「MySql高级查询与编程」练习:企业员工管理
题目:企业员工管理
一、语言和环境
1.实现语言:SQL。
2.开发环境:MySQL,navicat for mysql。
二、题目(100分):
1、创建数据库及数据表:
(1)创建数据库,名称为db_emp;
(2)创建数据表t_emp(员工表)、t_dept(部门表)、t_salary(薪资表)。
表1 t_emp(员工表)
| 字段列名 | 含义 | 数据类型 | 长度 | 允许为空 | 约束 |
|---|---|---|---|---|---|
| empId | 员工编号 | int | - | no | 主键、自增长 |
| empName | 员工姓名 | Varchar | 30 | No | |
| gender | 员工性别 | Char | 1 | No | |
| age | 员工年龄 | Int | 4 | no | |
| deptId | 部门编号 | Int | 6 | No | |
| intDate | 入职日期 | dateTime | No | ||
| tel | 联系电话 | Varchar | 15 | Yes | 唯一 |
create table t_emp (
empid int(11) not null auto_increment,
empname varchar(30) not null,
gender char(1) not null,
age int(4) not null,
deptid int(6) not null,
intdate datetime(0) null,
tel varchar(15) null,
primary key (empid),
unique index tel(tel)
);
表2 t_dept部门表
| 字段列名 | 含义 | 数据类型 | 长度 | 允许为空 | 约束 |
|---|---|---|---|---|---|
| id | 部门编号 | Int | - | no | 主键、自增长 |
| deptName | 部门名称 | Varchar | 30 | No |
create table t_dept (
id int(11) not null auto_increment,
deptname varchar(30) not null,
primary key (id)
);
表3 t_salary薪资表
| 字段列名 | 含义 | 数据类型 | 长度 | 允许为空 | 约束 |
|---|---|---|---|---|---|
| id | 记录编号 | Int | - | 主键、自增长 | |
| emp_id | 员工编号 | Int | 6 | No | |
| salary | 基本薪资 | Decimal | 8 | No | 保留2位小数,默认值为0 |
| Bonus | 绩效奖金 | Decimal | 8 | yes | 保留2位小数,默认值为0 |
create table t_salary (
id int(11) not null,
emp_id int(6) not null,
salary decimal(8, 2) not null default 0.00,
bonus decimal(8, 2) null default 0.00,
primary key (id)
);
(3)添加测试数据:
t_emp(员工表)
| empid | empName | gender | age | deptId | inDate | tel |
|---|---|---|---|---|---|---|
| 1001 | 张三 | 男 | 25 | 1 | 2020-01-01 15:07:59 | 13977641234 |
| 1002 | 李四 | 女 | 21 | 2 | 2020-03-10 00:00:00 | 14787651234 |
| 1003 | 王五 | 男 | 30 | 1 | 2015-01-01 00:00:00 | 15998761234 |
| 1004 | 赵六 | 男 | 17 | 1 | 2018-10-24 00:00:00 | 15877931234 |
| 1005 | 田七 | 女 | 26 | 3 | 2019-09-09 00:00:00 | 18887641234 |
| 1006 | 贺老三 | 男 | 36 | 2 | 2016-01-15 00:00:00 | 17377641790 |
| 1007 | 高晓苑 | 女 | 28 | 4 | 2020-01-02 00:00:00 | 15973641230 |
| 1008 | 吴三 | 男 | 21 | 1 | 2022-11-12 00:00:00 | 15555115475 |
insert into `t_emp` values (1001, '张三', '男', 25, 1, '2020-01-01 15:07:59', '13977641234');
insert into `t_emp` values (1002, '李四', '女', 21, 2, '2020-03-10 00:00:00', '14787651234');
insert into `t_emp` values (1003, '王五', '男', 30, 1, '2015-01-01 00:00:00', '15998761234');
insert into `t_emp` values (1004, '赵六', '男', 17, 1, '2018-10-24 00:00:00', '15877931234');
insert into `t_emp` values (1005, '田七', '女', 26, 3, '2019-09-09 00:00:00', '18887641234');
insert into `t_emp` values (1006, '贺老三', '男', 36, 2, '2016-01-15 00:00:00', '17377641790');
insert into `t_emp` values (1007, '高晓苑', '女', 28, 4, '2020-01-02 00:00:00', '15973641230');
