Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求。
一、headers的获取
就以博客园的首页为例:http://www.cnblogs.com/
打开网页,按下F12键,如下图所示:
点击下方标签中的Network,如下:
之后再点击下图所示位置:
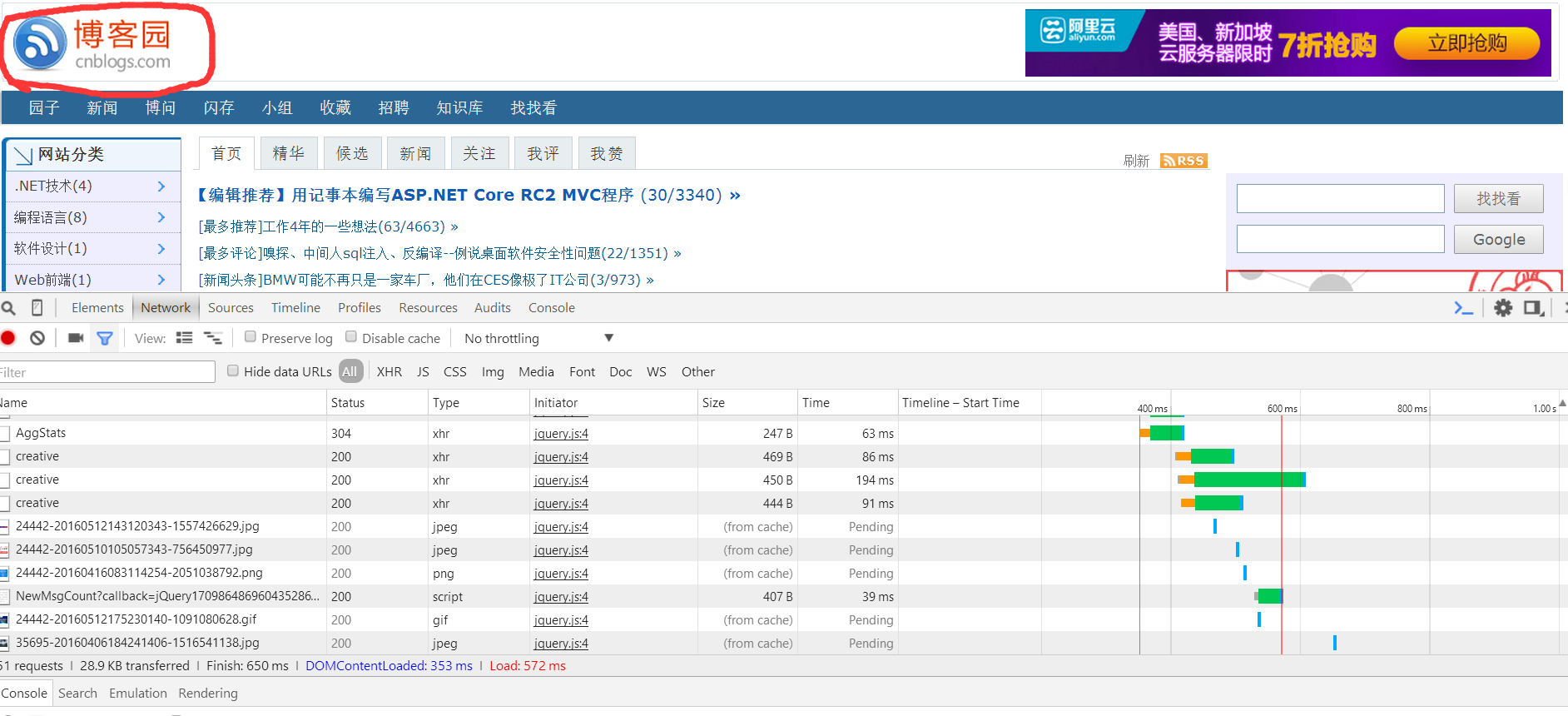
找到红色下划线位置所示的标签并点击,在右边的显示内容中可以查看到所需要的headers信息。
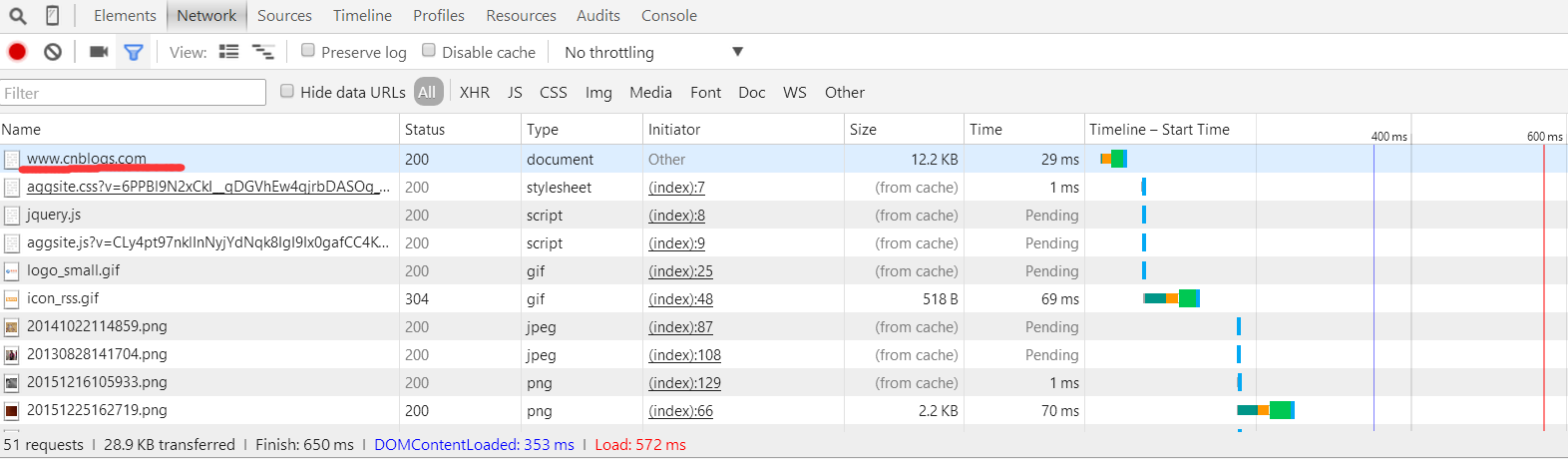
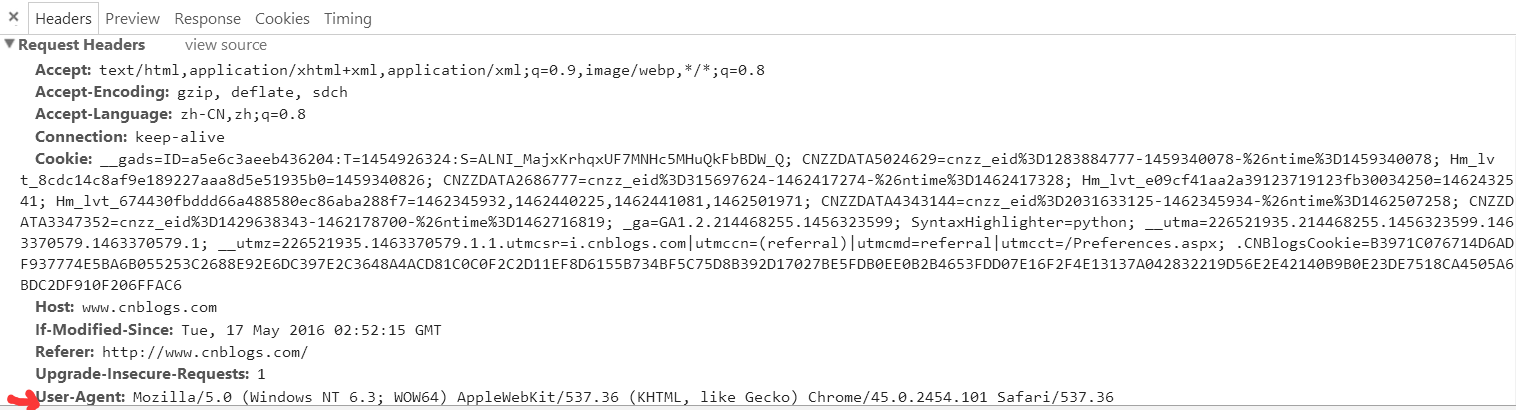
一般只需要添加User-Agent这一信息就足够了,headers同样也是字典类型;
user_agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
headers = { 'User-Agent' : user_agent }
二、data获取
以博客园登录界面为例:http://passport.cnblogs.com/user/signin?ReturnUrl=http%3A%2F%2Fwww.cnblogs.com%2F
按下F12键,如下图所示:
点击Network,然后随意输入用户名和密码,点击登录可以看到如下图所示:

博客园登录的data信息:
data={
input1:"*******",
input2:"*******",
remember:"false"
}
以电驴下载网站为例:http://secure.verycd.com/signin?error_code=emptyInput&continue=http://www.verycd.com/
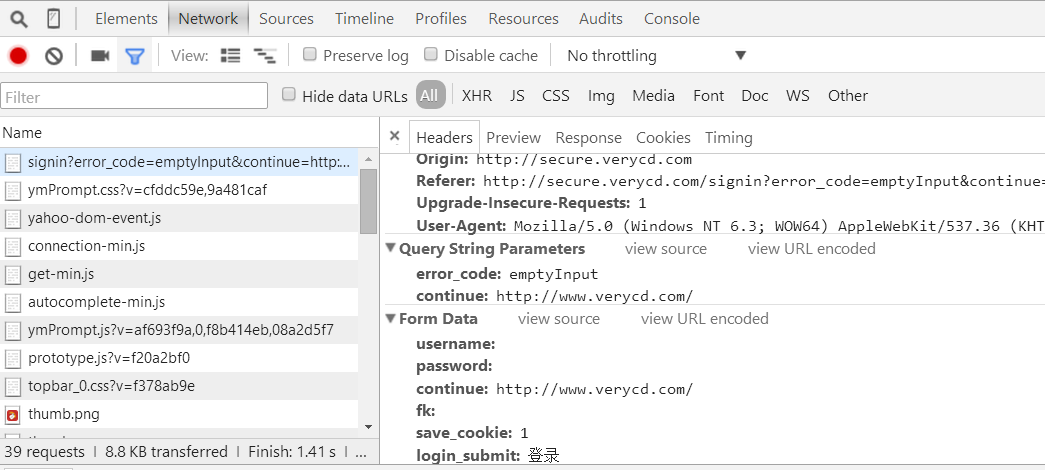
data信息在From Data标签中:
data={
