消息中间件-RabbitMQ集群和高可用
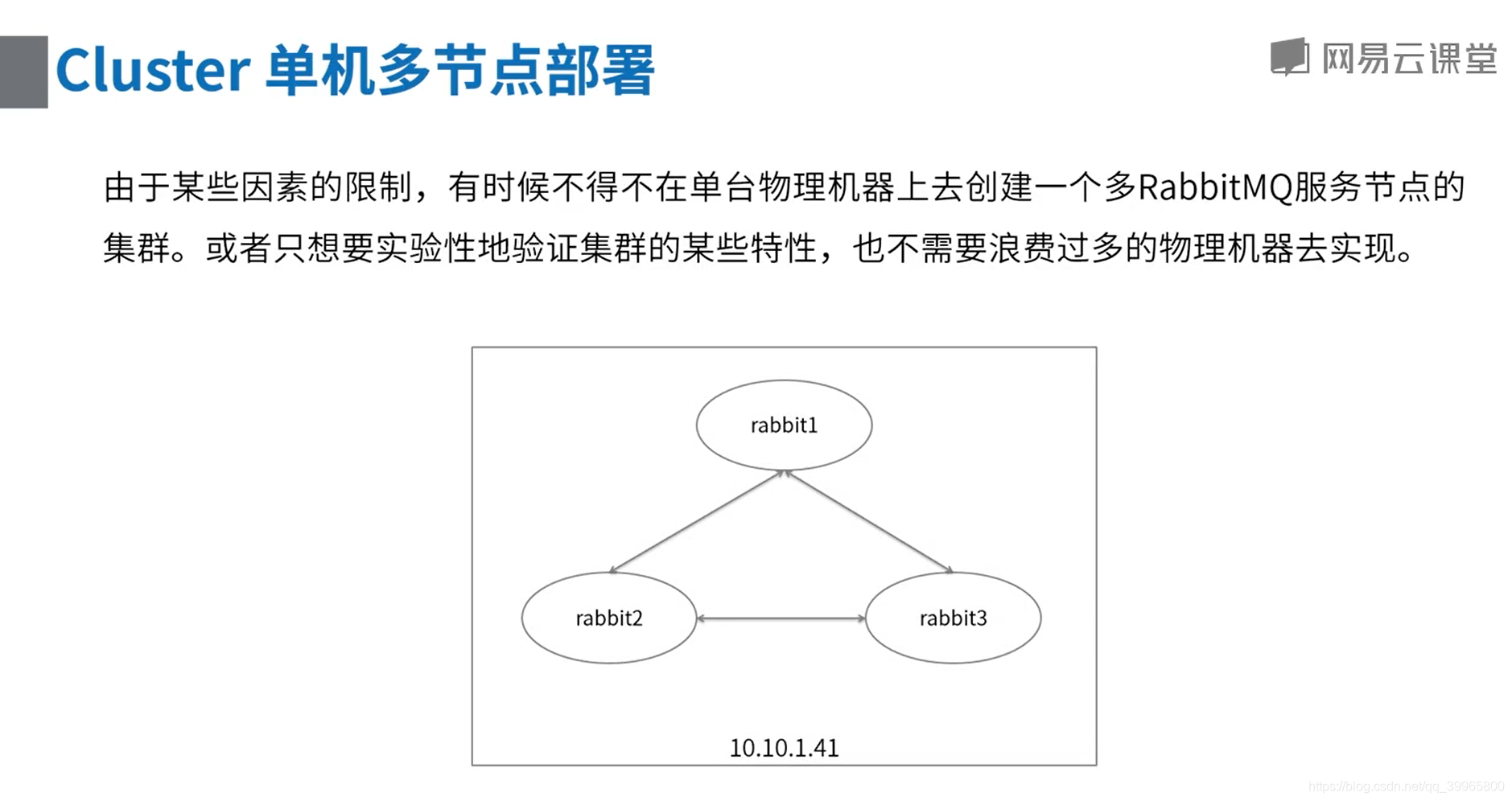
多机多节点集群部署
一、 环境准备
准备三台安装好RabbitMQ 的机器,安装方法见 安装步骤
- 10.10.1.41
- 10.10.1.42
- 10.10.1.43
提示:如果使用虚拟机,可以在一台VM上安装好RabbitMQ后,创建快照,从快照创建链接克隆,会节省很多磁盘空间
二、修改配置文件
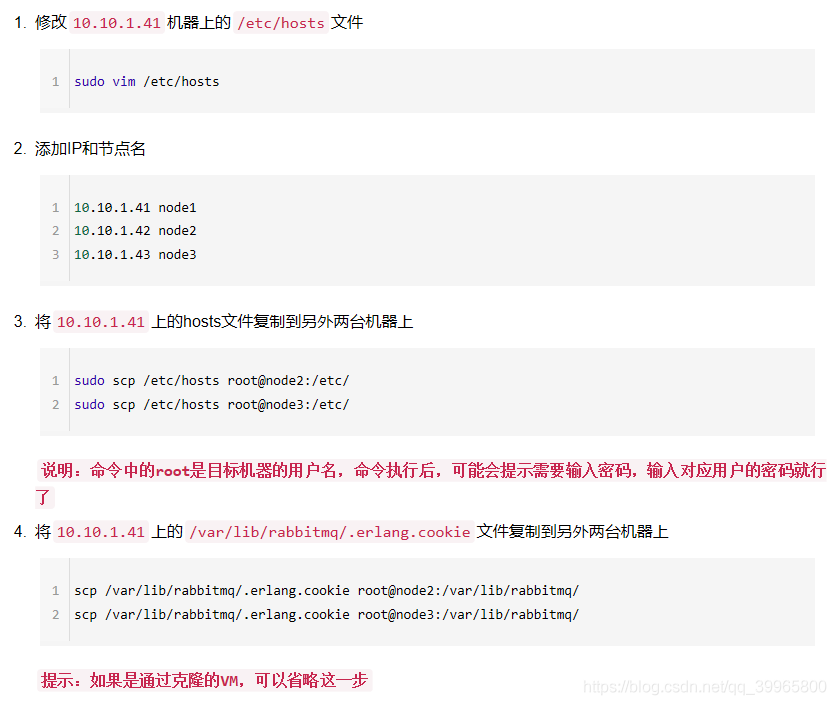
cookie必须相同
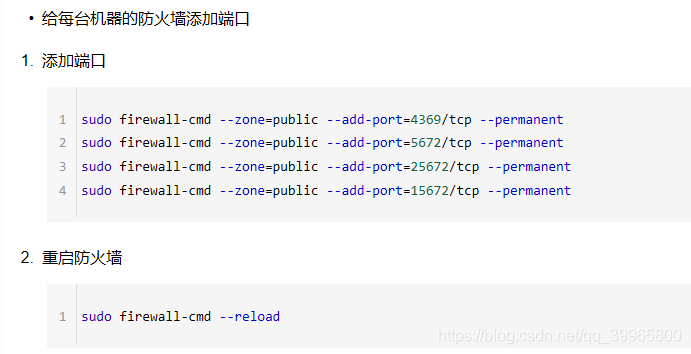
三、防火墙添加端口
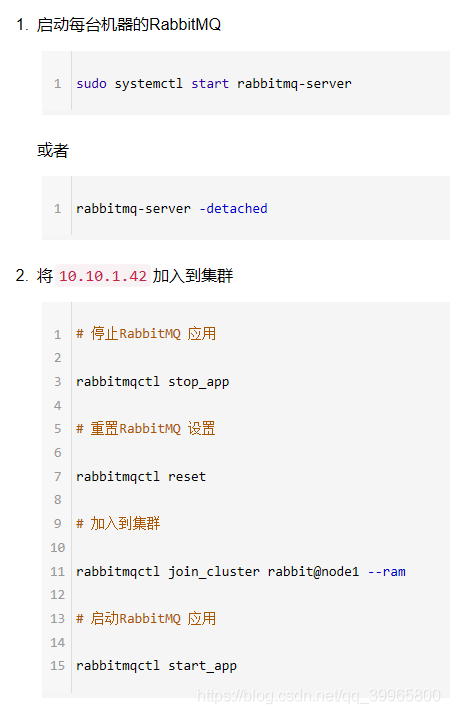
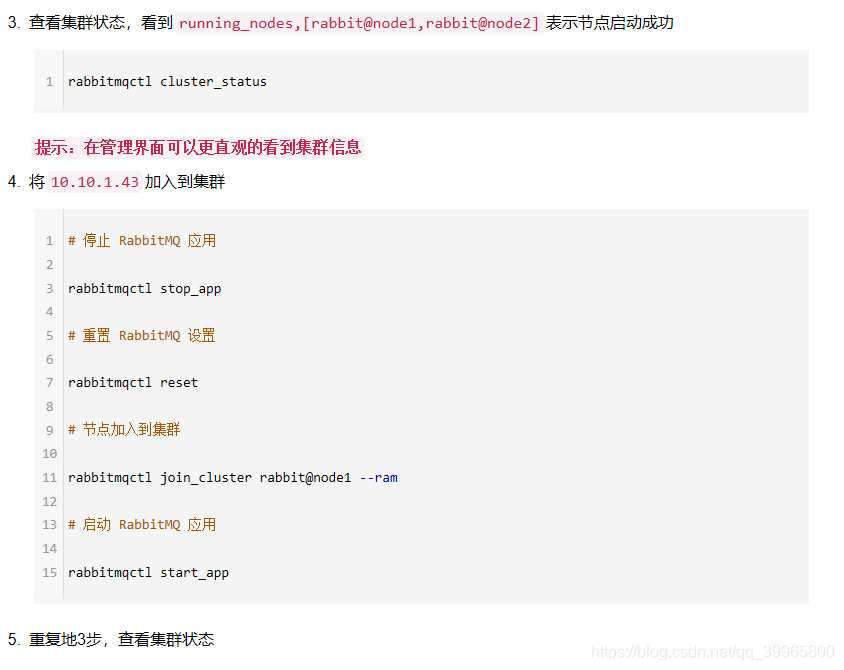
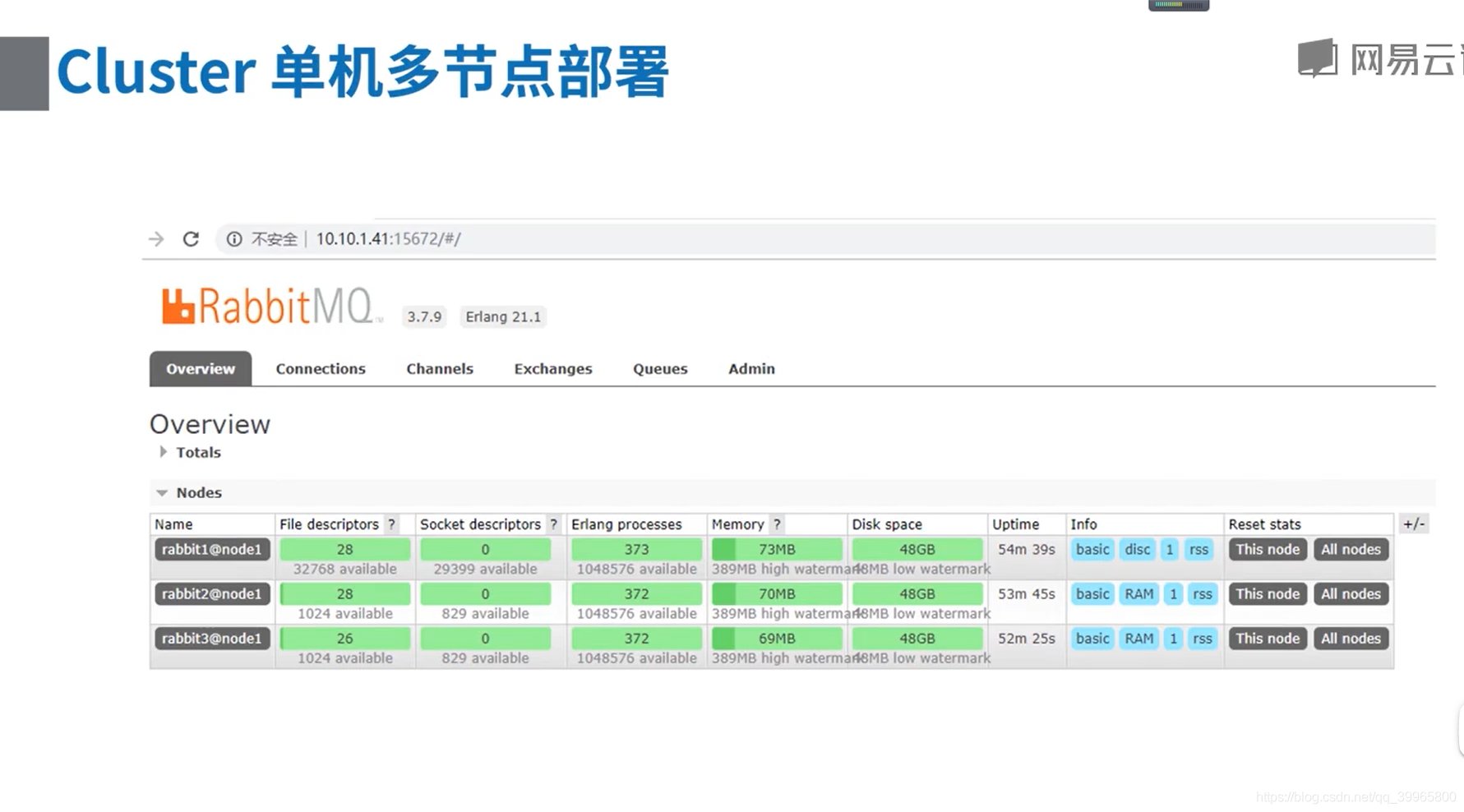
四、启动RabbitMQ

package com.study.rabbitmq.a133.cluster;
import com.rabbitmq.client.*;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.TimeoutException;
/**
* 客户端连接集群示例
*/
public class Consumer {
public static void main(String[] args) {
// 1、创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
// 2、设置连接属性
factory.setUsername("order-user");
factory.setPassword("order-user");
factory.setVirtualHost("v1");
Connection connection = null;
Channel channel = null;
// 3、设置每个节点的链接地址和端口
Address[] addresses = new Address[]{
new Address("192.168.100.242", 5672),
new Address("192.168.100.241", 5672)
};
try {
// 开启/关闭连接自动恢复,默认是开启状态
factory.setAutomaticRecoveryEnabled(true);
// 设置每100毫秒尝试恢复一次,默认是5秒:com.rabbitmq.client.ConnectionFactory.DEFAULT_NETWORK_RECOVERY_INTERVAL
factory.setNetworkRecoveryInterval(100);
// 4、从连接工厂获取连接
connection = factory.newConnection(addresses, "消费者");
// 添加重连监听器