insert into `t_emp` values (1008, '吴三', '男', 21, 1, '2022-11-12 00:00:00', '15555115475');
t_dept(部门表)
| id | deptName |
|---|---|
| 1 | 技术部 |
| 2 | 产品部 |
| 3 | 运营部 |
| 4 | 人事部 |
insert into `t_dept` values (1, '技术部');
insert into `t_dept` values (2, '产品部');
insert into `t_dept` values (3, '运营部');
insert into `t_dept` values (4, '人事部');
t_salary(薪资表)
| id | emp_id | saiary | bonus |
|---|---|---|---|
| 1 | 1001 | 5000 | 1500 |
| 2 | 1002 | 3500 | 800 |
| 3 | 1003 | 4500 | 2000 |
| 4 | 1004 | 6000 | 4000 |
| 5 | 1005 | 5200 | 1700 |
| 6 | 1006 | 4800 | 3000 |
| 7 | 1007 | 3000 | 1200 |
| 8 | 1008 | 12000 | 3100 |
insert into `t_salary` values (1, 1001, 5000.00, 1500.00);
insert into `t_salary` values (2, 1002, 3500.00, 800.00);
insert into `t_salary` values (3, 1003, 4500.00, 2000.00);
insert into `t_salary` values (4, 1004, 6000.00, 4000.00);
insert into `t_salary` values (5, 1005, 5200.00, 1700.00);
insert into `t_salary` values (6, 1006, 4800.00, 3000.00);
insert into `t_salary` values (7, 1007, 3000.00, 1200.00);
insert into `t_salary` values (8, 1008, 12000.00, 3100.00);
2、数据操作:
a) 左连接形式查询入职时间最早的4位员工信息,需要显示员工姓名,入职日期,部门,联系电话。(10分)
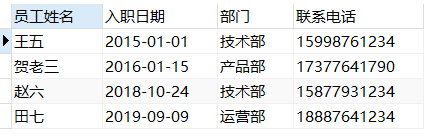
select empName 员工姓名,DATE_FORMAT(intDate,'%Y-%m-%d') 入职日期,deptName 部门,tel 联系电话
from t_emp e left join t_dept d
on e.deptid=d.id order by intDate asc limit 0,4;
b) 根据员工部门统计人数、最高基本薪资、最低基本薪资和每个部门的平均基本薪资,并按实际薪资金额升序显示(15分)
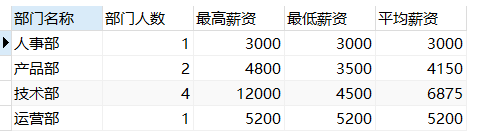
select deptName 部门名称,count(*) 部门人数,max(salary) 最高薪资,min(salary) 最低薪资,avg(salary) 平均薪资
from t_dept d,t_emp e,t_salary s where e.deptId=d.id and s.emp_id=e.empId
group by deptName order by (salary+Bonus) asc;
c) 创建视图并使用子查询的方式查询薪资大于“产品部”平均基本薪资的员工信息,要求输出员工姓名和基本薪资。(15分)
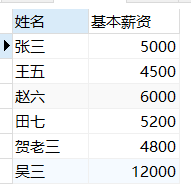
create view view_name as
select empName 姓名,salary 基本薪资 from t_emp e,t_salary s
where s.emp_id=e.empId and salary >
all(select avg(salary) from t_dept d,t_emp e,t_salary s where e.deptId=d.id and s.emp_id=e.empId and d.id=2);
也可以通过 navicat 直接创建


d) 创建一个名为 proc_Max_salary 的存储过程,其将获取指定部门的最高薪资,例如技术部的最高薪资如下(20分)

创建存储过程:
delimiter $$
create procedure proc_Max_salary(
in _depName varchar(20),
out _salary decimal )
reads sql data
begin
select max(salary) into _salary
from t_dept d,t_emp e,t_salary s
where e.deptId=d.id and s.emp_id=e.empId and d.deptName=_depName;
end
$$
delimiter ;
查询:
set @depName= '技术部';
call proc_Max_salary(@depName, @_salary);
select concat(@depName,' 部门的最高的底薪是 ',@_salary,' 元 ');
也可以通过 navicat 直接创建


e) 创建一个名为v_sum_salary的视图,用于查看出每个员工的总薪资(基本薪资+绩效)。(10分)

create view v_sum_salary as
select empName 员工姓名,salary 基本薪资,bonus 效绩,(salary+bonus) 最终工资
