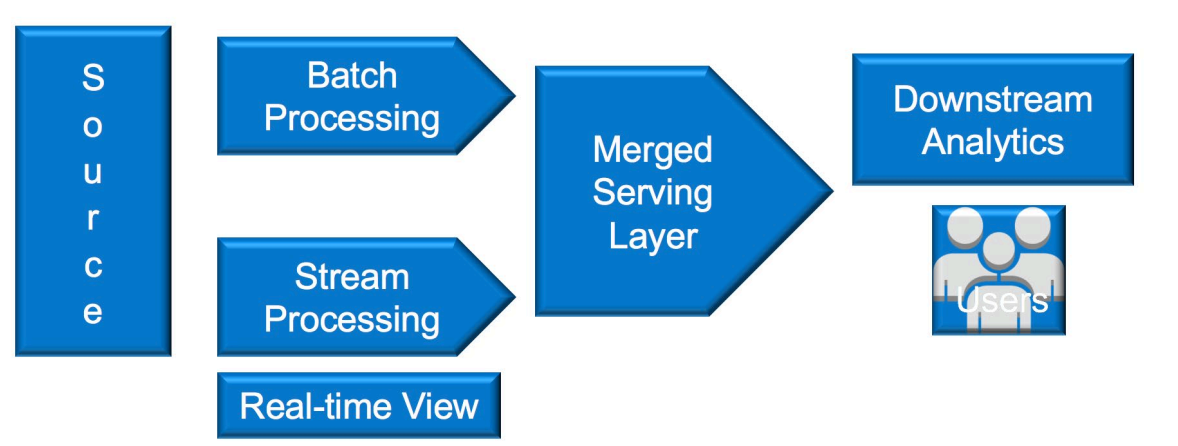
下面分别介绍这三层架构的作用。
- Batch Layer:批处理层,对离线的历史数据进行预计算,为了下游能够快速查询想要的结果。由于批处理基于完整的历史数据集,因此准确性可以得到保证。批处理层可以用 Hadoop、Spark 和 Flink 等框架计算
- Speed Layer:加速处理层,处理实时的增量数据,这一层重点在于低延迟。加速层的数据不如批处理层那样完整和准确,但是可以填补批处理高延迟导致的数据空白。加速层可以用 Storm、Spark streaming 和 Flink 等框架计算
- Serving Layer:合并层,计算历史数据和实时数据都有了, 合并层的工作自然就是将两者数据合并,输出到数据库或者其他介质,供下游分析。
Amazon AWS 的 Lambda 架构
这里,我将用 AWS 作为例子来介绍 Lambda 架构,AWS Lambda 架构图如下
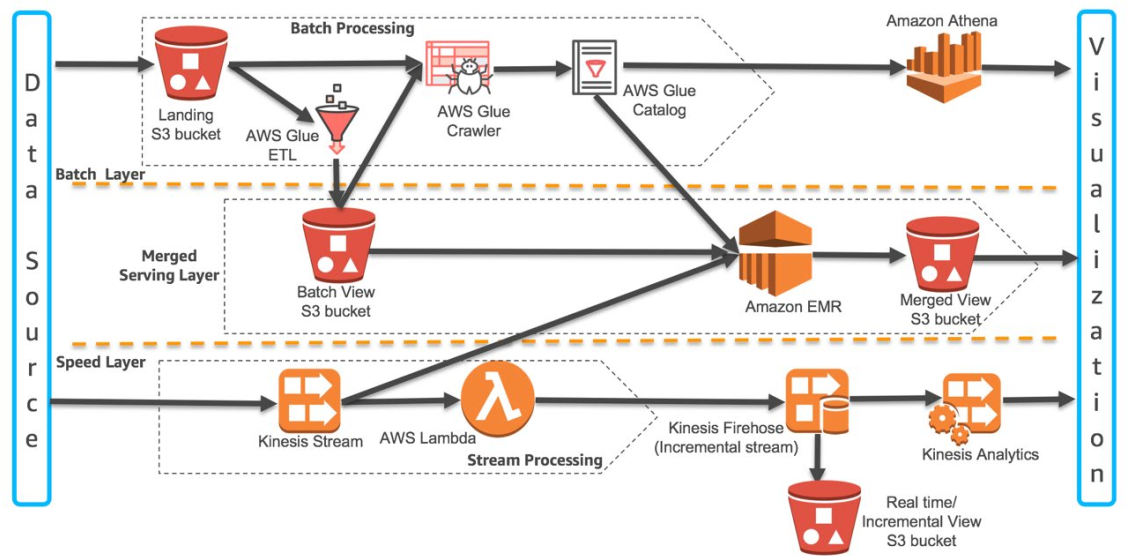
Batch Layer:使用 S3 bucket 从各种数据源收集数据,使用 AWS Glue 进行 ETL,输出到 Amazon S3。数据也可以输出到 Amazon Athena (交互式查询工具)
Speed Layer: 从上图看加速层有三个过程
- Kinesis Stream 从实时数据流中处理增量的数据,这部分数据数据输出到 Serving Layer 的 Amazon EMR,也可以输出到 Kinesis Firehose 对增量数据进行后续处理
- Kinesis Firehose 处理增量数据并写入 Amazone S3 中
- Kinesis Analytics 提供 SQL 的能力对增量的数据进行分析
其实只有上面第一个组件与我们今天讨论的 Lambda 架构有关,其他两个组件只是针对实时处理的。
Serving Layer:合并层使用基于 Amazon EMR 的 Spark SQL 来合并 Batch Layer 和 Speed Layer 的数据。批处理数据可以从 Amazon S3 加载批处理数据,实时数据可以从 Kinesis Stream 直接加载,合并的数据可以写到 Amazone S3。下面是一段合并数据代码

以上便是 Amazon AWS 实现 Lambda 架构的简单介绍。
我的经历