((Recoverable) connection).addRecoveryListener(new RecoveryListener() {
/**
* 重连成功后的回调
* @param recoverable
*/
public void handleRecovery(Recoverable recoverable) {
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 已重新建立连接!");
}
/**
* 开始重连时的回调
* @param recoverable
*/
public void handleRecoveryStarted(Recoverable recoverable) {
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 开始尝试重连!");
}
});
// 5、从链接中创建通道
channel = connection.createChannel();
/**
* 6、声明(创建)队列
* 如果队列不存在,才会创建
* RabbitMQ 不允许声明两个队列名相同,属性不同的队列,否则会报错
*
* queueDeclare参数说明:
* @param queue 队列名称
* @param durable 队列是否持久化
* @param exclusive 是否排他,即是否为私有的,如果为true,会对当前队列加锁,其它通道不能访问,
* 并且在连接关闭时会自动删除,不受持久化和自动删除的属性控制。
* 一般在队列和交换器绑定时使用
* @param autoDelete 是否自动删除,当最后一个消费者断开连接之后是否自动删除
* @param arguments 队列参数,设置队列的有效期、消息最大长度、队列中所有消息的生命周期等等
*/
channel.queueDeclare("queue1", true, false, false, null);
// 7、定义收到消息后的回调
final Channel finalChannel = channel;
DeliverCallback callback = new DeliverCallback() {
public void handle(String consumerTag, Delivery message) throws IOException {
System.out.println("收到消息:" + new String(message.getBody(), "UTF-8"));
finalChannel.basicAck(message.getEnvelope().getDeliveryTag(), false);
}
};
// 8、监听队列
channel.basicConsume("queue1", false, callback, new CancelCallback() {
public void handle(String consumerTag) throws IOException {
}
});
System.out.println("开始接收消息");
