【Apache Kafka】一、Kafka简介及其基本原理
对于大数据,我们要考虑的问题有很多,首先海量数据如何收集(如Flume),然后对于收集到的数据如何存储(典型的分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库Redis),其次存储的数据不是存起来就没事了,要通过计算从中获取有用的信息,这就涉及到计算模型(典型的离线计算MapReduce、流式实时计算Storm、Spark),或者要从数据中挖掘信息,还需要相应的机器学习算法。在这些之上,还有一些各种各样的查询分析数据的工具(如Hive、Pig等)。除此之外,要构建分布式应用还需要一些工具,比如分布式协调服务Zookeeper等等。
这里,我们讲到的是消息系统,Kafka专为分布式高吞吐量系统而设计,其他消息传递系统相比,Kafka具有更好的吞吐量,内置分区,复制和固有的容错能力,这使得它非常适合大规模消息处理应用程序。
(一)消息系统
首先,我们理解一下什么是消息系统:消息系统负责将数据从一个应用程序传输到另外一个应用程序,使得应用程序可以专注于处理逻辑,而不用过多的考虑如何将消息共享出去。
分布式消息系统基于可靠消息队列的方式,消息在应用程序和消息系统之间异步排队。实际上,消息系统有两种消息传递模式:一种是点对点,另外一种是基于发布-订阅(publish-subscribe)的消息系统。
1、点对点的消息系统
在点对点的消息系统中,消息保留在队列中,一个或者多个消费者可以消耗队列中的消息,但是消息最多只能被一个消费者消费,一旦有一个消费者将其消费掉,消息就从该队列中消失。这里要注意:多个消费者可以同时工作,但是最终能拿到该消息的只有其中一个。最典型的例子就是订单处理系统,多个订单处理器可以同时工作,但是对于一个特定的订单,只有其中一个订单处理器可以拿到该订单进行处理。

2、发布-订阅消息系统
在发布 - 订阅系统中,消息被保留在主题中。 与点对点系统不同,消费者可以订阅一个或多个主题并使用该主题中的所有消息。在发布 - 订阅系统中,消息生产者称为发布者,消息使用者称为订阅者。 一个现实生活的例子是Dish电视,它发布不同的渠道,如运动,电影,音乐等,任何人都可以订阅自己的频道集,并获得他们订阅的频道时可用。

(二)Apache Kafka简介
Kafka is a distributed,partitioned,replicated commit logservice。
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使你能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
Kafka 是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
关键术语:
(1)生产者和消费者(producer和consumer):消息的发送者叫Producer,消息的使用者和接受者是Consumer,生产者将数据保存到Kafka集群中,消费者从中获取消息进行业务的处理。

(2)broker:Kafka集群中有很多台Server,其中每一台Server都可以存储消息,将每一台Server称为一个kafka实例,也叫做broker。
(3)主题(topic):一个topic里保存的是同一类消息,相当于对消息的分类,每个producer将消息发送到kafka中,都需要指明要存的topic是哪个,也就是指明这个消息属于哪一类。
(4)分区(partition):每个topic都可以分成多个partition,每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部。为什么要进行分区呢?最根本的原因就是:kafka基于文件进行存储,当文件内容大到一定程度时,很容易达到单个磁盘的上限,因此,采用分区的办法,一个分区对应一个文件,这样就可以将数据分别存储到不同的server上去,另外这样做也可以负载均衡,容纳更多的消费者。
(5)偏移量(Offset):一个分区对应一个磁盘上的文件,而消息在文件中的位置就称为offset(偏移量),offset为一个long型数字,它可以唯一标记一条消息。由于kafka并没有提供其他额外的索引机制来存储offset,文件只能顺序的读写,所以在kafka中几乎不允许对消息进行“随机读写”。
综上,我们总结一下Kafka的几个要点:
- kafka是一个基于发布-订阅的分布式消息系统(消息队列)