username:"****",
password:"****",
continue:"http://www.verycd.com/"
fk:" ",
save_cookie:1,
login_submit:"登录"
}
每一个登录网站的data信息不一定一样,都需要进入网页确定。
好啦,今天就到这了~明天介绍一个实例:如何爬取糗百的段子。
转载时注明原作者出处:Maple2cat|Python爬虫学习:四、headers和data的获取
Python爬虫学习:四、headers和data的获取的更多相关文章
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
- Python爬虫入门四之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- 转 Python爬虫入门四之Urllib库的高级用法
静觅 » Python爬虫入门四之Urllib库的高级用法 1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我 ...
随机推荐
- nignx开启expires后相关资源不显示的问题
expires可以指定浏览器缓存,加快浏览速度 但是开启expires必须先指定root server中原来指定 location / { root D:/WWW; index index.html ...
- 纯js实现div内图片自适应大小
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- N年之后,只记得三井寿!而我们程序猿们也要加油珍惜时间!
[感觉程序员看一篇励志文章效果大于6篇技术文章,3份源码下载.....所以上此文] [说明:本文不少段落是摘自别人文章,因为本人写程序的文笔有限,怕感动不了大家,所以摘取了不错的部分] 前段时间重新看 ...
- 【温故而知新:文件操作】C#的文件读写相关