System.in.read();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
} finally {
// 9、关闭通道
if (channel != null && channel.isOpen()) {
try {
channel.close();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
}
// 10、关闭连接
if (connection != null && connection.isOpen()) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
package com.study.rabbitmq.a133.cluster;
import com.rabbitmq.client.*;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
/**
* 客户端连接集群示例
*/
public class Producer {
public static void main(String[] args) {
// 1、创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
// 2、设置连接属性
factory.setUsername("order-user");
factory.setPassword("order-user");
factory.setVirtualHost("v1");
Connection connection = null;
Channel channel = null;
// 3、设置每个节点的链接地址和端口
Address[] addresses = new Address[]{
new Address("192.168.100.242", 5672),
new Address("192.168.100.241", 5672)
};
try {
// 开启/关闭连接自动恢复,默认是开启状态
factory.setAutomaticRecoveryEnabled(true);
// 设置每100毫秒尝试恢复一次,默认是5秒:com.rabbitmq.client.ConnectionFactory.DEFAULT_NETWORK_RECOVERY_INTERVAL
factory.setNetworkRecoveryInterval(100);
factory.setTopologyRecoveryEnabled(false);
// 4、使用连接集合里面的地址获取连接
connection = factory.newConnection(addresses, "生产者");
// 添加重连监听器
((Recoverable) connection).addRecoveryListener(new RecoveryListener() {
/**
* 重连成功后的回调
* @param recoverable
*/
public void handleRecovery(Recoverable recoverable) {
