twisted(1)--何为异步
早就想写一篇文章,整体介绍python的2个异步库,twisted和tornado。我们在开发python的tcpserver时候,通常只会用3个库,twisted、tornado和gevent,其中以twisted和tornado为代表的异步库的效率比较高,但对于开发者要求有点高。大家都在讨论异步效率高,那到底什么是异步,为何它的效率比较高呢?世界总是守恒的,异步效率高的同时牺牲了什么呢?我们今天就来讲讲python的异步库。
其实我们谈论的异步库都是基于计算机模型Event Loop,它不单单只有python有,如果大家用过ajax就知道,ajax获取数据的时候,一般都是异步获取。其实整个js都是基于eventloop的单线程,好吧,扯远了。那什么是Eevent Loop呢?请看下图
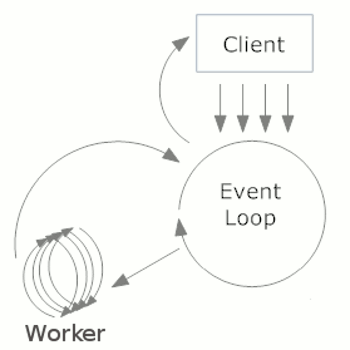
我们知道,每一个程序运行都会开启一个进程,在tcpserver服务器历史上,主要有3种方式来处理客户端来的连接。
为了方便说明,我们把tcpserver想象成对银行办理业务的过程,你每次去银行办理业务的时候,其实真正办理业务的时间并不长,其中很多时候,银行的工作人员也在等待,比如她操作一笔业务,电脑还没有及时反应过来,她没事可做,只能等待;打印各种文件的时候,也在等待。这其实跟我们的tcpserver是一样的,很多应用,我们的tcpserver一直在等待。
第一,阻塞排队。银行只开通一个窗口,每个人过来,都要排队,每一个人都要等待,其中还有很多时候,银行的工作人员在等电脑、打印机的操作时间。这种方式效率最低下。
第二,子进程。每次来一个客户,银行都开启一个窗口,专门接待,但银行的窗口不是无限的,每开启一个窗口,都有代价。这种方式比上面好了一些,但效率还不是那么高。
第三,线程。银行看到每个业务员虽然一直在忙活,但中间等待时间过长,效率提高不上来。于是,领导规定,每个业务员同时处理10个客户(1个进程开始10个线程),在处理客户1的空余时间,再处理客户2,或者其他的。嗯,貌似效率提高了,但业务员同时接这么多客户,极其容易出错(线程模式,确实容易出错,而且还不好控制,通常线程都只是处理比较单一、简单的任务)。
好了,经过对历史问题的研究,银行终于想到了终极大法,异步。银行请了机器人做业务员,并且把所有的客户都围成一个圈(这个圈就是eventloop),机器人站在这个圈的中间,不停的旋转(无限循环)。机器人每次接到一个客户,都让客户加入到这个圈子里。然后就开始处理业务,处理业务,那旋转暂停,如果在处理这个业务的时候,遇到任何忙等待行为,比如操作打印机等待、操作电脑时等待,都会先把这个业务挂起来,保存好(保存上下文环境,其实可以想象成压栈),然后继续旋转,如果有其他业务过来,处理之,继续上述行为。这时候,有个业务等待完毕,发送信号给机器人,机器人把刚才挂起的这个业务环境(把保存好的上下文环境拉出来,想象成出栈),然后继续处理,一直到处理完为止。
整个过程就是无限循环,遇到事件就处理,如果这个事件需要等待,就挂起,继续循环,如果等待完毕,发送信号给循环,继续处理,完毕后,继续循环。这就是异步。
对比历史的3个过程,异步是不是效率明显要比之前的高很多?但是也有代价,尤其对程序员要求比较高,什么时候该保存上下文?什么时候出来?出错的时候,如何处理?等等,这个以后我们会逐渐介绍这其中的问题。
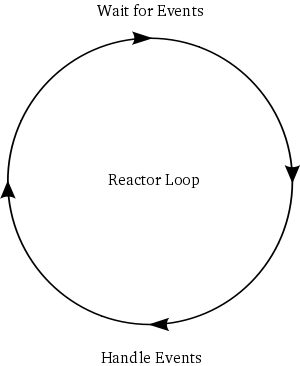
下面我们回到实际的twisted,这个图是官方引用图,我觉得非常好的诠释了twisted的运行过程。通过这个图,再结合我上面的例子,我想大家对twisted的运行过程有个基本了解了。
实际上,这个reactor loop就是整合twisted最核心的东西,所有的事件都在这个“圈”上,而在此基础上,再加上socket,就是接受网络客户端数据的过程。这个圈在没有socket的情况下,也可以工作。以后我们会遇到twisted结合rabbitmq的情况,rabbitmq的消费者也是一个"圈",其实就是把这个"圈"套在twisted的哪个"圈"上,只不过twisted的任何事件,都需要异步化。
上面说了这么多概念,我们就用代码试试twisted。我发现网上很多博客开始介绍twisted,往往一大堆代码,新手都不知道怎么入手,这对新手来说,是一个难题。我们今天就尝试解决这个难题。
from twisted.internet import reactor
reactor.run()
代码如上,就1行代码,直接运行,这时候这个"圈"就运行起来了。没有socket,不能接受客户端写入数据。
在此基础上,加一点料。
import time def hello():
print("Hello world!===>" + str(int(time.time()))) from twisted.internet import reactor
reactor.callWhenRunning(hello)
reactor.callLater(3, hello)
reactor.run()
看代码,我想,你就是不懂twisted,看字面意思,也知道这怎么回事了吧。callWhenRunning,就是reactor开始运行的时候,就触发hello函数;callLater就是3秒以后再触发一次。看一下结果
/usr/bin/python3. /home/yudahai/PycharmProjects/test0001/test001.py
Hello world!===>
Hello world!===>
结果也这样,是不是很简单?对,单纯的reactor确实非常简单。我们多尝试复杂点的任务看看。
import time def hello(name):
print("Hello world!===>" + name + '===>' + str(int(time.time()))) from twisted.internet import reactor, task task1 = task.LoopingCall(hello, 'ding')
task1.start(10) reactor.callWhenRunning(hello, 'yudahai')
reactor.callLater(3, hello, 'yuyue') reactor.run()
这面在函数里面,多加了一个参数,又在其中,加了一个循环任务taks1,task1每10秒运行一次。task用twisted会经常用到,因为我们会轮询检测每个连接上来的客户端意外断线的情况,这时候就要用到task。好了,看看结果。