- Kafka面向大数据,消息保存在主题中,而每个topic有分为多个分区
- kafak的消息数据保存在磁盘,每个partition对应磁盘上的一个文件,消息写入就是简单的文件追加,文件可以在集群内复制备份以防丢失
- 即使消息被消费,kafka也不会立即删除该消息,可以通过配置使得过一段时间后自动删除以释放磁盘空间
- kafka依赖分布式协调服务Zookeeper,适合离线/在线信息的消费,与storm和saprk等实时流式数据分析常常结合使用
(三)Apache Kafka基本原理
通过之前的介绍,我们对kafka有了一个简单的理解,它的设计初衷是建立一个统一的信息收集平台,使其可以做到对信息的实时反馈。Kafka is a distributed,partitioned,replicated commit logservice。接下来我们着重从几个方面分析其基本原理。
1、分布式和分区(distributed、partitioned)
我们说kafka是一个分布式消息系统,所谓的分布式,实际上我们已经大致了解。消息保存在Topic中,而为了能够实现大数据的存储,一个topic划分为多个分区,每个分区对应一个文件,可以分别存储到不同的机器上,以实现分布式的集群存储。另外,每个partition可以有一定的副本,备份到多台机器上,以提高可用性。
总结起来就是:一个topic对应的多个partition分散存储到集群中的多个broker上,存储方式是一个partition对应一个文件,每个broker负责存储在自己机器上的partition中的消息读写。
2、副本(replicated )
kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性,备份的数量可以通过配置文件指定。
这种冗余备份的方式在分布式系统中是很常见的,那么既然有副本,就涉及到对同一个文件的多个备份如何进行管理和调度。kafka采取的方案是:每个partition选举一个server作为“leader”,由leader负责所有对该分区的读写,其他server作为follower只需要简单的与leader同步,保持跟进即可。如果原来的leader失效,会重新选举由其他的follower来成为新的leader。
至于如何选取leader,实际上如果我们了解ZooKeeper,就会发现其实这正是Zookeeper所擅长的,Kafka 使用 ZK 在 Broker 中选出一个 Controller,用于 Partition 分配和 Leader 选举。
另外,这里我们可以看到,实际上作为leader的server承担了该分区所有的读写请求,因此其压力是比较大的,从整体考虑,从多少个partition就意味着会有多少个leader,kafka会将leader分散到不同的broker上,确保整体的负载均衡。
3、整体数据流程
Kafka 的总体数据流满足下图,该图可以说是概括了整个kafka的基本原理。

(1)数据生产过程(Produce)
对于生产者要写入的一条记录,可以指定四个参数:分别是topic、partition、key和value,其中topic和value(要写入的数据)是必须要指定的,而key和partition是可选的。
对于一条记录,先对其进行序列化,然后按照 Topic 和 Partition,放进对应的发送队列中。如果 Partition 没填,那么情况会是这样的:a、Key 有填。按照 Key 进行哈希,相同 Key 去一个 Partition。b、Key 没填。Round-Robin 来选 Partition。
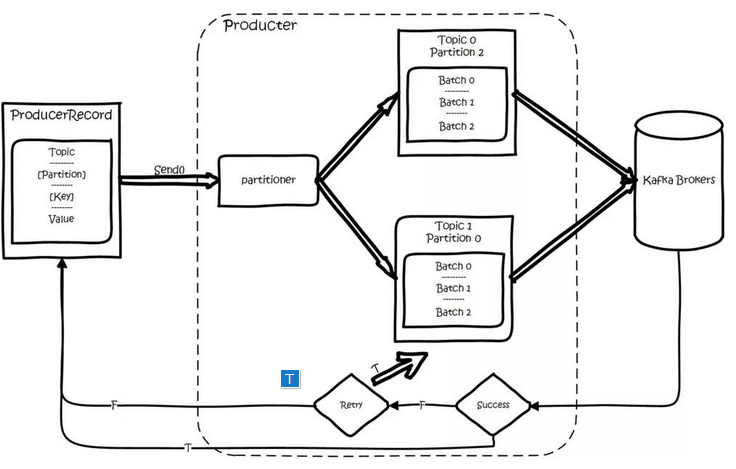
producer将会和Topic下所有partition leader保持socket连接,消息由producer直接通过socket发送到broker。其中partition leader的位置(host:port)注册在zookeeper中,producer作为zookeeper client,已经注册了watch用来监听partition leader的变更事件,因此,可以准确的知道谁是当前的leader。
producer端采用异步发送:将多条消息暂且在客户端buffer起来,并将他们批量的发送到broker,小数据IO太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率。
(2)数据消费过程(Consume)