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 已重新建立连接!");
}
/**
* 开始重连时的回调
* @param recoverable
*/
public void handleRecoveryStarted(Recoverable recoverable) {
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date()) + " 开始尝试重连!");
}
});
// 5、从链接中创建通道
channel = connection.createChannel();
/**
* 6、声明(创建)队列
* 如果队列不存在,才会创建
* RabbitMQ 不允许声明两个队列名相同,属性不同的队列,否则会报错
*
* queueDeclare参数说明:
* @param queue 队列名称
* @param durable 队列是否持久化
* @param exclusive 是否排他,即是否为私有的,如果为true,会对当前队列加锁,其它通道不能访问,并且在连接关闭时会自动删除,不受持久化和自动删除的属性控制
* @param autoDelete 是否自动删除,当最后一个消费者断开连接之后是否自动删除
* @param arguments 队列参数,设置队列的有效期、消息最大长度、队列中所有消息的生命周期等等
*/
channel.queueDeclare("queue1", true, false, false, null);
for (int i = 0; i < 100; i++) {
// 消息内容
String message = "Hello World " + i;
try {
// 7、发送消息
channel.basicPublish("", "queue1", null, message.getBytes());
} catch (AlreadyClosedException e) {
// 可能连接已关闭,等待重连
System.out.println("消息 " + message + " 发送失败!");
i--;
TimeUnit.SECONDS.sleep(2);
continue;
}
System.out.println("消息 " + i + " 已发送!");
TimeUnit.SECONDS.sleep(2);
}
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 8、关闭通道
if (channel != null && channel.isOpen()) {
try {
channel.close();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
}
// 9、关闭连接
if (connection != null && connection.isOpen()) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