from t_dept d,t_emp e,t_salary s
where e.deptId=d.id and s.emp_id=e.empId;
f) 员工信息管理平台浏览员工信息时需要按年龄升序显示,为了提高检索效率,请在在员工表年龄列上创建索引,请写出创建索引的sql语句。(10分)

alter table t_emp add index index_age(age) using btree;

3、推荐实现步骤
(1)打开Navicat,创建数据库db_emp;
(2)创建数据表t_emp(员工表)、t_dept(部门表)、t_salary(薪资表),建表时注意主键、外健以及相关约束、类型和长度、并根据以上表格数据进行数据的录入(可用sql语句,也可使用navicat直接填入数据)。
(3)按要求完成查询和修改将sql语句根据相应的备注信息保存查询或视图;sql语句可以外联或子查询,方法不做限定;建立视图可以直接用navicat视图工具也可以写代码创建。
全部代码:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for t_dept
-- ----------------------------
DROP TABLE IF EXISTS `t_dept`;
CREATE TABLE `t_dept` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`deptName` varchar(30) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_dept
-- ----------------------------
INSERT INTO `t_dept` VALUES (1, '技术部');
INSERT INTO `t_dept` VALUES (2, '产品部');
INSERT INTO `t_dept` VALUES (3, '运营部');
INSERT INTO `t_dept` VALUES (4, '人事部');
-- ----------------------------
-- Table structure for t_emp
-- ----------------------------
DROP TABLE IF EXISTS `t_emp`;
CREATE TABLE `t_emp` (
`empId` int(11) NOT NULL AUTO_INCREMENT,
`empName` varchar(30) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`gender` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`age` int(4) NOT NULL,
`deptId` int(6) NOT NULL,
`intDate` datetime(0) NULL DEFAULT NULL,
`tel` varchar(15) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`empId`) USING BTREE,
UNIQUE INDEX `tel`(`tel`) USING BTREE,
INDEX `index_age`(`age`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1009 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_emp
-- ----------------------------
INSERT INTO `t_emp` VALUES (1001, '张三', '男', 25, 1, '2020-01-01 15:07:59', '13977641234');
INSERT INTO `t_emp` VALUES (1002, '李四', '女', 21, 2, '2020-03-10 00:00:00', '14787651234');
INSERT INTO `t_emp` VALUES (1003, '王五', '男', 30, 1, '2015-01-01 00:00:00', '15998761234');
INSERT INTO `t_emp` VALUES (1004, '赵六', '男', 17, 1, '2018-10-24 00:00:00', '15877931234');
INSERT INTO `t_emp` VALUES (1005, '田七', '女', 26, 3, '2019-09-09 00:00:00', '18887641234');
INSERT INTO `t_emp` VALUES (1006, '贺老三', '男', 36, 2, '2016-01-15 00:00:00', '17377641790');
INSERT INTO `t_emp` VALUES (1007, '高晓苑', '女', 28, 4, '2020-01-02 00:00:00', '15973641230');
INSERT INTO `t_emp` VALUES (1008, '吴三', '男', 21, 1, '2022-11-12 00:00:00', '15555115475');
-- ----------------------------
-- Table structure for t_salary
-- ----------------------------
DROP TABLE IF EXISTS `t_salary`;
CREATE TABLE `t_salary` (
`id` int(11) NOT NULL,
`emp_id` int(6) NOT NULL,
`salary` decimal(8, 2) NOT NULL DEFAULT 0.00,
`Bonus` decimal(8, 2) NULL DEFAULT 0.00,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_salary
