容错(Fault-tolerance)
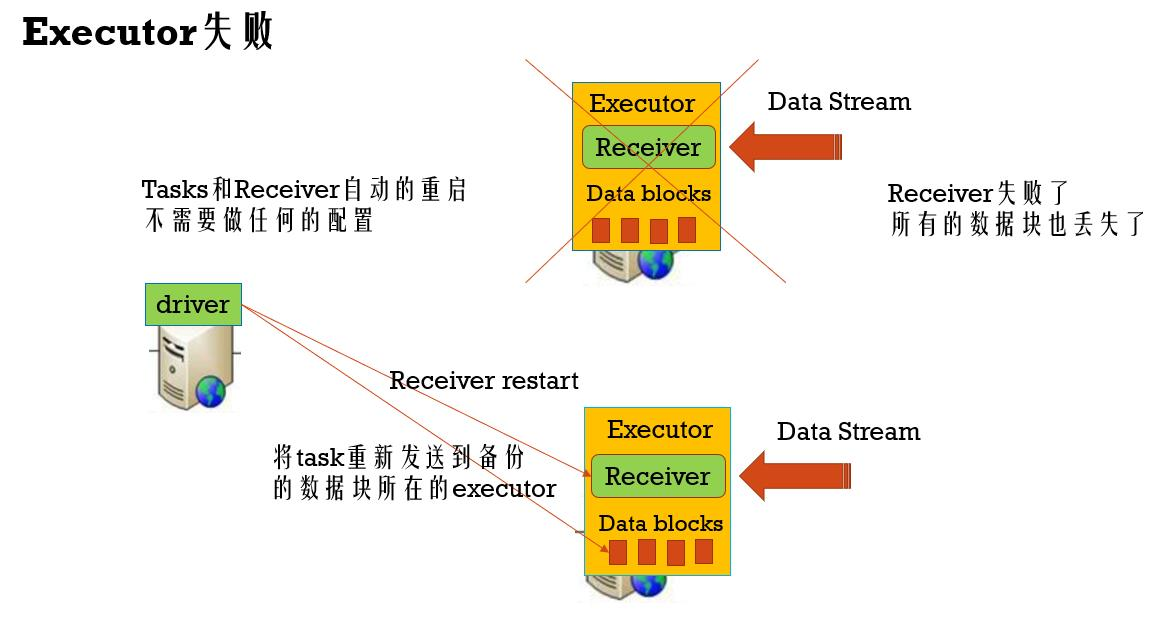
Executor失败容错

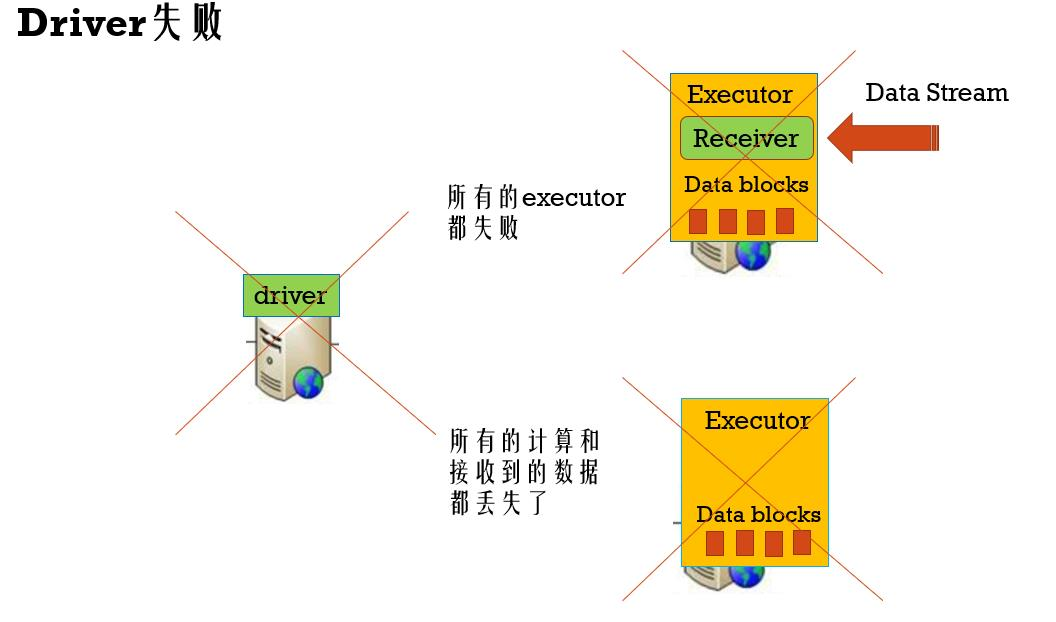
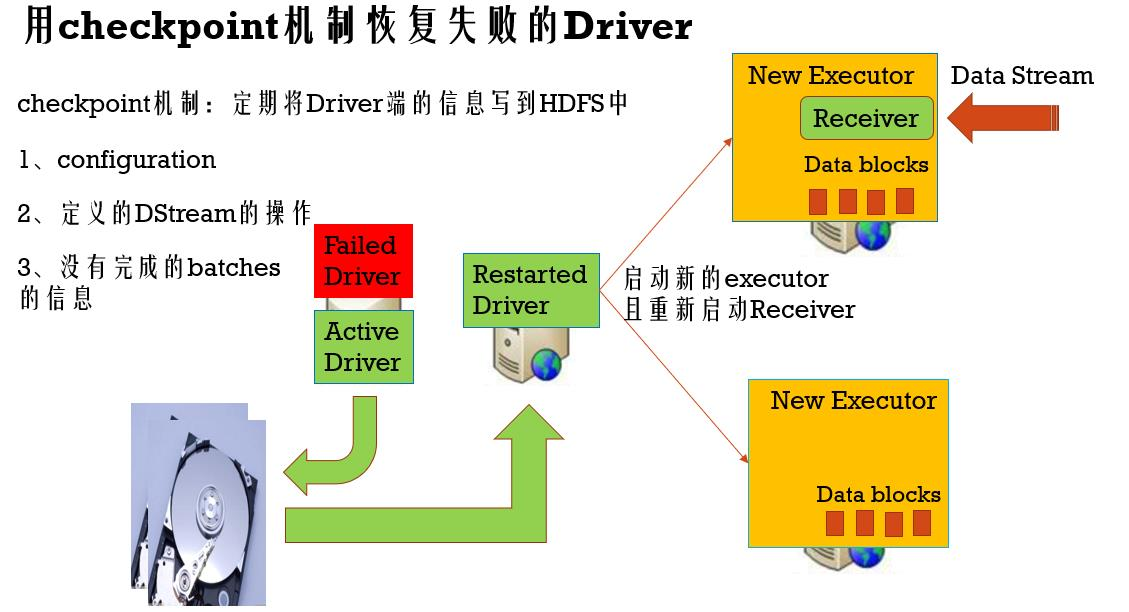
Driver失败容错
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext} /**
* WordCount程序,Spark Streaming消费TCP Server发过来的实时数据的例子:
*
* 1、在master服务器上启动一个Netcat server
* `$ nc -lk 9998` (如果nc命令无效的话,我们可以用yum install -y nc来安装nc)
*
* 2、用下面的命令在在集群中将Spark Streaming应用跑起来
* spark-submit --class com.twq.wordcount.JavaNetworkWordCount \
* --master spark://master:7077 \