package com.study.rabbitmq.a133.cluster;
import com.rabbitmq.client.*;
import com.rabbitmq.client.Consumer;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* vhost和权限应用示例
* <p>
* 说明:先阅读文档中的使用示例,创建号用户名和vhost,分配好权限。
* http://code.study.com/MQ/rabbitmq/rabbitmq/blob/master/java/src/main/java/com/study/rabbitmq/a133/cluster/readme.md#vhost使用示例
* <p>
* 另外需要自己在管理界面创建queue2队列和test交换器
*/
public class VirtualHostsDemo {
public static void main(String[] args) {
// 1、创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
// 2、设置连接属性
factory.setUsername("order-user");
factory.setPassword("order-user");
factory.setVirtualHost("v1");
Connection connection = null;
Channel prducerChannel = null;
Channel consumerChannel = null;
// 3、设置每个节点的链接地址和端口
Address[] addresses = new Address[]{
new Address("192.168.100.242", 5672),
new Address("192.168.100.241", 5672)
};
try {
// 4、从连接工厂获取连接
connection = factory.newConnection(addresses, "消费者");
// 5、从链接中创建通道
prducerChannel = connection.createChannel();
prducerChannel.exchangeDeclare("test-exchange", "fanout");
prducerChannel.queueDeclare("queue1", false, false, false, null);
prducerChannel.queueBind("queue1", "test-exchange", "xxoo");
// 消息内容
String message = "Hello A";
prducerChannel.basicPublish("test-exchange", "c1", null, message.getBytes());
consumerChannel = connection.createChannel();
// 创建一个消费者对象