对于消费者,不是以单独的形式存在的,每一个消费者属于一个consumer group,一个group包含多个consumer。特别需要注意的是:订阅Topic是以一个消费组来订阅的,发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费。
如果所有的Consumer都具有相同的group,那么就像是一个点对点的消息系统;如果每个consumer都具有不同的group,那么消息会广播给所有的消费者。
具体说来,这实际上市根据partition来分的,一个 Partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费,消费组里的每个消费者是关联到一个partition的,因此有这样的说法:对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
同一个消费组的两个消费者不会同时消费一个partition。

在kafka中,采用了pull方式,即consumer在和broker建立连接之后,主动去pull(或者说fetch)消息,首先consumer端可以根据自己的消费能力适时的去fetch消息并处理,且可以控制消息消费的进度(offset)。
partition中的消息只有一个consumer在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,可见kafka broker端是相当轻量级的。当消息被consumer接收之后,需要保存 Offset 记录消费到哪,以前保存在 ZK 中,由于 ZK 的写性能不好,以前的解决方法都是 Consumer 每隔一分钟上报一次,在 0.10 版本后,Kafka 把这个 Offset 的保存,从 ZK 中剥离,保存在一个名叫 consumeroffsets topic 的 Topic 中,由此可见,consumer客户端也很轻量级。
4、消息传送机制
Kafka 支持 3 种消息投递语义,在业务中,常常都是使用 At least once 的模型。
- At most once:最多一次,消息可能会丢失,但不会重复。
- At least once:最少一次,消息不会丢失,可能会重复。
- Exactly once:只且一次,消息不丢失不重复,只且消费一次。
参考链接:
注:本文是一个总结性笔记,参考了一些其他写的不错的文章,特在此进行说明,主要如下:
https://www.cnblogs.com/cxhfuujust/p/10941674.html
https://www.w3cschool.cn/apache_kafka/apache_kafka_introduction.html
https://www.cnblogs.com/likehua/p/3999538.html
【Apache Kafka】一、Kafka简介及其基本原理的更多相关文章
- [转帖]kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建 http://www.aboutyun.com/thread-9341-1-1.html 还没看完 感觉挺好的. 问题导读: 1.zook ...
- Kafka 探险 - 架构简介
Kafka 探险 - 架构简介 这个 Kafka 的专题,我会从系统整体架构,设计到代码落地.和大家一起杠源码,学技巧,涨知识.希望大家持续关注一起见证成长! 我相信:技术的道路,十年如一日!十年磨一 ...
- Kafka记录-Kafka简介与单机部署测试
1.Kafka简介 kafka-分布式发布-订阅消息系统,开发语言-Scala,协议-仿AMQP,不支持事务,支持集群,支持负载均衡,支持zk动态扩容 2.Kafka的架构组件 1.话题(Topic) ...
- Apache Kafka安全| Kafka的需求和组成部分
1.目标 - 卡夫卡安全 今天,在这个Kafka教程中,我们将看到Apache Kafka Security 的概念 .Kafka Security教程包括我们需要安全性的原因,详细介绍加密.有了这 ...
- Apache ZooKeeper在Kafka中的角色 - 监控和配置
1.目标 今天,我们将看到Zookeeper在Kafka中的角色.本文包含Kafka中需要ZooKeeper的原因.我们可以说,ZooKeeper是Apache Kafka不可分割的一部分.在了解Zo ...