/usr/bin/python3. /home/yudahai/PycharmProjects/test0001/test001.py
Hello world!===>ding===>
Hello world!===>yudahai===>
Hello world!===>yuyue===>
Hello world!===>ding===>
Hello world!===>ding===>
Hello world!===>ding===>
Hello world!===>ding===>
Hello world!===>ding===>
Hello world!===>ding===>
Hello world!===>ding===>
看到结果,大家应该对日常twisted这个"圈"会基本使用了吧。
嗯,基本使用会了,但貌似这个很简单呀,没有网上所说的,twisted如何难呀?貌似也没看到中间有任何代价呀?为什么一定要异步呢?为什么中间不能阻塞呢?好吧,上面的例子确实看不出来,我们来看如下一段代码,看看阻塞的效果。大家都知道,我们这边是不能访问google网站的,我们在中间试试访问google网站,看看效果会咋样。
import time
import requests def hello(name):
print("Hello world!===>" + name + '===>' + str(int(time.time()))) def request_google():
res = requests.get('http://www.google.com')
return res from twisted.internet import reactor, task reactor.callWhenRunning(hello, 'yudahai') reactor.callLater(, request_google) reactor.callLater(, hello, 'yuyue') reactor.run()
我在开始的时候运行一个打印任务,非阻塞,然后1秒之后,发送一个指向google的请求,到第3秒的时候,再执行打印。看看结果
/usr/bin/python3. /home/yudahai/PycharmProjects/test0001/test001.py
Hello world!===>yudahai===>
Hello world!===>yuyue===>
Unhandled Error
Traceback (most recent call last):
File "/home/yudahai/PycharmProjects/test0001/test001.py", line , in <module>
reactor.run()
File "/usr/local/lib/python3.5/dist-packages/twisted/internet/base.py", line , in run
self.mainLoop()
File "/usr/local/lib/python3.5/dist-packages/twisted/internet/base.py", line , in mainLoop
self.runUntilCurrent()
--- <exception caught here> ---
File "/usr/local/lib/python3.5/dist-packages/twisted/internet/base.py", line , in runUntilCurrent
call.func(*call.args, **call.kw)
File "/home/yudahai/PycharmProjects/test0001/test001.py", line , in request_google
res = requests.get('http://www.google.com')
File "/usr/local/lib/python3.5/dist-packages/requests/api.py", line , in get
return request('get', url, params=params, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/requests/api.py", line , in request
return session.request(method=method, url=url, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/requests/sessions.py", line , in request
resp = self.send(prep, **send_kwargs)
File "/usr/local/lib/python3.5/dist-packages/requests/sessions.py", line , in send
r = adapter.send(request, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/requests/adapters.py", line , in send
raise ConnectionError(e, request=request)
requests.exceptions.ConnectionError: HTTPConnectionPool(host='www.google.com', port=): Max retries exceeded with url: / (Caused by NewConnectionError('<requests.packages.urllib3.connection.HTTPConnection object at 0x7fc189c69e48>: Failed to establish a new connection: [Errno 101] Network is unreachable',))
看看2个打印之间的间隔,大概相差了130秒,也就是说,中间的130秒,这个程序什么事都没有干,仅仅是等待。当然,我这个例子有点极端,但在实际过程中,访问数据库,访问网络,都有可能阻塞住。程序一旦阻塞,效率会极其底下。