Consumer consumer = new DefaultConsumer(consumerChannel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("收到消息:" + new String(body, "UTF-8"));
}
};
consumerChannel.basicConsume("queue1", true, consumer);
System.out.println("等待接收消息");
System.in.read();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
} finally {
// 9、关闭通道
if (prducerChannel != null && prducerChannel.isOpen()) {
try {
prducerChannel.close();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
}
// 10、关闭连接
if (connection != null && connection.isOpen()) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}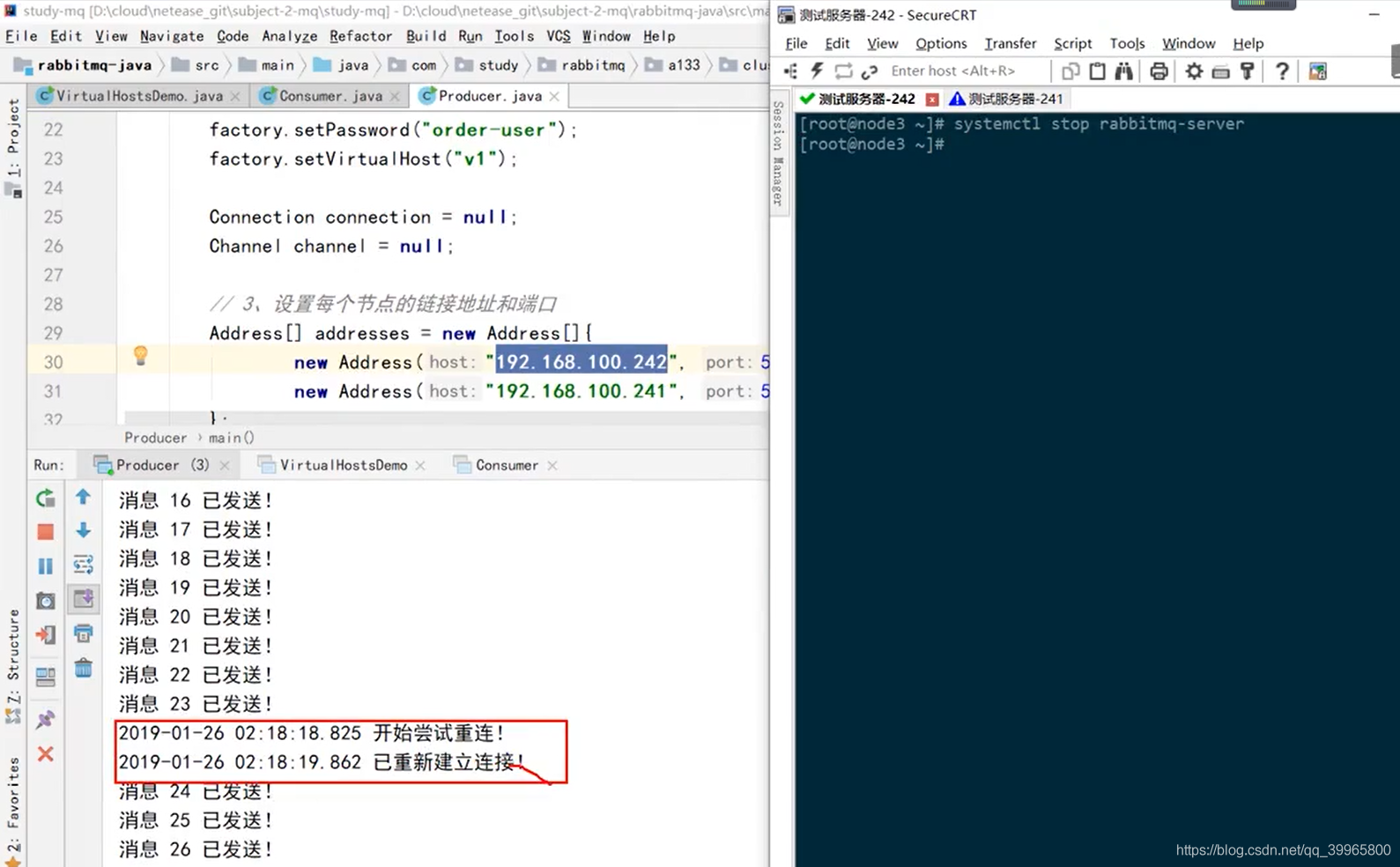
集群对外可以用个负载均衡技术
可以把请求分到不同的服务器上,但是只能将数据存放在一个地方,会出现单点故障
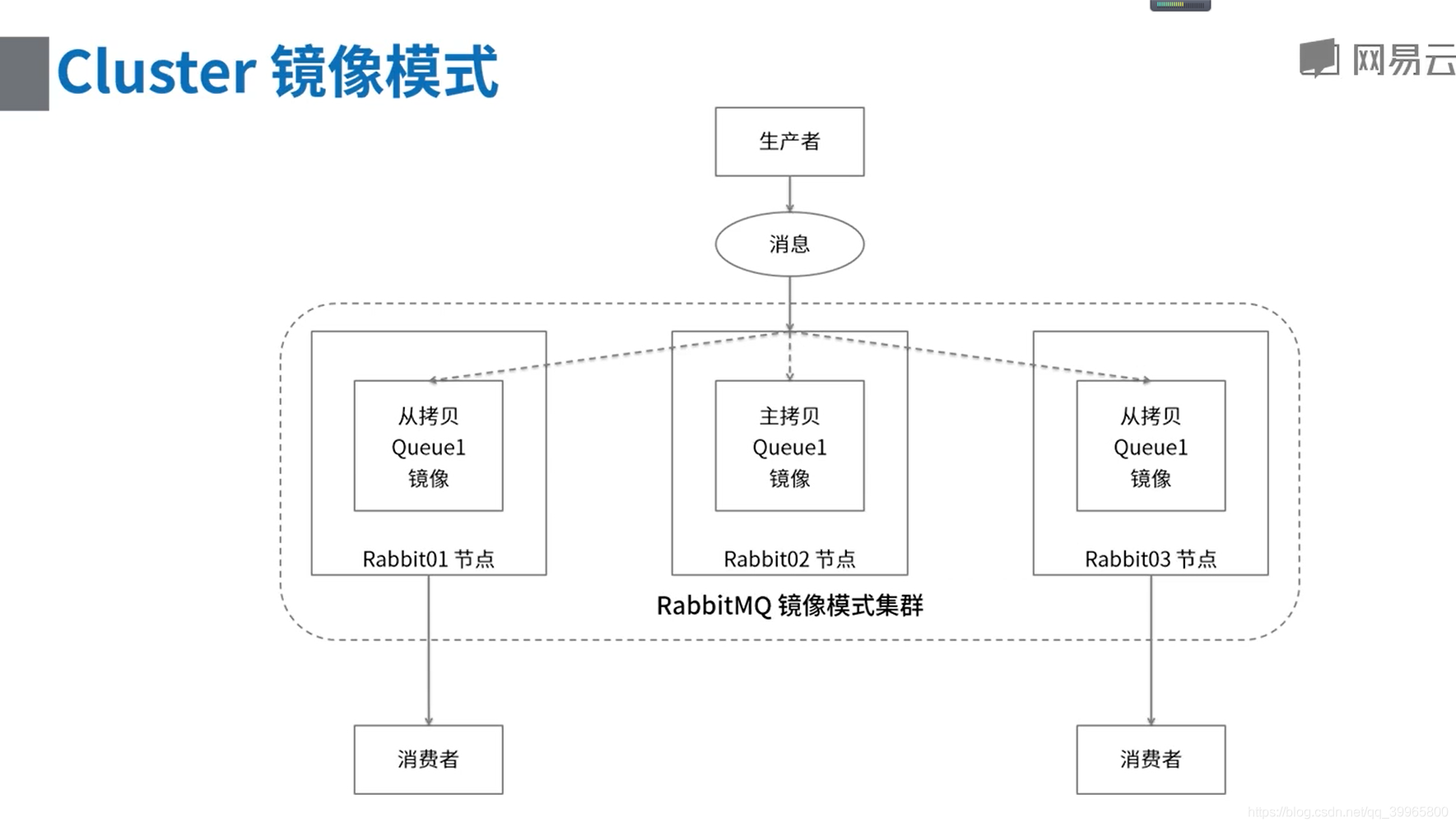
镜像队列的实现
同步信息实现高可用
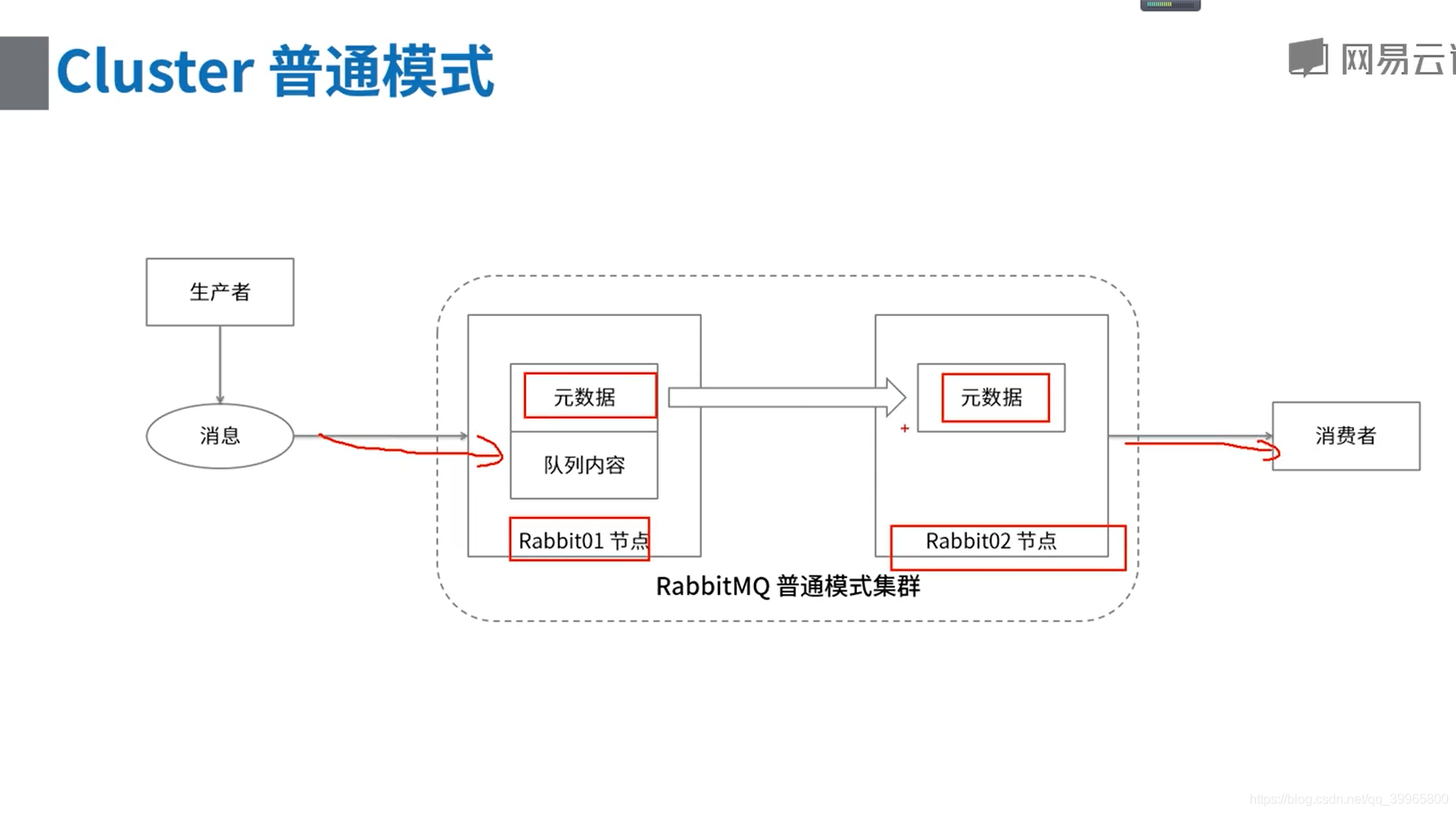
镜像队列模式集群
- 镜像队列属于RabbitMQ 的高可用方案,见:https://www.rabbitmq.com/ha.html#mirroring-arguments
- 通过前面的步骤搭建的集群属于普通模式集群,是通过共享元数据实现集群
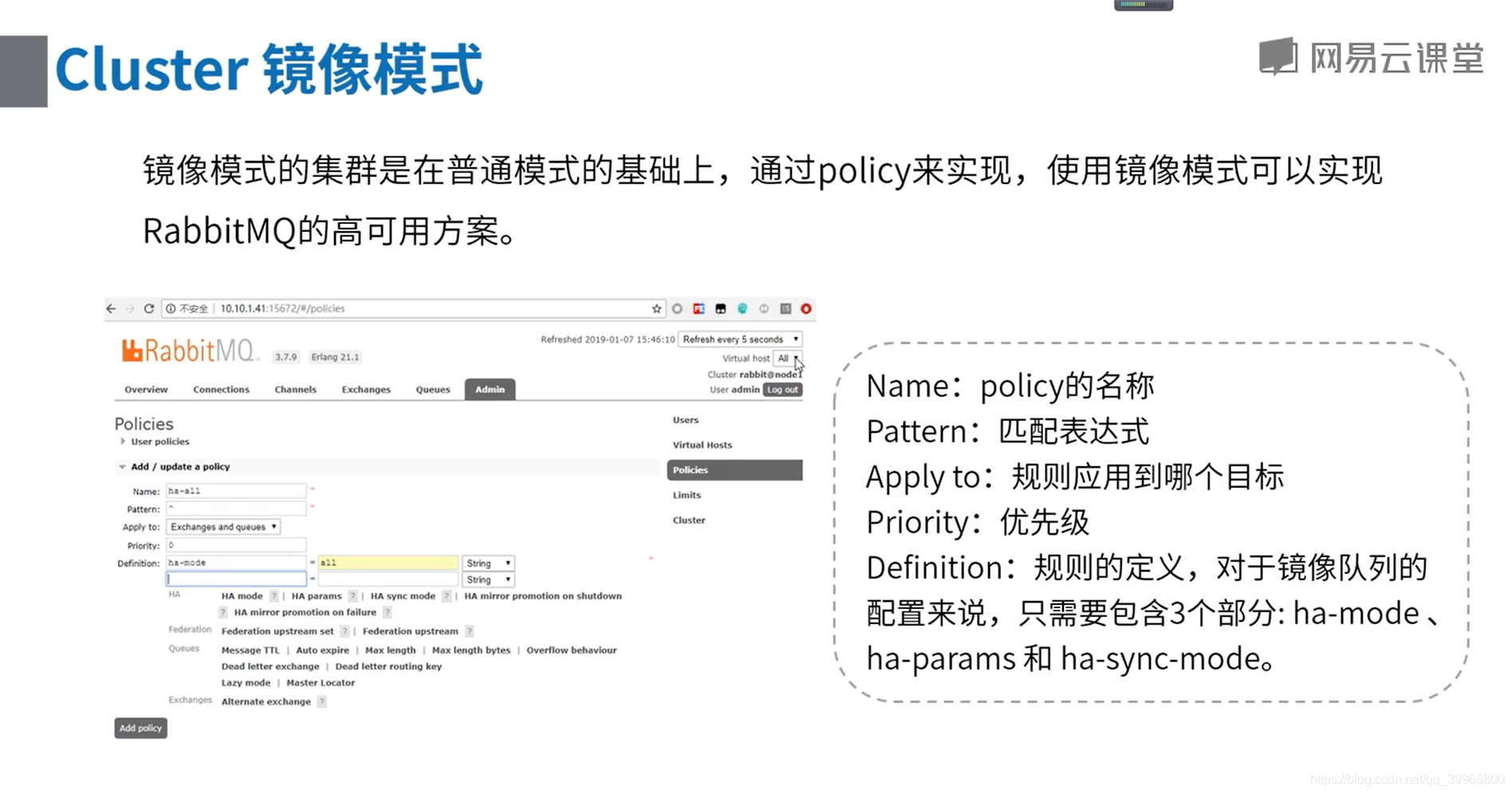
开启镜像队列模式需要在管理页面添加策略,添加方式:
- 进入管理页面 -> Admin -> Policies(在页面右侧)-> Add / update a policy
在表单中填入:

参数说明
name: 策略名称,如果使用已有的名称,保存后将会修改原来的信息
Apply to:策略应用到什么对象上
Pattern:策略应用到对象时,对象名称的匹配规则(正则表达式)
Priority:优先级,数值越大,优先级越高,相同优先级取最后一个
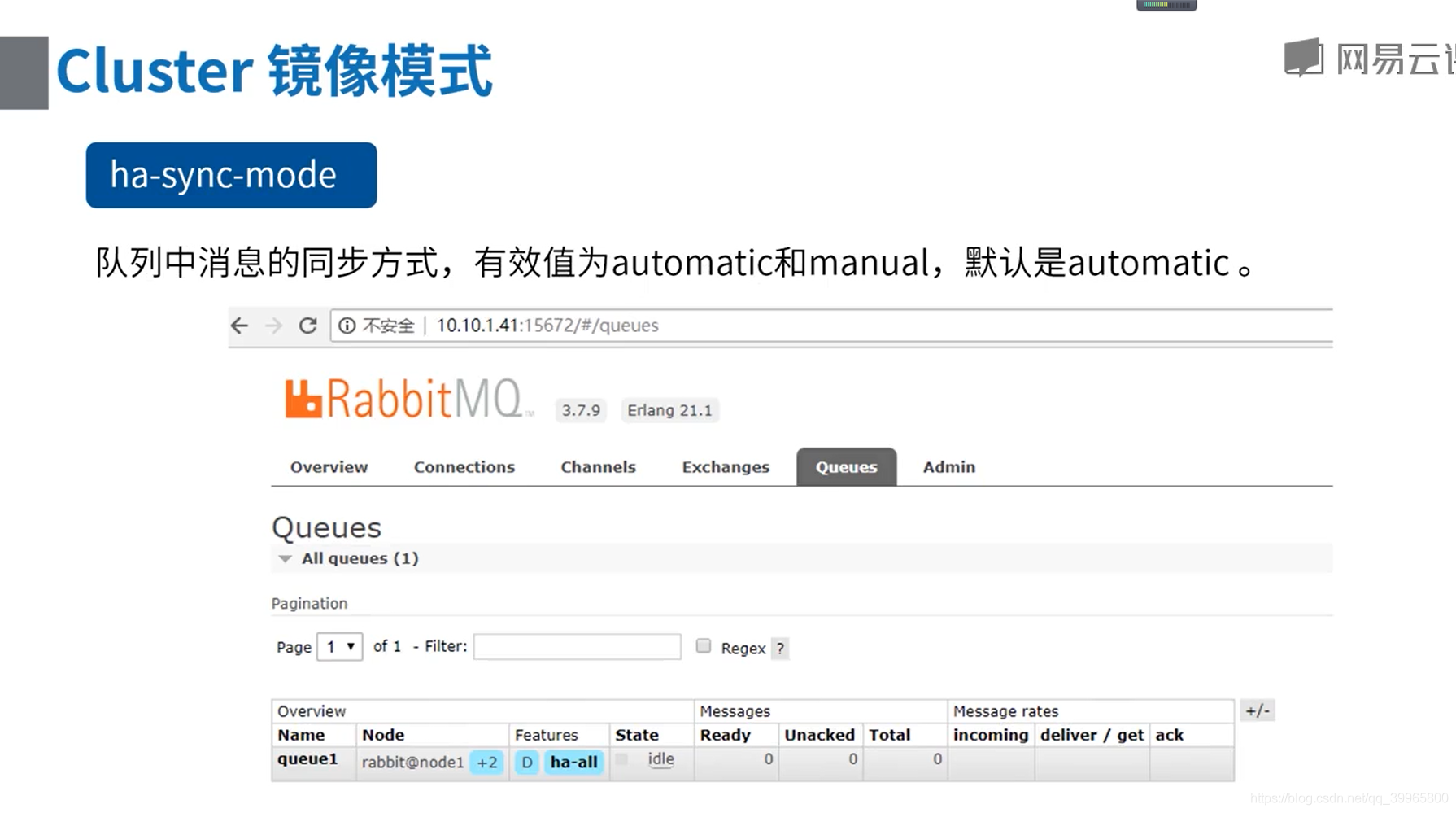
Definition:策略定义的类容,对于镜像队列的配置来说,只需要包含3个部分: ha-mode 、ha-params 和 ha-sync-mode。其中,ha-sync-mode是同步的方式,自动还是手动,默认是自动。ha-mode 和 ha-params 组合使用。组合方式如下:

