Python机器学习--手写体识别(KNN+MLP)





MLP实现


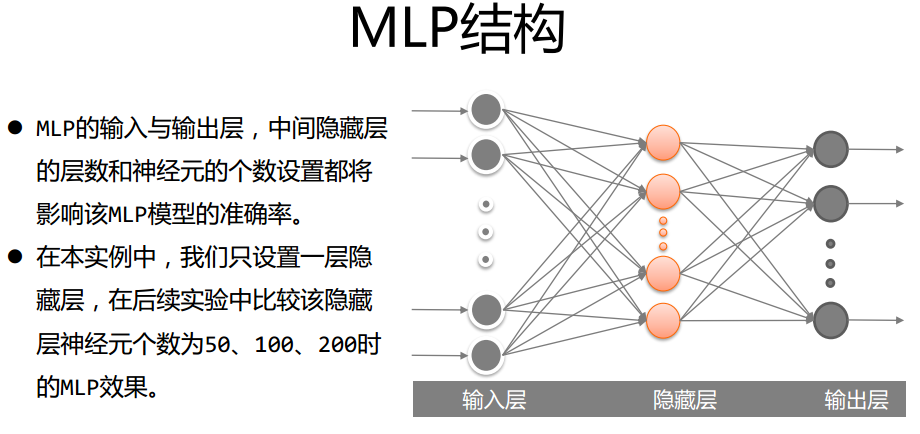

- 调整参数比较性能结果
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 30 21:14:38 2017 @author: Administrator
""" import numpy as np #导入numpy工具包
from os import listdir #使用listdir模块,用于访问本地文件
from sklearn.neural_network import MLPClassifier ## 版本选择sklearn-v0.18;sklearn更新anaconda方法:conda update scikit-learn #定义img2vector函数,将加载的32*32的图片矩阵展开成一列向量
def img2vector(fileName):
retMat = np.zeros([1024],int) #定义返回的矩阵,大小为1*1024
fr = open(fileName) #打开包含32*32大小的数字文件
lines = fr.readlines() #读取文件的所有行
for i in range(32): #遍历文件所有行
for j in range(32): #并将01数字存放在retMat中
retMat[i*32+j] = lines[i][j]
return retMat #定义加载训练数据的函数readDataSet,并将样本标签转化为one-hot向量
def readDataSet(path):
fileList = listdir(path) #获取文件夹下的所有文件
numFiles = len(fileList) #统计需要读取的文件的数目
dataSet = np.zeros([numFiles,1024],int) #用于存放所有的数字文件
hwLabels = np.zeros([numFiles,10]) #用于存放对应的one-hot标签
for i in range(numFiles): #遍历所有的文件
filePath = fileList[i] #获取文件名称/路径
digit = int(filePath.split('_')[0]) #通过文件名获取标签
hwLabels[i][digit] = 1.0 #将对应的one-hot标签置1
dataSet[i] = img2vector(path +'/'+filePath) #读取文件内容
return dataSet,hwLabels #read dataSet
fpath='F:\RANJIEWEN\MachineLearning\Python机器学习实战_mooc\data\手写数字\digits\\'
train_dataSet, train_hwLabels = readDataSet(fpath+'trainingDigits') # 调整参数,隐藏层数量,学习率,最大迭代次数比较性能结果
clf = MLPClassifier(hidden_layer_sizes=(100,),
activation='logistic', solver='adam',
learning_rate_init = 0.00001, max_iter=2000)
print(clf)
clf.fit(train_dataSet,train_hwLabels) #read testing dataSet
dataSet,hwLabels = readDataSet(fpath+'testDigits')
res = clf.predict(dataSet) #对测试集进行预测
error_num = 0 #统计预测错误的数目
num = len(dataSet) #测试集的数目
for i in range(num): #遍历预测结果
#比较长度为10的数组,返回包含01的数组,0为不同,1为相同
#若预测结果与真实结果相同,则10个数字全为1,否则不全为1
if np.sum(res[i] == hwLabels[i]) < 10:
error_num += 1
print("Total num:",num," Wrong num:", \
error_num," WrongRate:",error_num / float(num))
- kNN比较
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 31 10:11:15 2017 @author: Administrator knn-neighbors
""" import numpy as np #导入numpy工具包
from os import listdir #使用listdir模块,用于访问本地文件
from sklearn import neighbors #定义img2vector函数,将加载的32*32的图片矩阵展开成一列向量
def img2vector(fileName):
retMat = np.zeros([1024],int) #定义返回的矩阵,大小为1*1024
fr = open(fileName) #打开包含32*32大小的数字文件
lines = fr.readlines() #读取文件的所有行
for i in range(32): #遍历文件所有行
for j in range(32): #并将01数字存放在retMat中
retMat[i*32+j] = lines[i][j]
return retMat #定义加载训练数据的函数readDataSet,并将样本标签转化为one-hot向量
def readDataSet(path):
fileList = listdir(path) #获取文件夹下的所有文件
numFiles = len(fileList) #统计需要读取的文件的数目
dataSet = np.zeros([numFiles,1024],int) #用于存放所有的数字文件
hwLabels = np.zeros([numFiles])#用于存放对应的标签(与神经网络的不同)
for i in range(numFiles): #遍历所有的文件
filePath = fileList[i] #获取文件名称/路径
digit = int(filePath.split('_')[0]) #通过文件名获取标签
hwLabels[i] = digit #直接存放数字,并非one-hot向量