-- ----------------------------
INSERT INTO `t_salary` VALUES (1, 1001, 5000.00, 1500.00);
INSERT INTO `t_salary` VALUES (2, 1002, 3500.00, 800.00);
INSERT INTO `t_salary` VALUES (3, 1003, 4500.00, 2000.00);
INSERT INTO `t_salary` VALUES (4, 1004, 6000.00, 4000.00);
INSERT INTO `t_salary` VALUES (5, 1005, 5200.00, 1700.00);
INSERT INTO `t_salary` VALUES (6, 1006, 4800.00, 3000.00);
INSERT INTO `t_salary` VALUES (7, 1007, 3000.00, 1200.00);
INSERT INTO `t_salary` VALUES (8, 1008, 12000.00, 3100.00);
-- ----------------------------
-- View structure for view_name
-- ----------------------------
DROP VIEW IF EXISTS `view_name`;
CREATE ALGORITHM = UNDEFINED DEFINER = `root`@`localhost` SQL SECURITY DEFINER VIEW `view_name` AS select `e`.`empName` AS `姓名`,`s`.`salary` AS `基本薪资` from (`t_emp` `e` join `t_salary` `s`) where ((`s`.`emp_id` = `e`.`empId`) and `s`.`salary` > all (select avg(`s`.`salary`) from ((`t_dept` `d` join `t_emp` `e`) join `t_salary` `s`) where ((`e`.`deptId` = `d`.`id`) and (`s`.`emp_id` = `e`.`empId`) and (`d`.`id` = 2))));
-- ----------------------------
-- View structure for v_sum_salary
-- ----------------------------
DROP VIEW IF EXISTS `v_sum_salary`;
CREATE ALGORITHM = UNDEFINED DEFINER = `root`@`localhost` SQL SECURITY DEFINER VIEW `v_sum_salary` AS select `e`.`empName` AS `员工姓名`,`s`.`salary` AS `基本薪资`,`s`.`Bonus` AS `效绩`,(`s`.`salary` + `s`.`Bonus`) AS `最终工资` from ((`t_dept` `d` join `t_emp` `e`) join `t_salary` `s`) where ((`e`.`deptId` = `d`.`id`) and (`s`.`emp_id` = `e`.`empId`));
-- ----------------------------
-- Procedure structure for proc_Max_salary
-- ----------------------------
DROP PROCEDURE IF EXISTS `proc_Max_salary`;
delimiter ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_Max_salary`(
in _depName varchar(20),
out _salary decimal )
READS SQL DATA
begin
select max(salary) into _salary from t_dept d,t_emp e,t_salary s where e.deptId=d.id and s.emp_id=e.empId and d.deptName=_depName;
end
;;
delimiter ;
SET FOREIGN_KEY_CHECKS = 1;
「MySql高级查询与编程」练习:企业员工管理的更多相关文章
- MySQL高级查询与编程作业目录 (作业笔记)
MySQL高级查询与编程笔记 • [目录] 第1章 数据库设计原理与实战 >>> 第2章 数据定义和操作 >>> 2.1.4 使用 DDL 语句分别创建仓库表.供应 ...
- MySQL高级查询与编程笔记 • 【目录】
章节 内容 实践练习 MySQL高级查询与编程作业目录(作业笔记) 第1章 MySQL高级查询与编程笔记 • [第1章 数据库设计原理与实战] 第2章 MySQL高级查询与编程笔记 • [第2章 数据 ...
- MySQL高级查询与编程笔记 • 【第4章 MySQL编程】
全部章节 >>>> 本章目录 4.1 用户自定义变量 4.1.1 用户会话变量 4.1.2 用户会话变量赋值 4.1.3 重置命令结束标记 4.1.4 实践练习 4.2 存 ...
- MySQL高级查询和编程基础
第一章 数据库设计 一.数据需求分析: 数据需求分析是为后续概念设计和逻辑结构设计做准备. 结构:(1)对现实世界要处理的对象进行详细的调查. (2)收集基础数.据. (3)对所收集的数据进行处理. ...
- MySQL高级查询与编程笔记 • 【第5章 常见数据库对象】
全部章节 >>>> 本章目录 5.1 视图 5.1.1 视图的定义 5.1.2 视图的优点 5.1.3 视图的创建和使用 5.1.4 利用视图解决数据库的复杂应用 5.1. ...
