pandas学习series和dataframe基础
PANDAS 的使用
一.什么是pandas?
1.python Data Analysis Library 或pandas 是基于numpy的一种工具,该工具是为了解决数据分析人物而创建的。
2.pandas纳入了大量库和一些标准的数据模型,提供了高效的操作大型数据集的工具
3.pandaas提供了大量能使我们快速便捷的处理数据的函数和方法。
4.pandas使python成为了强大高效的数据分析环境的重要因素之一。
5.SPSS数据分析工具IBM 1g excel
6.panda数据预处理
二pandas的数据结构
1.数据分析三剑客:numpy,matplotlib ,pandas
①.pandas中series类
series是一种类似于一维数组的类对象,由下面两部分组成
1.velues:一组数据(ndarray类似)
2.index:相关的数据索引
Series属性
Series(['data=None', 'index=None', 'dtype=None', 'name=None', 'copy=False', 'fastpath=False'],)
series的创建有两种创建方式
(1)由列表或numpy数组创建(默认索引为0到整数型索引,还可以通过设置index参数指定索引)
格式:Series(data,index)
(2)由字典创建
格式:Series({key:value})
注意:由ndarray创建的是引用,而不是副本,对series元素的改变也会改变原来的ndarray对象中的元素。
如:s2 = Series({"A":148,"B":130,"C":118,"D":117,"E":99},dtype=np.float32,name="python")
s2
输出结果:
A 148.0
B 130.0
C 118.0
D 117.0
E 99.0
Name: python, dtype: float32
Series的索引和切片
可以使用括号取单个索引(此时返回的是元素的类型),或者中括号中一个
列表取多个索引(此时返回的任然是一个series类型)。分为显示索引和影视索引:
1显示索引:
--使用index中的值作为索引值
--使用.loc[](推荐)
注意:此时是闭区间
2.隐式索引:
--使用整数作为索引值
--使用.iloc[](推荐)
注意:此时是半闭区间
Series的基本概念
可以把series看成是一个定长的有序字典
可以通过shape,size,index,values得到series的属性
Series的方法
可以通过head(),tail()快速查看series的样式
head(num)返回一个前num列数据
tail(num)返回后num列的数据
当索引没有对应的值时,返回NaN(NOT A NUMBER)值
可以使用pd.isnumm(),pd.notnull()的方式来检测数据的缺失
如 cond = s5.isnull()
S6 = index(cond)
Series的运算
(1)使用于numpy的数组运算也适用于series
(2)series之间的运算
在运算中自动对齐相同的索引的数据
如果索引不对应,则补NaN
注意:要想保留所有的index,则需要使用.add()函数
二.DataFrame数据结构
- DataFrame是一个【表格型】数据结构,可以看做是由series组成的字典,将series的使用场景从一维拓展到多维。dataframe既有行索引也有索引
Init signature: DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
行索引:index
列索引:columns
值:values
2.dataframe的创建
同series一样,两种创建方式
dataframe以字典的键作为每一列的名称,以字典的值作为每一列的值。dataframe会自动为每一行添加行索引(和series一样)。
如:
df = DataFrame(data = np.random.randint(0,150,size=(10,4)),index = list("abcdefghij"),columns = ["python","math","english","chiness"])
df2=DataFrame(data={"python":np.random.randint(0,150,size=10),"math":np.random.randint(0,150,size=10),"chinese":np.random.randint(0,150,size=10),"english":np.random.randint(0,150,size=10)})
DataFrame的索引和切片
注意:索引表示的列索引,切片表示的行切片
1.索引
(1)对列进行索引,列索引是属性,行索引是样本
使用类似字典的方式
使用属性的方式
df[“python”],df2[["python","math"]]
df.python
(2)对行进行索引
.ix[]进行行索引
使用.loc[]加index来进行行索引
使用.iloc[]加整数数类进行行索引
返回一个series,index为原来的columns
如:df2.loc[1]
df.iloc[“a”]
df2.loc[[1,2,3]]
(3)对元素索引的方法
先获取行在获取列,如:df.loc["a"]["python"]
先获取列在获取行,如:df["python"]["a"]
二维形式进行获取单个值,如:df.loc["a","python"];df2.iloc[0,0]
- 切片
(1)列切片:如df.iloc[:,2:];df[["python","math"]]
(2)行切片:直接切片或使用loc(),iloc()如:df[1:2];df.iloc[2:5];df.loc["a":"b"]
3.dataframe的运算
下边python操作符合pandas操作函数的对应表
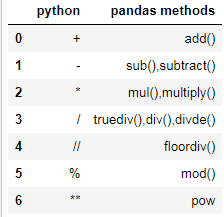
(1)同series一样
在运算中自动对齐相同的索引
如果索引不对应,则用nan补全
(2)series与dataframe之间的运算(重要)
使用python操作符:以行为单位操作(参数必须是行),对所有行都有效。(类似与numpy中二维数组与一维数组的运算,但是可能出现nan值)
注明axis,运算时指明对齐索引
使用pandas操作函数:
axis=0:以列为操作单位(参数必须是列),对所有列都有效。
axis=1:以行为操作单位(参数必须是行),对所有行都有效
如:df5.add(ss,axis=0)
pandas学习series和dataframe基础的更多相关文章
- Python之Pandas中Series、DataFrame
Python之Pandas中Series.DataFrame实践 1. pandas的数据结构Series 1.1 Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一 ...
