python刷题第二周
1:
第3章-5 字符转换 (15 分) 本题要求提取一个字符串中的所有数字字符('0'……'9'),将其转换为一个整数输出。
输入格式: 输入在一行中给出一个不超过80个字符且以回车结束的字符串。
输出格式: 在一行中输出转换后的整数。题目保证输出不超过长整型范围。
我的代码:
import re
string = input()
res = re.findall("[0-9]", string)
for i in range(len(res)):
print(res[i], end="")
我利用了正则表达式中的re.findall函数,将找到的数字放入列表中,最后将列表输出。
经过多次测试,我并没有发现什么问题,但是却有一个测试点无法通过,求大佬解答。
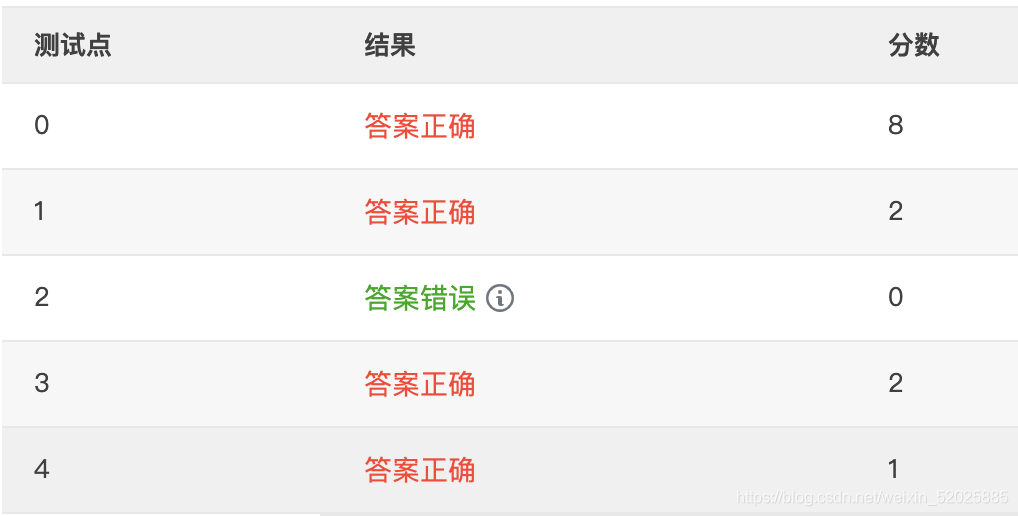
别人的代码:
1.
s = input()
n = ''
for i in s:
if i.isnumeric():
n += i
print(int(n))
这里ta利用了isnumeric()函数来判断字符是不是数字。
2.
s=input()
su=0
for i in range(0,len(s)): #确定好range函数的范围
if "0"<=s[i]<="9":
su=su*10+int(s[i])
print(su)
这里ta简单地通过"0"<=s[i]<="9"来判断该字符是否是数字。
我当时试过0<=s[i]<=9,但是执行时会报错说str类型和int类型不能比较,所以以后我会采用ta的方法。
2:
第3章-9 字符串转换成十进制整数 (15 分)
输入一个以#结束的字符串,本题要求滤去所有的非十六进制字符(不分大小写),组成一个新的表示十六进制数字的字符串,然后将其转换为十进制数后输出。如果在第一个十六进制字符之前存在字符“-”,则代表该数是负数。输入格式: 输入在一行中给出一个以#结束的非空字符串。
输出格式: 在一行中输出转换后的十进制数。题目保证输出在长整型范围内。
代码:
s=input()
su=0
for i in range(0,len(s)+1):
if s[i]=="#":
break
if "0"<=s[i]<="9":
su=su*16+int(s[i])
elif "a"<=s[i]<="f":
su=su*16+int(s[i],16)
elif "A"<=s[i]<="F":
su=su*16+int(s[i],16)
for j in range(0,len(s)):
if "0"<=s[j]<="9" or "a"<=s[j]<="f" or "A"<=s[j]<="F":
break
if j>s.find("-"):
su=-su
print(su)
思考:
我一开始想的是先把十六进制之外的数先删除,然后再对剩下的数进行进制转换,但是遇到了很多困难,比较难实现。
如果把遇到的每个十六进制数都加起来,就相对比较简单。
3:
第3章-13 字符串替换 (15 分) 本题要求编写程序,将给定字符串中的大写英文字母按以下对应规则替换:
原字母 对应字母 A Z B Y C X D W … … X C Y B Z A 输入格式:
输入在一行中给出一个不超过80个字符、并以回车结束的字符串。输出格式: 输出在一行中给出替换完成后的字符串。
代码:
num = input()
for i in range(len(num)):
if (num[i] >= "A") and (num[i] <= "Z"):
print(chr(155-ord(num[i])), end="")#ord():将字符转换成ascii码,chr()将整数转换成对应的数字
else:
print(num[i], end="")
我学到了:
1.主要利用了转换前后的字母的ascii码的和都为155。
2.ord()函数将字符转换成ascii码
3.char()将ascii码转换为字母
3:
第3章-19 找最长的字符串 (15 分) 本题要求编写程序,针对输入的N个字符串,输出其中最长的字符串。
输入格式: 输入第一行给出正整数N;随后N行,每行给出一个长度小于80的非空字符串,其中不会出现换行符,空格,制表符。
输出格式: 在一行中用以下格式输出最长的字符串:
The longest is: 最长的字符串
代码:
n = int(input())
result = ""
number = 0
for i in range(n):
string = input()
if len(string)>number:
number = len(string)
result = string
print("The longest is: %s"%result)
思考:
1.我开始的方向错误了,想着收入n后,写一个for循环将n个string放入列表中,但是我发现这样比较麻烦。
4:
第3章-16 删除重复字符 (20 分) 本题要求编写程序,将给定字符串去掉重复的字符后,按照字符ASCII码顺序从小到大排序后输出。
输入格式: 输入是一个以回车结束的非空字符串(少于80个字符)。
输出格式: 输出去重排序后的结果字符串。
代码:
ls = input()
ls = list(ls)
ls = sorted(ls)
i = 0
while i < len(ls) - 1:
if ls[i] == ls[i + 1]:
ls.pop(i)
i -= 1
i += 1
print("".join(ls))
思考:
1.这道题的思路很简单,就是先把字符串分解为字符数组,然后再把又重复的字符删除就可以了。
2.但是有个易错点是:如果对列表有删除的操作,不能用for语句,因为for语句中的i是固定增加的,会导致检索过程中元素的遗漏,使用while循环是更好的选择。
5:
第3章-18 输出10个不重复的英文字母 (30 分) 随机输入一个字符串,把最左边的10个不重复的英文字母(不区分大小写)挑选出来。
如没有10个英文字母,显示信息“not found”输入格式: 在一行中输入字符串
输出格式: 在一行中输出最左边的10个不重复的英文字母或显示信息“not found"
我的代码:
ls = input()
ls = list(ls)
res = []
for i in range(len(ls)):
if "A" <= ls[i] <= "z":
res = "".join(res)
if ls[i].upper() not in res and ls[i].lower() not in res:
res = list(res)
res.append(ls[i])
if len(res) < 10:
print("not found")
else:
print("".join(res))
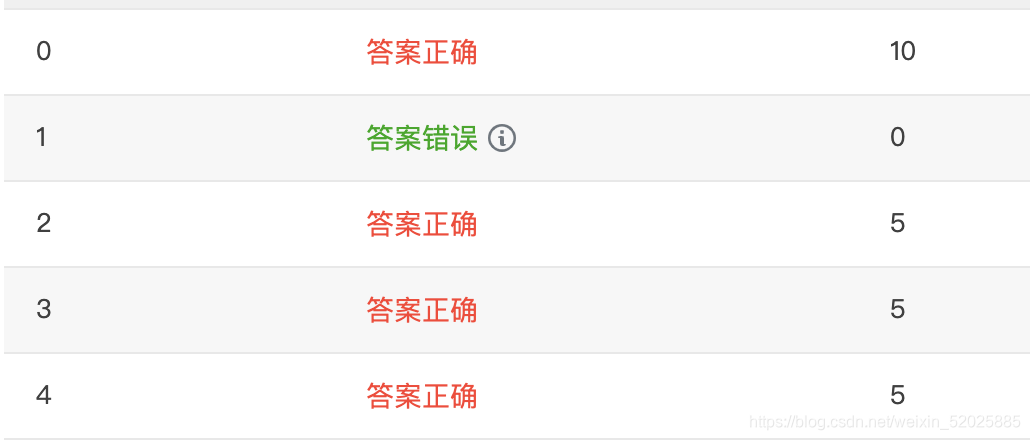
我感觉大概是没问题的,但是却有一个测试点没通过,找不到原因。
ps:我找到原因了!
问题就在于这里:
else:
print("".join(res))
我忘记考虑字符串长度超过10的情况了,如果这样我就会输出超过10个字母,当然错了啦
因此改成这样就对了:
for i in range(0,10):
print(s[i],end="")
别人的代码:
s1=input()
s=list()
count=0
for i in s1:
if i.isalpha() and i.lower() not in s and i.upper() not in s:
s.append(i) #注意一点语法:s=s.append()是初学者易犯的错误
count=count+1
if count<10:
print("not found")
else:
for i in range(0,10):
print(s[i],end="")
思考:
他的思路和我基本一致,但是很明显他写的更简单,因而更不容易出错。
1.他利用了isalpha()函数判断是不是英文字母,这是我没想到的。
2.忘记限制输出的长度了!