StreamReader类以及其方法ReadLine,Read,ReadToEnd的分析 首先StreamReader类的构造参数非常丰富在这里,我觉得最常用的就是StreamReader(Strea ...
- android WebView, WebChromeClient和WebViewClient加载网页基本用法
WebView, WebChromeClient和WebViewClient加载网页基本用法 webview是android中的浏览器控件,在一些手机应用中常会用到b/s模式去开发应用,这时webvi ...
- 记一次 java程序优化
优化原因 环境中部署两个程序: web应用 tomcat 10G(webservice服务端,前端web服务) java应用 5G(webservice客户端,sock ...
- eclipsecdt添加自动补全功能
自动代码补全完全是一个改善生活质量的功能呀!cdt拥有自动代码补全功能,只是我们没有打开而已 1. 绑定快捷方式 1. windows -> preferences ->general-& ...
- QQ聊天界面的布局和设计(IOS篇)-第二季
QQChat Layout - 第二季 本来第二季是快写好了, 也花了点功夫, 结果gitbook出了点问题, 给没掉了.有些细节可能会一带而过, 如有疑问, 相互交流进步~. 在第一季中我们完成了Q ...
- handsontable插件事件
Hook插件 afterChange (changes: Array, source: String):1个或多个单元格的值被改变后调用 changes:是一个2维数组包含row,prop,o ...
- Eclipse代理设置
这段时间公司实行代理上网,不仅通过浏览器上网须要不停的输入username和password,在本地调试程序时候Eclipse居然也弹出框让输入username和password. 如图: 解决的方法 ...