接下来分享下我之前的项目经历。其实,我们的项目跟上面的 Lambda 架构并不是特别贴合,但是我觉得思想是一致的。本质上都是批处理和流处理相关补充,同时发挥二者的优势。
我们的业务是处理用户的定位数据,最开始主要使用 Spark Streaming 进行增量处理,处理后的数据实时写入 MongoDB。数据读写以用户 id 为粒度,由于粒度比较细,因此每天的数据量比较大。前端如果查询时间跨度较大的数据,每次都需按照用户粒度数据做聚合,导致查询响应比较慢且容易影响实时写入。因此,我们用批处理任务对历史的离线数据进行预计算,再存储到 MongoDB。同时我们开发了基于 gRPC 实现的一套 Service 来充当 Serving Layer,将历史的数据与实时的数据合并返回给前端,避免前端直接连接数据库。在这个项目中我们的 Batch Layer 和 Speed Layer 都是用的 Spark 框架,因此维护相对容易。
之前介绍 Lambda 都是用加速层弥补批处理层的空白,但是上面的例子中是用批处理层弥补加速层的不足。因此,架构设计只是一个思想,具体的实施还是要根据业务进行灵活变通,不能生搬硬套。
小结
本篇文章简单介绍了 Lambda 架构的内容,同时介绍了 Amazon AWS 实现 Lambda 架构的例子。最后举了一个我自己项目中的一个例子。经过整篇内容我们了解了 Lambda 架构的优势,但是它有没有缺点呢。显然也是有的,我能想到的有以下几点:
- 批处理层、加速层和合并层用到的框架可能不一样,因此会增加了开发的成本
- 批处理层和加速层处理的结果有可能不一致,如果用户看到的数据会变,这个体验不太好
- 如果某一层的逻辑变了,是不是其他两层或者一层的逻辑也要跟着变,因此层与层处理逻辑耦合度较大
你还能想到其他的问题吗, 以及有没有更好的架构能解决这个问题?欢迎交流
欢迎关注公众号「渡码」

聊聊Lambda架构的更多相关文章
- 大数据Lambda架构
1 Lambda架构介绍 Lambda架构划分为三层.各自是批处理层,服务层,和加速层.终于实现的效果,能够使用以下的表达式来说明. query = function(alldata) 1.1 批处理 ...
- 大数据平台Lambda架构详解
Lambda架构由Storm的作者Nathan Marz提出.旨在设计出一个能满足.实时大数据系统关键特性的架构,具有高容错.低延时和可扩展等特. Lambda架构整合离线计算和实时计算,融合不可变( ...