* --deploy-mode cluster \
* --driver-memory 512m \
* --executor-memory 512m \
* --total-executor-cores 4 \
* --executor-cores 2 \
* /home/hadoop-twq/spark-course/streaming/spark-streaming-basic-1.0-SNAPSHOT.jar
*/
object NetworkWordCount {
def main(args: Array[String]) { val checkpointDirectory = "hdfs://master:9999/user/hadoop-twq/spark-course/streaming/chechpoint" def functionToCreateContext(): StreamingContext = {
val sparkConf = new SparkConf()
.setAppName("NetworkWordCount")
val sc = new SparkContext(sparkConf) // Create the context with a 1 second batch size
val ssc = new StreamingContext(sc, Seconds(1)) //创建一个接收器(ReceiverInputDStream),这个接收器接收一台机器上的某个端口通过socket发送过来的数据并处理
val lines = ssc.socketTextStream("master", 9998, StorageLevel.MEMORY_AND_DISK_SER_2)// 提高数据块的高可用性,备份两份,但会占用一定的内存 //处理的逻辑,就是简单的进行word count
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) //将结果输出到控制台
wordCounts.print()
ssc.checkpoint(checkpointDirectory)
ssc
}
// 代码
val ssc = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _) //启动Streaming处理流
ssc.start() //等待Streaming程序终止
ssc.awaitTermination()
}
}
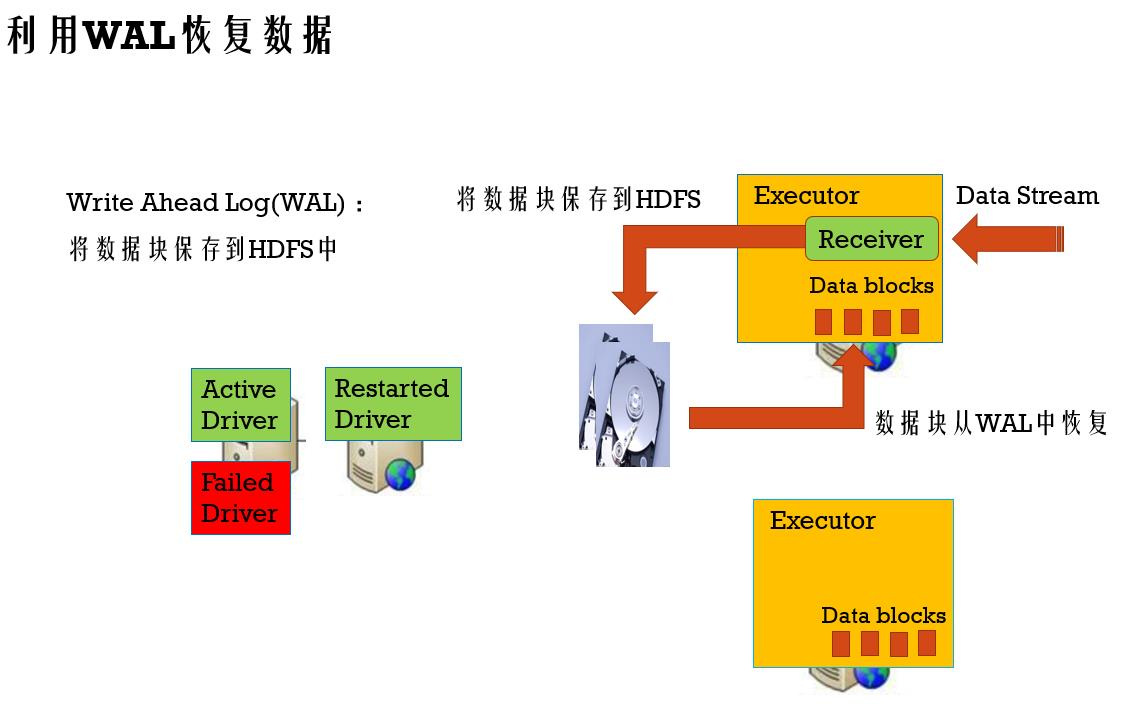
接收到的数据丢失的容错
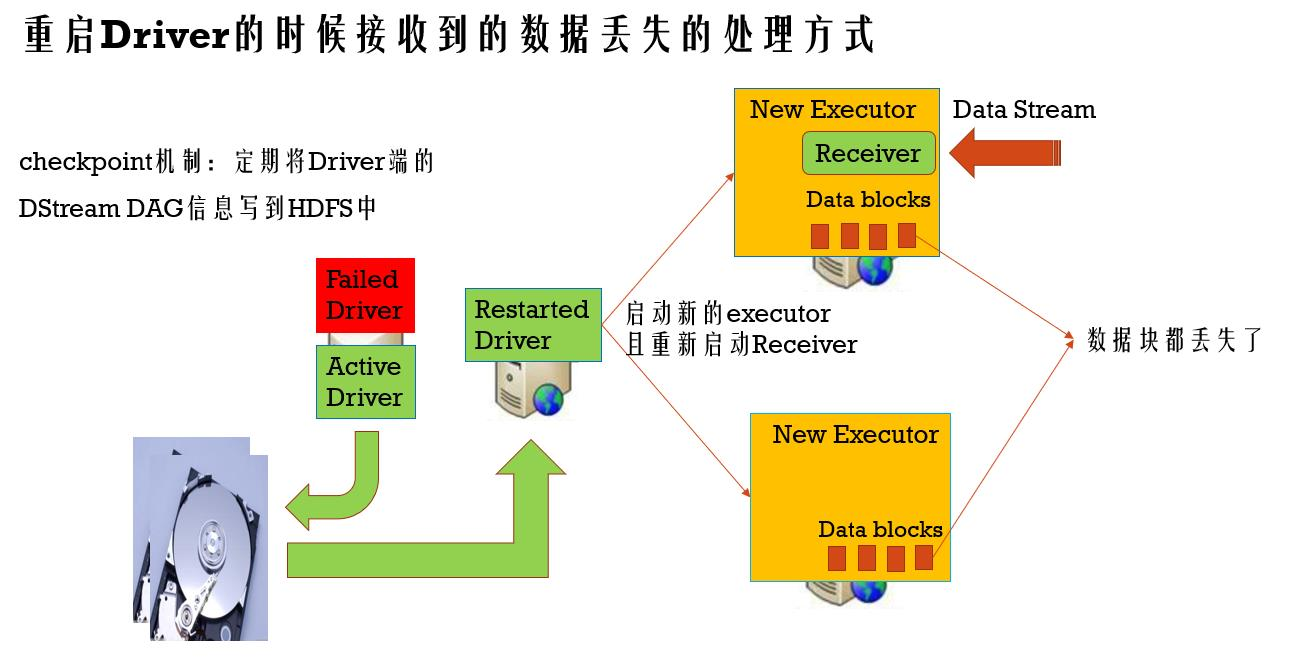
checkpoint机制:定期将Driver端的DStream DAG信息写到HDFS中(写内存和写磁盘同时进行)

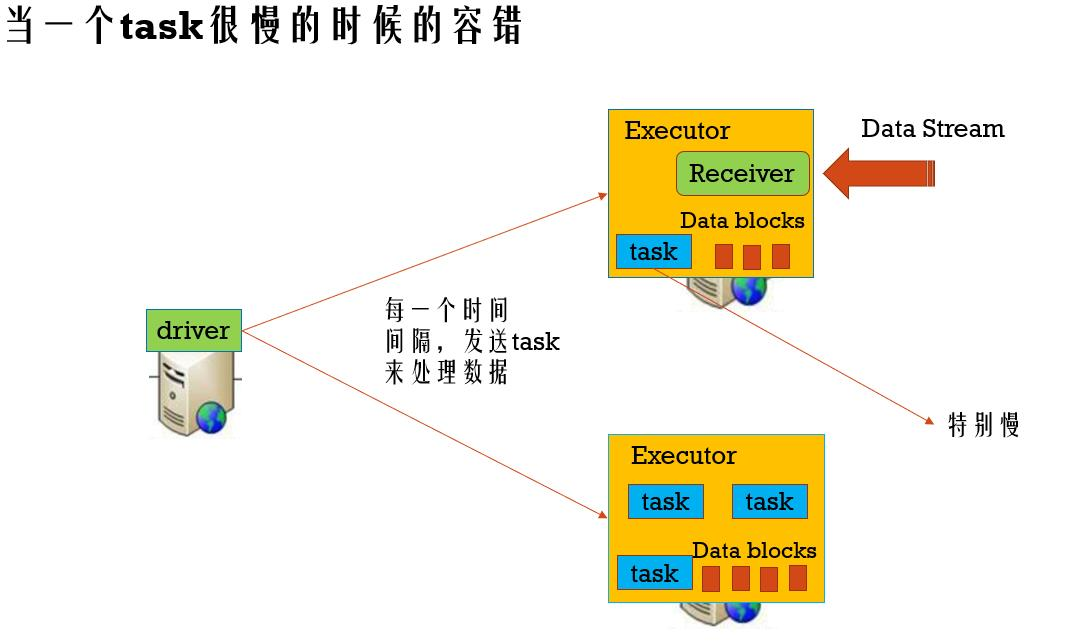
当一个task很慢的容错

容错(Fault-tolerance)的更多相关文章
- Flink Program Guide (7) -- 容错 Fault Tolerance(DataStream API编程指导 -- For Java)
false false false false EN-US ZH-CN X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-n ...