- apache基金会开源项目简介
apache基金会开源项目简介 项目名称 描述 HTTP Server 互联网上首屈一指的HTTP服务器 Abdera Apache Abdera项目的目标是建立一个功能完备,高效能的IETF ...
- CentOS 7部署Kafka和Kafka集群
CentOS 7部署Kafka和Kafka集群 注意事项 需要启动多个shell脚本交互客户端进行验证,运行中的客户端不要停止. 准备工作: 安装java并设置java环境变量,在`/etc/prof ...
- Spark Streaming + Kafka整合(Kafka broker版本0.8.2.1+)
这篇博客是基于Spark Streaming整合Kafka-0.8.2.1官方文档. 本文主要讲解了Spark Streaming如何从Kafka接收数据.Spark Streaming从Kafka接 ...
- 【Kafka】Kafka集群环境搭建
目录 一.初始环境准备 二.下载安装包并上传解压 三.修改配置文件 四.启动ZooKeeper 五.启动Kafka集群 一.初始环境准备 必须安装了JDK和ZooKeeper,并保证Zookeeper ...
- kafka实战教程(python操作kafka),kafka配置文件详解
kafka实战教程(python操作kafka),kafka配置文件详解 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是 ...
随机推荐
- Android开发之ListView实现不同品种分类分隔栏的效果(非ExpandableListView实现)
我们有时候会遇到这么一个情况.就是我在一个ListView里面须要显示的东西事实上是有种类之分的.比方我要分冬天,夏天.秋天.春天,然后在这每一个季节以下再去载入各自的条目数据. 还有,比方我们的通讯 ...
- 解决Mysql存储中文的问题
Mysql无法存储中文或者中文乱码,当然是编码的问题.你可以mysql -u root -p进入Mysql命令行环境,然后输入命令查看当前编码格式: mysql> show variables ...
- Weka算法Classifier-meta-AdaBoostM1源代码分析(一)
多分类器组合算法简单的来讲经常使用的有voting,bagging和boosting,当中就效果来说Boosting略占优势,而AdaBoostM1算法又相当于Boosting算法的"经典款 ...
- HDU 1814 Peaceful Commission(2-sat 模板题输出最小字典序解决方式)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1814 Problem Description The Public Peace Commission ...
- Vim 经常使用快捷键及键盘图
Vim经常使用的快捷键 h - 光标左移一个字符 j - 光标下移一个字符 k - 光标上移一个字符 l - 光标右移一个字符 下移15行 - 15j Ctrl + f - 屏幕向下移动一页 ...
- caffe代码阅读10:Caffe中卷积的实现细节(涉及到BaseConvolutionLayer、ConvolutionLayer、im2col等)-2016.4.3
一. 卷积层的作用简单介绍 卷积层是深度神经网络中的一个重要的层,该层实现了局部感受野.通过这样的局部感受野,能够有效地减少參数的数目. 我们将结合caffe来解说详细是怎样实现卷积层的前传和反传的. ...
- Linux gadget驱动分析3------复合设备驱动
windows上面对usb复合设备的识别需要下面条件. “ 如果设备满足下列要求,则总线驱动程序还会报告 USB\COMPOSITE 的兼容标识符: 设备描述符的设备类字段 (bDeviceClass ...
- POJ 3264 Balanced Lineup 区间最值
POJ3264 比较裸的区间最值问题.用线段树或者ST表都可以.此处我们用ST表解决. ST表建表方法采用动态规划的方法, ST[I][J]表示数组从第I位到第 I+2^J-1 位的最值,用二分的思想 ...
- JSP-Runoob:JSP 表单处理
ylbtech-JSP-Runoob:JSP 表单处理 1.返回顶部 1. JSP 表单处理 我们在浏览网页的时候,经常需要向服务器提交信息,并让后台程序处理.浏览器中使用 GET 和 POST 方法 ...
- openStack aio nova service-list neutron ext-list