镜像队列模式相比较普通模式,镜像模式会占用更多的带宽来进行同步,所以镜像队列的吞吐量会低于普通模式
- 但普通模式不能实现高可用,某个节点挂了后,这个节点上的消息将无法被消费,需要等待节点启动后才能被消费。
可以查看rabitmq的日志文件查出错误

常用命令






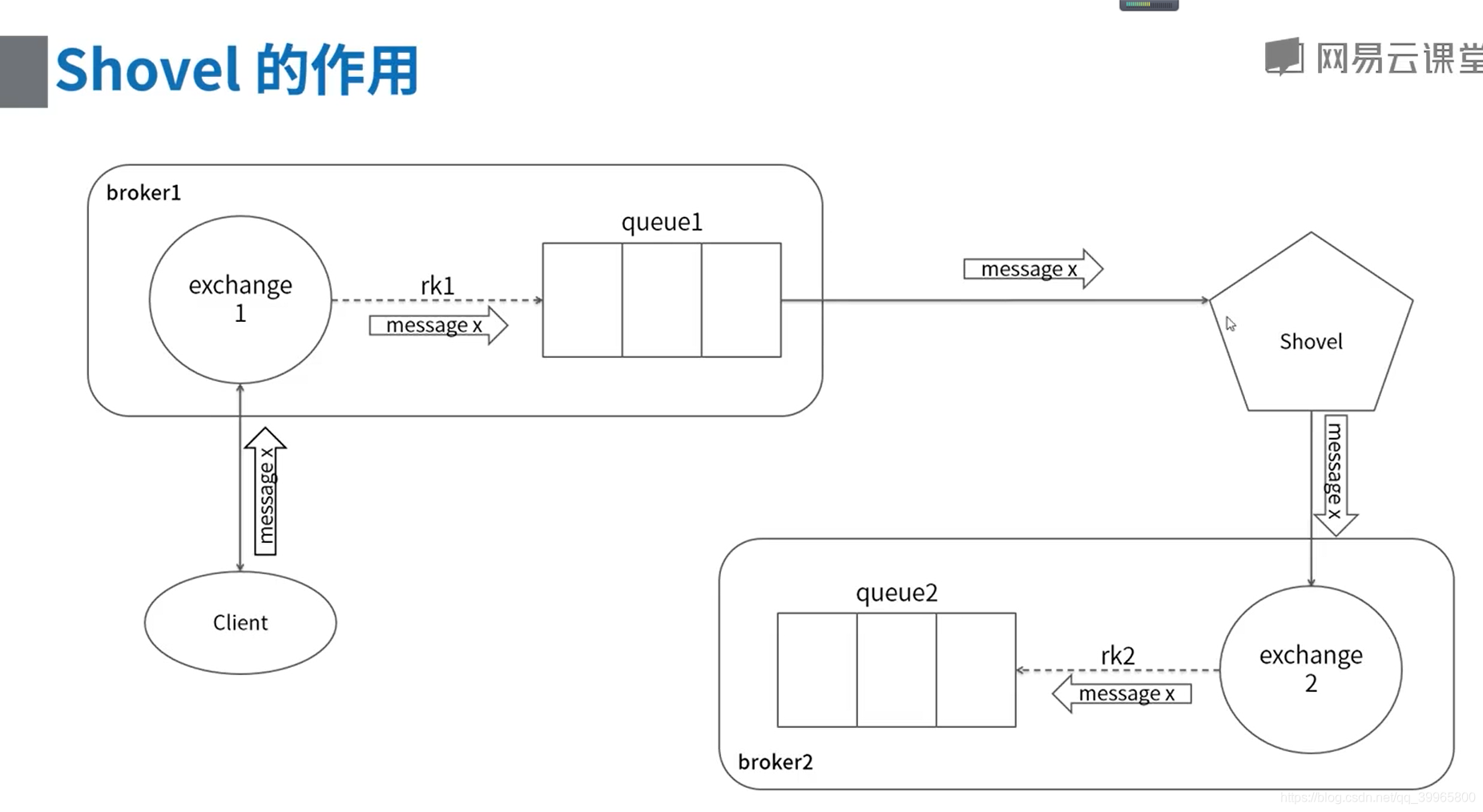
RabbitMQ高可用集群方案

单点失效会存在










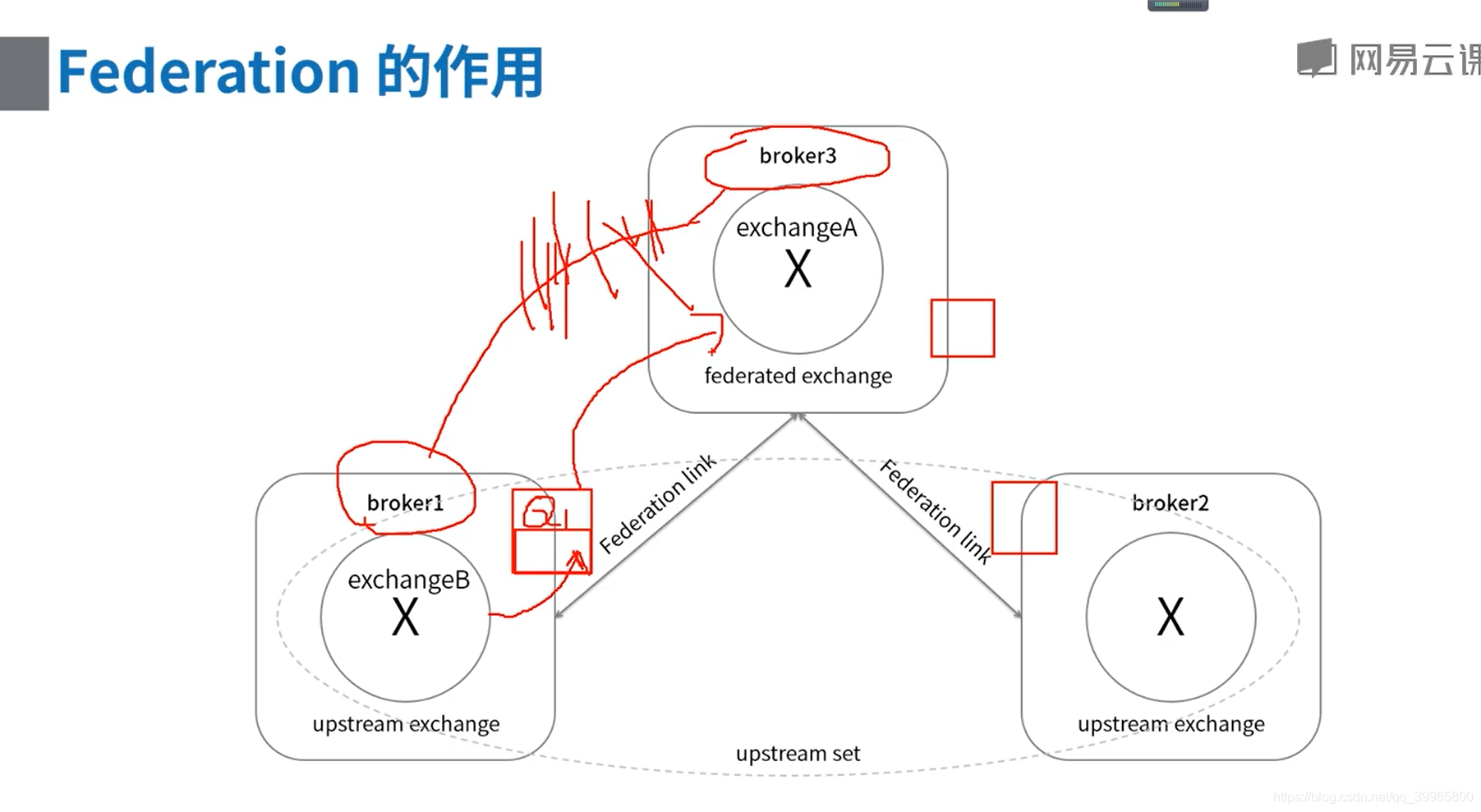
由插件负责同步,但会出现数据不一致



消息中间件-RabbitMQ集群和高可用的更多相关文章
- RabbitMQ 集群与高可用配置
集群概述 通过 Erlang 的分布式特性(通过 magic cookie 认证节点)进行 RabbitMQ 集群,各 RabbitMQ 服务为对等节点,即每个节点都提供服务给客户端连接,进行消息发送 ...
- (转)RabbitMQ 集群与高可用配置
集群概述 环境 配置步骤 集群概述 通过 Erlang 的分布式特性(通过 magic cookie 认证节点)进行 RabbitMQ 集群,各 RabbitMQ 服务为对等节点,即每个节点都提供服务 ...
- centos7 rabbitmq集群搭建+高可用
环境 [root@node1 ~]# cat /etc/redhat-release CentOS Linux release (Core) [root@node1 ~]# uname -r -.el ...
- RabbitMQ集群和高可用配置
概述 RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python.Ruby..NET.Java.JMS.C.PHP.ActionScript.XMPP. ...
- Rabbitmq安装、集群与高可用配置
历史: RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有很多 ...
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案(转)
1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代理服务器,支持安 ...
- 15套java架构师、集群、高可用、高可扩展、高性能、高并发、性能优化、Spring boot、Redis、ActiveMQ、Nginx、Mycat、Netty、Jvm大型分布式项目实战视频教程
* { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架构师.集群.高可用.高可扩展. ...
- 15套java架构师、集群、高可用、高可扩 展、高性能、高并发、性能优化Redis、ActiveMQ、Nginx、Mycat、Netty、Jvm大型分布式项目实战视频教程
* { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架构师.集群.高可用.高可扩 展 ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