- Fault Tolerance —— Storm的故障容错性
——本文讲解了Storm故障容忍性(Fault-Tolerance)的设计细节:当Worker.节点.Nimbus或者Supervisor出现故障时是如何实现故障容忍性,以及Nimbus是否存在单点 ...
- Flink Program Guide (9) -- StateBackend : Fault Tolerance(Basic API Concepts -- For Java)
State Backends 本文翻译自文档Streaming Guide / Fault Tolerance / StateBackend ----------------------------- ...
- VMware vSphere服务器虚拟化实验十一高可用性之三Fault Tolerance
VMware vSphere服务器虚拟化实验十一高可用性之三Fault Tole ...
- VMware Fault Tolerance 概述及功能
VMware Fault Tolerance - 为您的应用程序提供全天候可用性 通过为虚拟机启用 VMware Fault Tolerance,最大限度地延长数据中心的正常运行时间,减少停机管理成本 ...
- Flink Program Guide (8) -- Working with State :Fault Tolerance(DataStream API编程指导 -- For Java)
Working with State 本文翻译自Streaming Guide/ Fault Tolerance / Working with State ---------------------- ...
- Storm系列之三——Fault Tolerance
本文介绍Storm容错的设计细节. 1.当一个worker进程死了会发生什么? 当worker死了,supervisor会重启它.如果它尝试开启多次失败并且不能与nimbus发送心跳,Nimbus会重 ...
- Storm介绍(二)
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文是Storm系列之一,主要介绍Storm的架构设计,推荐读者在阅读 ...
- JSP之WEB服务器:Apache与Tomcat的区别 ,几种常见的web/应用服务器
注意:此为2009年的blog,注意时效性(针对常见服务器) APACHE是一个web服务器环境程序 启用他可以作为web服务器使用 不过只支持静态网页 如(asp,php,cgi,jsp)等 ...
- WEB服务器、应用程序服务器、HTTP服务器区别
很清晰的解释了WEB服务器.应用程序服务器.HTTP服务器区别 转载自 http://www.cnblogs.com/zhaoyl/archive/2012/10/10/2718575.html WE ...
随机推荐
- linux中安装python3.7
linux中安装python3.7 1. 安装依赖包 yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite- ...
- dubbo 使用、原理、接口请求,都经历了什么过程
[dubbo官网文档]http://dubbo.apache.org/zh-cn/docs/user/quick-start.html
- LeetCode 537. 复数乘法(Complex Number Multiplication)
537. 复数乘法 537. Complex Number Multiplication 题目描述 Given two strings representing two complex numbers ...
- [转帖]Linux教程(21)-Linux条件循环语句
Linux教程(21)-Linux条件循环语句 2018-08-24 16:49:03 钱婷婷 阅读数 60更多 分类专栏: Linux教程与操作 Linux教程与使用 版权声明:本文为博主原创文 ...
- Linux下的JMeter部署及使用
之前都是在windows环境使用JMeter,是有操作界面的.但是最近需要在Linux环境下使用,现将操作步骤记录下来 在安装JMeter之前,需要在Linux下安装JDK并配置环境变量,这里跳过 1 ...
- python学习-66 面向对象3 - 多态
多态 1.什么是多态 由不同的类实例化得到的对象,调用同一个方法,执行的逻辑不同. 举例: class H2O: def __init__(self,type,tem): self.type = ty ...
- xorm - Update,乐观锁,更新时间updated,NoAutoTime()
更新数据使用Update方法 Update方法的第一个参数为需要更新的内容,可以为一个结构体指针或者一个Map[string]interface{}类型. 当传入的为结构体指针时,只有非nil和非0的 ...
- git学习笔记 ---删除文件
在Git中,删除也是一个修改操作,我们实战一下,先添加一个新文件test.txt到Git并且提交: $ git add test.txt $ git commit -m "add test. ...
- Java 环境
1. Java 环境1999年发布第二代java平台 简称 Java2 标准版 Standard Edition J2SE 企业版 Enterprise Edition J2EE 微型版 Micro ...
- wstngfw中使用虚拟IP映射内网IP
wstngfw中使用虚拟IP映射内网IP -------------------------------- Server01: IP: 192.168.195.73/24 GW: 192.168.19 ...