Spark MLlib编程API入门系列之特征选择之向量选择(VectorSlicer)
不多说,直接上干货!
特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择)。
VectorSlicer用于从原来的特征向量中切割一部分,形成新的特征向量,比如,原来的特征向量长度为10,我们希望切割其中的5~10作为新的特征向量,使用VectorSlicer可以快速实现。
理论,见
机器学习概念之特征选择(Feature selection)之VectorSlicer算法介绍
完整代码
VectorSlicer .scala
package zhouls.bigdata.DataFeatureSelection import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.ml.attribute.{Attribute, AttributeGroup, NumericAttribute}
import org.apache.spark.ml.feature.VectorSlicer//引入ml里的特征选择的VectorSlicer
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.StructType /**
* By zhouls
*/
object VectorSlicer extends App {
val conf = new SparkConf().setMaster("local").setAppName("VectorSlicer")
val sc = new SparkContext(conf) val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._ //构造特征数组
val data = Array(Row(Vectors.dense(-2.0, 2.3, 0.0))) //为特征数组设置属性名(字段名),分别为f1 f2 f3
val defaultAttr = NumericAttribute.defaultAttr
val attrs = Array("f1", "f2", "f3").map(defaultAttr.withName)
val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]]) //构造DataFrame
val dataRDD = sc.parallelize(data)
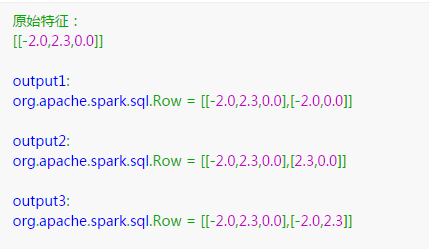
val dataset = sqlContext.createDataFrame(dataRDD, StructType(Array(attrGroup.toStructField()))) print("原始特征:")
dataset.take().foreach(println) //构造切割器
var slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features") //根据索引号,截取原始特征向量的第1列和第3列
slicer.setIndices(Array(,))
print("output1: ")
slicer.transform(dataset).select("userFeatures", "features").first() //根据字段名,截取原始特征向量的f2和f3
slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")
slicer.setNames(Array("f2","f3"))
print("output2: ")
slicer.transform(dataset).select("userFeatures", "features").first() //索引号和字段名也可以组合使用,截取原始特征向量的第1列和f2
slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")
slicer.setIndices(Array()).setNames(Array("f2"))
print("output3: ")
slicer.transform(dataset).select("userFeatures", "features").first() }
输出结果是
python语言来编写
from pyspark.ml.feature import VectorSlicer
from pyspark.ml.linalg import Vectors
from pyspark.sql.types import Row df = spark.createDataFrame([
Row(userFeatures=Vectors.sparse(, {: -2.0, : 2.3}),),
Row(userFeatures=Vectors.dense([-2.0, 2.3, 0.0]),)]) slicer = VectorSlicer(inputCol="userFeatures", outputCol="features", indices=[]) output = slicer.transform(df) output.select("userFeatures", "features").show()
Spark MLlib编程API入门系列之特征选择之向量选择(VectorSlicer)的更多相关文章
- Spark MLlib编程API入门系列之特征选择之卡方特征选择(ChiSqSelector)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). ChiSqSelector用于使用卡方检 ...
- Spark MLlib编程API入门系列之特征选择之R模型公式(RFormula)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). RFormula用于将数据中的字段通过R ...
- Spark MLlib编程API入门系列之特征提取之主成分分析(PCA)
不多说,直接上干货! 主成分分析(Principal Component Analysis,PCA), 将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法. 参考 http://blo ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- Spark SQL 编程API入门系列之Spark SQL支持的API
不多说,直接上干货! Spark SQL支持的API SQL DataFrame(推荐方式,也能执行SQL) Dataset(还在发展) SQL SQL 支持basic SQL syntax/Hive ...
- Spark SQL 编程API入门系列之SparkSQL数据源
不多说,直接上干货! SparkSQL数据源:从各种数据源创建DataFrame 因为 spark sql,dataframe,datasets 都是共用 spark sql 这个库的,三者共享同样的 ...
- Spark SQL 编程API入门系列之Spark SQL的作用与使用方式
不多说,直接上干货! Spark程序中使用SparkSQL 轻松读取数据并使用SQL 查询,同时还能把这一过程和普通的Python/Java/Scala 程序代码结合在一起. CLI---Spark ...
- Spark SQL 编程API入门系列之SparkSQL的入口
不多说,直接上干货! SparkSQL的入口:SQLContext SQLContext是SparkSQL的入口 val sc: SparkContext val sqlContext = new o ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
随机推荐
- 4.改变eclipse选中文字颜色
window-preferences-general-editors-text editors-annotations-occurrences 和 window-preferences-general ...
- TFS Server 2017 自动化部署步骤
1 第一步,在服务器上安装TFS 2 第二步,安装完TFS后需要配置你的项目,选择管理代码的方式,这里我们可以选择传统的TFS 也可以选择GIT 方式,此处我选择的GIT 方式 3 第三步,设置代理. ...
- atomic_cmpxchg()/Atomic_read()/Atomic_set()/Atomic_add()/Atomic_sub()/atomi
[ 1.atomic_read与atomic_set函数是原子变量的操作,就是原子读和原子设置的作用.2.原子操作,就是执行操作的时候,其数值不会被其它线程或者中断所影响3.原子操作是linux内核中 ...
- I.MX6 U-boot imxotp MAC address 写入
/***************************************************************************** * I.MX6 U-boot imxotp ...
- Java类成员访问控制权限
类成员访问控制权限 在JAVA中有四种访问控制权限,分别为:private, default, protected, public 1.Private 如果一个成员方法或变量名前使用了private, ...
- [SoapUI] Learn materials
SoapUI Training : http://soapui-tutorial.com/index.php * Below are the details to access the onlin ...
- 如何下载WDK
随着Windows Vista和Windows Server 2008的相继发布,微软的驱动开发工具也进行了相应的更新换代.原来的驱动开发工具包叫做DDK(Driver Develpment Kit) ...
- Java中断机制
1. 引言 当我们点击某个杀毒软件的取消按钮来停止查杀病毒时,当我们在控制台敲入quit命令以结束某个后台服务时……都需要通过一个线程去取消另一个线程正在执行的任务.Java没有提供一种安全直接的方法 ...
- 廖雪峰python3练习题二
字符串和编码 题目: 答案: #!/usr/bin/env python3 #-*- coding:utf-8 -*- s1 = 72 s2 = 85 print('小明的成绩提高了%.1f%%个百分 ...
- k8s-helm-二十四
一.介绍 Helm是Kubernetes的一个包管理工具,用来简化Kubernetes应用的部署和管理.可以把Helm比作CentOS的yum工具. yum不光要解决包之间的依赖关系,还要提供具体的程 ...