- 云南农业职业技术学院 - 互联网技术学院 - 美和易思《MYSQL 高级查询与编程》 综合机试试卷
数据库及试题文档下载:https://download.csdn.net/download/weixin_44893902/14503097 目录 题目:电商平台 mysql 数据库系统管理 一. 语 ...
- 《MYSQL高级查询与编程》综合机试试卷 - 云南农职美和易思
题目:银行mysql数据库系统管理 目录 题目:银行mysql数据库系统管理 一.语言和环境 二.题目(100分): 功能需求: 要求: 三.提交方式 四.评分标准: 五.实现代码: 创建表结构: 插 ...
- MySQL高级查询与编程笔记 • 【第2章 数据定义和操作】
全部章节 >>>> 本章目录 2.1 数据定义语言和数据操作语言 2.1.1 设计"优乐网"数据库 2.1.2 数据定义语言 2.1.3 数据操作语言 ...
- MySQL高级查询与编程笔记 • 【第1章 数据库设计原理与实战】
全部章节 >>>> 本章目录 1.1 数据需求分析 1.1.1 数据需求分析的定义 1.1.2 数据需求分析的步骤和方法 1.1.3 数据流程图 1.1.4 数据字典 1. ...
随机推荐
- Set && Map
ES6 提供了新的数据结构 Set, Map Set成员的值都是唯一的,没有重复的值,Set内的元素是强类型,会进行类型检查. let set = new Set([1, true, '1', 'tr ...
- [PE]结构分析与代码实现
PE结构浅析 知识导向: 程序最开始是存放在磁盘上的,运行程序首先需要申请4GB的内存,将程序从磁盘copy到内存,但不是直接复制,而是进行拉伸处理. 这也就是为什么会有一个文件中地址和一个Virtu ...
- 分配器——allocators
任何容器的构建都离不开分配器,分配器顾名思义就是分割配置内存资源的组件,分配器的效率直接影响力容器的效率. operator new()和malloc() C/C++底层都是通过malloc()调用系 ...
- C++类的定义,成员函数的定义,对象的创建与使用
类是一个模板,可用类生成一系列可用的实例.例如 int B就是生成了一个符合int的数据B,类也是一样,使用类名就可以直接生成一个实例, 该实例中包含类中所有的数据类型和对这些数据的操作方法. 首先, ...
- 【Linux】【Services】【SaaS】Docker+kubernetes(13. 部署Jenkins/Maven实现代码自动化发布)
1. 简介 Jenkins: 官方网站:https://jenkins.io/ 下载地址:https://jenkins.io/download/ war包下载:http://mirrors.jenk ...
- SpringBoot服务间使用自签名证书实现https双向认证
SpringBoot服务间使用自签名证书实现https双向认证 以服务server-one和server-two之间使用RestTemplate以https调用为例 一.生成密钥 需要生成server ...
- MySQL——基础查询与条件查询
基础查询 /* 语法: select 查询列表 from 表名; 类似于:System.out.println(打印东西); 1.查询列表可以是:表中的字段.常量值.表达式.函数 2.查询的结果是一个 ...
- not_the_same_3dsctf_2016
老样子查看程序开启的保护 可以看到程序是32位的程序开启了nx保护,把程序放入ida编译一下 shift+f12可以看到flag.txt,我们用ctrl+x跟随一下 看到程序,直接想到的就是通过溢出获 ...
- 一站式云原生在线研发平台 StarOS 种子用户邀请计划正式开启!
云时代的开发者,你好: 你是否也曾畅想过,关于云的未来? 不是作为消费者,也不是作为企业,是对于开发者而言,云会变成什么样. 同为开发者,我们常在想,我们开发了一个又一个应用,让太多人因服务在线而获益 ...
- Spring Boot发布2.6.2、2.5.8:升级log4j2到2.17.0
12月22日,Spring官方发布了Spring Boot 2.5.8(包括46个错误修复.文档改进和依赖项升级)和2.6.2(包括55个错误修复.文档改进和依赖项升级). 这两个版本均为缺陷修复版本 ...