本周刷题情况:
python刷题第二周的更多相关文章
- Python 刷题笔记
Python 刷题笔记 本文记录了我在使用python刷题的时候遇到的知识点. 目录 Python 刷题笔记 选择.填空题 基本输入输出 sys.stdin 与input 运行脚本时传入参数 Pyth ...
- 好像leeceode题目我的博客太长了,需要重新建立一个. leecode刷题第二个
376. Wiggle Subsequence 自己没想出来,看了别人的分析. 主要是要分析出升序降序只跟临近的2个决定.虽然直觉上不是这样. 455. 分发饼干 ...
- python刷题第四周
本周有所收获的题目: 第一题: 第4章-17 水仙花数(20 分) (20 分) 水仙花数是指一个N位正整数(N≥3),它的每个位上的数字的N次幂之和等于它本身. 例如:153=1×1×1+5×5×5 ...
- 周刷题第二期总结(Longest Substring Without Repeating Characters and Median of Two Sorted Arrays)
这周前面刷题倒是蛮开心,后面出了很多别的事情和问题就去忙其他的,结果又只完成了最低目标. Lonest Substring Without Repeating Characters: Given a ...
- python刷题第三周
以下是本周有所收获的题目 第一题: 第4章-4 验证"哥德巴赫猜想" (20 分) 数学领域著名的"哥德巴赫猜想"的大致意思是:任何一个大于2的偶数总能表示为两 ...
- python学习笔记第二周
目录 一.基础概念 1.模块 1)os模块 2)sys模块 2.pyc文件 3.数据类型 1)数字 2)布尔值 3)字符串 4.数据运算 5.运算符 6.赋值运算 7.逻辑运算 8.成员运算 9.身份 ...
- leetcode刷题第二天<两数相加>
题目描述 给出两个 非空 的链表用来表示两个非负的整数.其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字. 如果,我们将这两个数相加起来,则会返回一个新的链表来表 ...
- python刷题专用函数。。
无它,非bin()莫属. bin(x) Convert an integer number to a binary string. The result is a valid Python expre ...
- 【python刷题】LRU
什么是LRU? LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰.该算法赋予每个页面一个访问字段,用来记录一个页面自上次 ...
随机推荐
- 入门Kubernetes-StatefulSets
前言: 前面文中对通过DaemonSet.存储资源对象,实现了在指定节点中运行一个守护进程. 在真实的业务场景中,部署的服务都是有状态的.且有数据需要持久化的:那么如何实现呢? 那么接下来学习一种更加 ...
- 【网络编程】TCPIP-7-域名与网络地址
目录 前言 7. 域名与网络地址 7.1 IP 7.2 域名 7.3 DNS 7.4 IP地址与域名之间的转换 7.4.1 利用域名获取IP地址 7.4.2 利用IP地址获取域名 7.4.3 升级版的 ...
- APIO 2007 动物园 题解
链接题面 看清楚找到小数据范围,第一维表示遍历到的栅栏,第二维是五位状态 先预处理每个状态会使多少小朋友高兴 方程是 f[i][j]=max(f[(i&((1<<4)-1))&l ...
- 一招解决微信小程序中的H5缓存问题
一招解决微信小程序中的H5缓存问题1.问题描述开发过程中,为了更新代码方便,往往会在小程序中嵌入H5页面.但问题来了,小程序原生代码更新版本后,简单的从微信中删除或者代码强刷就可以解决缓存问题,但小程 ...
- centos7-同步时间
yum install -y ntp ntpdate ntpdate -u cn.pool.ntp.org # 阿里云ntp ntpdate ntp1.aliyun.com 但这样的同步,只是强制性的 ...
- 6、二进制安装K8s之部署kubectl
二进制安装K8s之部署kubectl 我们把k8s-master 也设置成node,所以先master上面部署node,在其他机器上部署node也适用,更换名称即可. 1.在所有worker node ...
- wpf Button 动态改变效果
<Button x:Name="LearnMore" Grid.Row="6" HorizontalAlignment="Left&quo ...
- 【springcloud】springcloud Greenwich SR4版本笔记
springcloud Greenwich SR4版本笔记 本文只记录实际版本,配置,pom,代码以及注意事项.别的在其他springcloud 的F版本中已有详述. 示例代码地址:https://g ...
- Spring第一课:核心API(三)
以上是Spring的核心部分,其中需要了解的是:BeanFactory.ApplicationContext[FileSystemXmlApplicationContext.ClassPathXmlA ...
- 再过五分钟,你就懂 HTTP 2.0 了!
Hey guys ,各位小伙伴们大家好,这里是程序员 cxuan,欢迎你收看我最新一期的文章. 这篇文章我们来聊一聊 HTTP 2.0,以及 HTTP 2.0 它在 HTTP 1.1 的基础上做了哪些 ...