那该如何解决呢?这边有2种方法,一个是用twisted自带的httpclient进行访问,twisted自带的httpclient由于是异步的,不会阻塞住整个reactor的运行;其次是用线程的方式运行,注意,这里的线程不是python普通线程,是twisted自带的线程,它访问完毕的时候,会发送一个信号给reactor。下面我们分别用2中方法试试吧。
# coding:utf-8
import time
from twisted.web.client import Agent
from twisted.web.http_headers import Headers
from twisted.internet import reactor, task, defer def hello(name):
print("Hello world!===>" + name + '===>' + str(int(time.time()))) @defer.inlineCallbacks
def request_google():
agent = Agent(reactor)
try:
result = yield agent.request('GET', 'http://www.google.com', Headers({'User-Agent': ['Twisted Web Client Example']}), None)
except Exception as e:
print e
return
print(result) reactor.callWhenRunning(hello, 'yudahai') reactor.callLater(1, request_google) reactor.callLater(3, hello, 'yuyue') reactor.run()
这就是非阻塞版本的代码,其中,request返回的是一个延迟对象,所以不会阻塞住reactor,看看结果。
/usr/bin/python2. /home/yudahai/PycharmProjects/test0001/test001.py
Hello world!===>yudahai===>
Hello world!===>yuyue===>
User timeout caused connection failure.
除了访问google的,其他的都按时回来,访问谷歌的并没有阻塞reactor。
上面用非阻塞的方式访问过了,其实在现实过程中,我们很多库没有非阻塞模式的api,要非阻塞模式,一定要返回twisted的defer对象,如果写一个库,还要针对twisted写一个异步版,这肯定强人所难。而且很多时候,哪怕自己的函数,如果不是特别复杂,都可以用线程模式,twisted本身访问数据库就是线程模式。我们来看看线程模式的代码。
# coding:utf-8
import time
import requests
from twisted.internet import reactor, task, defer def hello(name):
print("Hello world!===>" + name + '===>' + str(int(time.time()))) def request_google():
try:
result = requests.get('http://www.google.com', timeout=10)
except Exception as e:
print e
return
print(result) reactor.callWhenRunning(hello, 'yudahai') reactor.callInThread(request_google) reactor.callLater(3, hello, 'yuyue') reactor.run()
代码很简单,就是把request_google换成线程模式。看看结果。
/usr/bin/python2. /home/yudahai/PycharmProjects/test0001/test001.py
Hello world!===>yudahai===>
Hello world!===>yuyue===>
HTTPConnectionPool(host='www.google.com', port=): Max retries exceeded with url: / (Caused by NewConnectionError('<requests.packages.urllib3.connection.HTTPConnection object at 0x7fc9da0b1ad0>: Failed to establish a new connection: [Errno 101] Network is unreachable',))
是不是也同样达到目的了?嗯,这时候,大家可能会在想,既然线程也可以把阻塞代码线程化,为啥还直接写异步代码呢?异步代码那么难写、难看还容易出错。
这边其实有几个理由,在twisted中,不能大量使用线程。
1、效率问题,如果用线程,我们干嘛还用twisted呢?线程会频繁切换cpu调度,如果大量使用线程,会极大浪费cpu资源,效率会严重下降。
2、线程安全,如果第一个问题稍微还有点理由的话,那线程安全问题绝对不能忽视了。比如用twisted接受网络数据的时候,是非线程安全的,如果用线程模式接受数据,会引起程序崩溃。twisted只有极少数的api支持线程。其实用的最多的例子就是消息队列的接受系统,很多初级程序员会用线程模式来做消息队列的接受方式,一开始没问题,结果运行一段时间以后,就会发现程序不能正常接受数据了,而且还不报错。twisted官方也建议大家,只要有异步库,一定优先使用异步库,线程只是做非常简单而且不是频繁的操作。
好了,这章就先讲到这,我们下一章会继续讲twisted做tcpserver,把上一个flask api 系列的项目引进来,做一个聊天系统。
twisted(1)--何为异步的更多相关文章
- 转载 twisted(1)--何为异步
Reference: http://www.cnblogs.com/yueerwanwan0204/p/5589860.html 早就想写一篇文章,整体介绍python的2个异步库,twisted和t ...
- 对比Tornado和Twisted两种异步Python框架
做Python的人,一定知道两个性能优秀的异步网络框架:tornado,和twisted. 那么,这两个著名的框架,又有什么异同呢?tornado和twisted,我都用在几个游戏项目中,做过后端,觉 ...