随机推荐
- node初体验(一)
1.node.js是一个构建在chrome V8引擎上的javascript运行环境 2.node.js特点:单线程.事件驱动.非阻塞IO模型.轻量 3.node.js是单线程的(多个请求都是一个线程 ...
- net里面using的使用
起初using就明白一个作用 那就是引用命名空间.当面试官听到我回答这个问题的时候,马上就还问我,还有什么作用?我就只能摇头了,今天在网上看了下using的作用. 1.using指令.using + ...
- redis环境配置
1.解压redis压缩包 tar -zxvf redis-5.0.7 2. 基本环境安装 进入解压后的目录 安装yum(cents需要 其它版本Linux可能不适用yum用其它工具)ubuntu:ap ...
- web前端学习笔记(python)(一)
瞎JB搞]感觉自己全栈了,又要把数据库里面的内容,以web形式展示出来,并支持数据操作.占了好多坑.....慢慢填(主要参考廖雪峰的官网,不懂的再百度) 一.web概念 Client/Server模式 ...
- FutureTask源码分析(JDK7)
总览 A cancellable asynchronous computation. This class provides a base implementation of {@link Futur ...
- POJ-3268(来回最短路+dijkstra算法)
Silver Cow Party POJ-3268 这题也是最短路的模板题,只不过需要进行两次求解最短路,因为涉及到来回的最短路之和. 该题的求解关键是:求解B-A的最短路时,可以看做A是起点,这就和 ...
- 太上老君的炼丹炉之分布式 Quorum NWR
分布式系列文章: 1.用三国杀讲分布式算法,舒适了吧? 2.用太极拳讲分布式理论,真舒服! 3.诸葛亮 VS 庞统,拿下 Paxos 共识算法 4.用动图讲解分布式 Raft 5.韩信大招:一致性哈希 ...
- Spring Security 整合 微信小程序登录的思路探讨
1. 前言 原本打算把Spring Security中OAuth 2.0的机制讲完后,用小程序登录来实战一下,发现小程序登录流程和Spring Security中OAuth 2.0登录的流程有点不一样 ...
- Ubuntu 18.04下Intel SGX应用程序程序开发——获得OCALL调用的返回值
本文中,我们介绍在Enclave函数中调用不可信OCALL函数,并获得OCALL函数的返回值. 1. 复制SampleEnclave示例并建立自己的OcallRetSum项目 SampleEnclav ...
- 精确率precession和召回率recall
假设有两类样本,A类和B类,我们要衡量分类器分类A的能力. 现在将所有样本输入分类器,分类器从中返回了一堆它认为属于A类的样本. 召回率:分类器认为属于A类的样本里,真正是A类的样本数,占样本集中所有 ...