dataSet[i] = img2vector(path +'/'+filePath) #读取文件内容
return dataSet,hwLabels #read dataSet
fpath='F:\RANJIEWEN\MachineLearning\Python机器学习实战_mooc\data\手写数字\digits\\' train_dataSet, train_hwLabels = readDataSet(fpath+'trainingDigits')
knn = neighbors.KNeighborsClassifier(algorithm='kd_tree', n_neighbors=3)
knn.fit(train_dataSet, train_hwLabels) #read testing dataSet
dataSet,hwLabels = readDataSet(fpath+'testDigits') res = knn.predict(dataSet) #对测试集进行预测
error_num = np.sum(res != hwLabels) #统计分类错误的数目
num = len(dataSet) #测试集的数目
print("Total num:",num," Wrong num:", \
error_num," WrongRate:",error_num / float(num))
Python机器学习--手写体识别(KNN+MLP)的更多相关文章
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- python机器学习一:KNN算法实现
所谓的KNN算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个 ...
- 使用KNN算法手写体识别
#!/usr/bin/python #coding:utf-8 import numpy as np import operator import matplotlib import matplotl ...
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- Python机器学习基础教程-第1章-鸢尾花的例子KNN
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- SUSE Linux Enterprise 11 离线安装 DLIB 人脸识别 python机器学习模块
python机器学习模块安装 我的博客:http://www.cnblogs.com/wglIT/p/7525046.html 环境:SUSE Linux Enterprise 11 sp4 离线安 ...
- [Python] 机器学习库资料汇总
声明:以下内容转载自平行宇宙. Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy.其中Numpy是一个用python实现的科学计算包.包括: 一个强大的N维数组对象Array: ...
- [resource]Python机器学习库
reference: http://qxde01.blog.163.com/blog/static/67335744201368101922991/ Python在科学计算领域,有两个重要的扩展模块: ...
- python机器学习实战(一)
python机器学习实战(一) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7140974.html 前言 这篇notebook是关于机器 ...
随机推荐
- PHP 把字符转换为 HTML 实体 - htmlentities() 函数
定义和用法 htmlentities() 函数把字符转换为 HTML 实体. 语法 htmlentities(string,quotestyle,character-set) 参数 描述 string ...
- Java学习经验
随着Java学习的深入,越来越感觉记笔记的重要性,一方面可以使自己更加善于总结,提高对项目和自己的认知,另一方面可以让知识条例更加鲜明,并且加深对知识点的记忆.Java是一门很早开始兴起的语言,用途非 ...
- docker系列之网络配置
docker 网络配置 docker 安装后, 会自动在系统做一个网桥配置 docker0 . 其容器都会分配到此网桥配置下的独立, 私有 IP 地址. 如果你要自己配置桥接, 也可以把 docker ...
- SpringSecurity结合数据库表实现权限认证
SpringSecurity结合数据表实现权限认证: 下面的案例是在SpringBoot框架实现的: 步骤一:准备数据库表 以下是五张表的脚本 ### 用户表 create table Sys_Use ...
- java的synchronized可重入锁
在java内部,同一线程在调用自己类中其他synchronized方法/块或调用父类的synchronized方法/块都不会阻碍该线程的执行,就是说同一线程对同一个对象锁是可重入的,而且同一个线程可以 ...
- C#读写Excel表格文件NPOI方式无需安装office .xls后缀没问题
/// <summary> /// 读Excel /// </summary> /// <param name="fileName"></ ...
- django 常见过滤器
一.形式:小写 {{ name | lower }} 二.过滤器是可以嵌套的,字符串经过三个过滤器,第一个过滤器转换为小写,第二个过滤器输出首字母,第三个过滤器将首字母转换成大写 标签 {{ st ...
- 解决手机助手与 android sdk 的adb 冲突问题
现象:手机助手与 sdk 内的 adb冲突,用助手与真机连接后,sdk adb 就被干掉了 突发奇想: 突然有一天想到用助手的adb来覆盖sdk内的adb,果然奏效.现在eclipse.助手.cmd窗 ...
- Leetcode 397.整数替换
整数替换 给定一个正整数 n,你可以做如下操作: 1. 如果 n 是偶数,则用 n / 2替换 n.2. 如果 n 是奇数,则可以用 n + 1或n - 1替换 n.n 变为 1 所需的最小替换次数是 ...
- Leetcode 400.第n个数
第n个数 在无限的整数序列 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ...中找到第 n 个数字. 为整形范围内 ( n < 231). 示例 1: 输入: 3 输出 ...