- python_如何通过twisted实现数据库异步插入?
如何通过twisted实现数据库异步插入? 1. 导入adbapi 2. 生成数据库连接池 3. 执行数据数据库插入操作 4. 打印错误信息,并排错 #!/usr/bin/python3 __auth ...
- Python-通过twisted实现数据库异步插入?
如何通过twisted实现数据库异步插入? 1. 导入adbapi 2. 生成数据库连接池 3. 执行数据数据库插入操作 4. 打印错误信息,并排错 #!/usr/bin/python3 __auth ...
- Python Twisted系列教程2:异步编程初探与reactor模式
作者:dave@http://krondo.com/slow-poetry-and-the-apocalypse/ 译者:杨晓伟(采用意译) 这个系列是从这里开始的,欢迎你再次来到这里来.现在我们可 ...
- Python Twisted网络编程框架与异步编程入门教程
原作出处:twisted-intro-cn 作者:Dave 译者:杨晓伟 luocheng likebeta 转载声明:版权归原作出处所有,转载只为让更多人看到这部优秀作品合集,如果侵权,请留言告知 ...
- 【javascript 进阶】异步调用
前言 javascript的中的异步是很重要的概念,特别是ajax的提出,给整个web带来了很大的影响,今天就介绍下javascript的异步编程. 同步与异步 何为同步?何为异步呢? 同步:说白了就 ...
- JS读书心得:《JavaScript框架设计》——第12章 异步处理
一.何为异步 执行任务的过程可以被分为发起和执行两个部分. 同步执行模式:任务发起后必须等待直到任务执行完成并返回结果后,才会执行下一个任务. 异步执行模式:任务发起后不等待任务执行完成,而是马上 ...
- Python Twisted、Reactor
catalogue . Twisted理论基础 . 异步编程模式与Reactor . Twisted网络编程 . reactor进程管理编程 . Twisted并发连接 1. Twisted理论基础 ...
随机推荐
- Elasticsearch教程之基础概念
基础概念 Elasticsearch有几个核心概念.从一开始理解这些概念会对整个学习过程有莫大的帮助. 1.接近实时(NRT) Elasticsearch是一个接近实时的搜索平台.这意味 ...
- Hibernate配置文件中hiberante.hbm2ddl.auto四个参数的配置
我们在搭建环境的时候,在配置文件中有一个属性标签为: <property name="hibernate.hbm2ddl.auto"> </propert ...
- web前端开发中Nodejs、Grunt、npm等的介绍、使用
一.Nodejs的安装: Grunt和所有grunt插件都是基于nodejs来运行的,如果你的电脑上没有nodejs,就去安装吧.去 https://nodejs.org/ 上,点击页面中那个绿色.大 ...
- selenium python presence_of_element_located vs visibility_of_element_located
背景: 用WebDriverWait时,一开始用的是presence_of_element_located,我对它的想法就是他就是用来等待元素出现.结果屡屡出问题.元素默认是隐藏的,导致等待过早的就结 ...
- mysql5.5 对触发器,函数,存储引擎,事件进行主从复制情况.(转)
mysql5.5 对触发器,函数,存储引擎,事件进行主从复制情况. 转(http://blog.csdn.net/m582445672/article/details/7670802) 一.My ...
- 一篇文章看懂spark 1.3+各版本特性
Spark 1.6.x的新特性Spark-1.6是Spark-2.0之前的最后一个版本.主要是三个大方面的改进:性能提升,新的 Dataset API 和数据科学功能的扩展.这是社区开发非常重要的一个 ...
- python2.+进化至python3.+ 语法变动差异(不定期更新)
1.输出 python2.+ 输出: print "" python3.+ 输出: print ("") 2.打开文件 python2.+ 打开文件: file ...
- 手游Apk破解疯狂,爱加密apk加固保护开发人员
2013年手游行业的规模与收入均实现了大幅增长,发展势头强劲.权威数据显示, 我国移动游戏市场实际销售收入从2012年的32.4亿猛增到2013年的112.4亿元,同比增长了246.9%,手游用户从2 ...
- 杯具,万达电商又换CEO
万达电商CEO再离职.而这距他入职还差一个月才满一年. 昨晚.万达电商CEO董策告诉新浪科技6月3日已正式从万达电商离职.将去往澳洲照应家人.而谈到离职原因和万达电商时,董策以开会为由收了电话. 从2 ...
- UVA 10668 - Expanding Rods(数学+二分)
UVA 10668 - Expanding Rods 题目链接 题意:给定一个铁棒,如图中加热会变成一段圆弧,长度为L′=(1+nc)l,问这时和原来位置的高度之差 思路:画一下图能够非常easy推出 ...