- Others-大数据平台Lambda架构浅析(全量计算+增量计算)
大数据平台Lambda架构浅析(全量计算+增量计算) 2016年12月23日 22:50:53 scuter_victor 阅读数:1642 标签: spark大数据lambda 更多 个人分类: 造 ...
- Lambda架构
转载:https://blog.csdn.net/brucesea/article/details/45937875 1.Lambda架构背景介绍 Lambda架构是由Storm的作者Nathan M ...
- 【大数据】大数据处理-Lambda架构-Kappa架构
大数据处理-Lambda架构-Kappa架构 elasticsearch-head Elasticsearch-sql client NLPchina/elasticsearch-sql: Use S ...
- lambda架构简介
1.Lambda架构背景介绍 Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理框架.Marz在Twitter工作期间开发了著名的实时大数据处理框架Storm,Lamb ...
- 带有Apache Spark的Lambda架构
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 目标 市场上的许多玩家已经建立了成功的MapReduce工作流程来每天处理以TB计的历史数据.但是谁愿意等待24小时才能获得最新的分析结果? ...
- 大数据处理中的Lambda架构和Kappa架构
首先我们来看一个典型的互联网大数据平台的架构,如下图所示: 在这张架构图中,大数据平台里面向用户的在线业务处理组件用褐色标示出来,这部分是属于互联网在线应用的部分,其他蓝色的部分属于大数据相关组件,使 ...
- 深入理解大数据架构之——Lambda架构
目录 传统系统的问题 Lambda架构简介 Lambda架构关键特性 数据系统的本质 Lambda的三层架构 Lambda架构组件选型 总结 原文链接:https://jiang-hao.com/ar ...
随机推荐
- 【已解决】git怎么合并多个分支到主干master
git支持很多种工作流程,我们采用的一般是这样,远程创建一个主分支,本地每人创建功能分支,日常工作流程如下: 去自己的工作分支$ git checkout workbranch 工作.... 提交工作 ...
- JDBC及C3P0常用类
JDBC(Java Database Connectivity)JAVA数据库连接,它是一套用于执行SQL语句的Java API.JDBC可以通过不同驱动与不同数据库连接,相当于JAVA和数据库之间的 ...
- GCN 简单numpy实现
`#参考:https://blog.csdn.net/weixin_42052081/article/details/89108966 import numpy as np import networ ...
- JavaScript实现的图片循环播放
直接上干货 <html> <head> <title>Banner Cycler</title> <script> var banners ...
- 07.进程管理+作业控制+文件查找与压缩+文件压缩与打包+tar打包解包+NFS
进程管理 程序放在磁盘上叫文件,把它复制到内存,并在cpu运行,就叫进程, 进程多少也反映当前运行程序的多少 进程在系统中会为每个进程生成一个进程号,在所有的进程中有一个特殊进程即init进程, 它是 ...
- R 基于朴素贝叶斯模型实现手机垃圾短信过滤
# 读取数数据, 查看数据结构 df_raw <- read.csv("sms_spam.csv", stringsAsFactors=F) str(df_raw) leng ...
- jmeter压测学习7-登录参数化(CSV 数据文件设置)
前言 我们在压测登录接口的时候,如果只用一个账号去设置并发压测,这样的结果很显然是不合理的,一个用户并发无法模拟真实的情况. 如果要压测登录接口,肯定得准备几百,甚至上千的账号去登录,测试的结果才具有 ...
- 桌面图标管理工具-Rolan(网上收集,仅供学习与研究,支持正版)
Rolan 是一个轻量级启动器,“你可以通过将文件拖到软件窗口中,然后通过像 QQ 一样的吸附或者键盘热键随时呼出,点击图标即可启动,使用起来非常方便快捷! 官网:https://getrolan.c ...
- zz——Recent Advances on Object Detection in MSRA
本文由DataFun社区根据微软亚洲研究院视觉组Lead Researcher Jifeng Dai老师在2018 AI先行者大会中分享的<Recent Advances on Object D ...
- CF932F Escape Through Leaf(DP,斜率优化)
SB 题. 写出 DP 方程:\(f_i\) 表示从 \(i\) 跳的最小值. \(i\) 是叶子就是 \(0\),否则就是选个子树中的 \(v\),\(f_i=\min(f_v+a_ib_v)\). ...