- Python之Pandas中Series、DataFrame实践
Python之Pandas中Series.DataFrame实践 1. pandas的数据结构Series 1.1 Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一 ...
- Pandas中Series和DataFrame的索引
在对Series对象和DataFrame对象进行索引的时候要明确这么一个概念:是使用下标进行索引,还是使用关键字进行索引.比如list进行索引的时候使用的是下标,而dict索引的时候使用的是关键字. ...
- [Python] Pandas 中 Series 和 DataFrame 的用法笔记
目录 1. Series对象 自定义元素的行标签 使用Series对象定义基于字典创建数据结构 2. DataFrame对象 自定义行标签和列标签 使用DataFrame对象可以基于字典创建数据结构 ...
- Python数据分析-Pandas(Series与DataFrame)
Pandas介绍: pandas是一个强大的Python数据分析的工具包,是基于NumPy构建的. Pandas的主要功能: 1)具备对其功能的数据结构DataFrame.Series 2)集成时间序 ...
- pandas中series和dataframe之间的区别
series结构有索引,和列名组成,如果没有,那么程序会自动赋名为None series的索引名具有唯一性,索引可以数字和字符,系统会自动将他们转化为一个类型object. dataframe由索引和 ...
- Pandas中Series与Dataframe的初始化
(一)Series初始化 1.通过列表,index自动生成 se = pd.Series(['Tom', 'Nancy', 'Jack', 'Tony']) print(se) 2.通过列表,指定in ...
- Pandas中Series与Dataframe的区别
1. Series Series通俗来讲就是一维数组,索引(index)为每个元素的下标,值(value)为下标对应的值 例如: arr = ['Tom', 'Nancy', 'Jack', 'Ton ...
- numpy、pandas学习二
#numpy中arrary与pandas中series.DataFrame区别#arrary生成数组,无索引.列名:series有索引,且仅能创建一维数组:DataFrame有索引.列名import ...
随机推荐
- JPA @MappedSuperclass注解的使用说明(转)
(2011-11-07 11:37:30) 转载▼ http://blog.sina.com.cn/s/blog_7085382f0100uk4p.html 标签: 杂谈 基于代码复用和模型分离的 ...
- struts2.5+框架使用通配符与动态方法
概述:struts2.5以后加强了安全性,下面就是安全配置引发的问题 通配符: 在学习struts框架时经常会使用到通配符调用方法,如下: <package name="usercru ...
- POJ-2186-Popular Cows(强连通分量,缩点)
链接:https://vjudge.net/problem/POJ-2186 题意: 有N(N<=10000)头牛,每头牛都想成为most poluler的牛,给出M(M<=50000)个 ...
- Codecraft-17 and Codeforces Round #391 (Div. 1 + Div. 2, combined) A
Bash wants to become a Pokemon master one day. Although he liked a lot of Pokemon, he has always bee ...
- 1081 Rational Sum(20 分)
Given N rational numbers in the form numerator/denominator, you are supposed to calculate their sum. ...
- HTML标签的三种类型
HTML标签的类型分为三种:行内元素,行内块元素,块级元素 而标签的属性是可以转换的 display:inline: 转换为行内元素 display:linline-block 转换为行内块元素 di ...
- oracle rollback 观察时间
###########issue 0: db alert 有如下提示, thread 1 cannot allocatete new log, sequenec 1111 通过检查v$log ,发现1 ...
- 使用history.replaceState 修改url 不跳转
history.replaceState(null,null,this.urlR); //关键代码 history.replaceState是将指定的URL替换当前的URL 注意:用于替换掉的URL ...
- css3实现钟表效果
利用css3 transform属性刻画钟表的的刻度以及指针的角度,代码如下: <head> <meta charset="UTF-8"> <titl ...
- css样式优先级问题
官方表述的CSS样式优先级如下: 通用选择器(*) < 元素(类型)选择器 < 类选择器 < 属性选择器 < 伪类 < ID 选择器 < 内联样式 那么,我们来举个 ...