HDFS初探之旅(二)
6、HDFS API详解
Hadoop中关于文件操作类疾病上全部在“org.apache.hadoop.fs”包中,这些API能够支持的操作包含:打开文件、读写文件、删除文件等。
Hadoop类库中最终面向用户提供的接口类是FileSystem,该类是个抽象类,只能通过该类的get方法得当具体的类。get方法存在几个重载版本,常用的是这个:

该类几乎封装了所有的文件操作,例如mkdir、delete等。综上基本上可以得出操作文件的程序库框架:

6.1 上传本地文件
通过“FileSystem.copyFromLocalFile(Path src, Path dst)”可将本地文件上传到HDFS的指定位置上,其中src和dst均为文件的完成路径。具体事例如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CopyFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
//本地文件
Path src =new Path("D:\\HebutWinOS");
//HDFS为止
Path dst =new Path("/");
hdfs.copyFromLocalFile(src, dst);
System.out.println("Upload to"+conf.get("fs.default.name"));
FileStatus files[]=hdfs.listStatus(dst);
for(FileStatus file:files){
System.out.println(file.getPath());
}
}
}
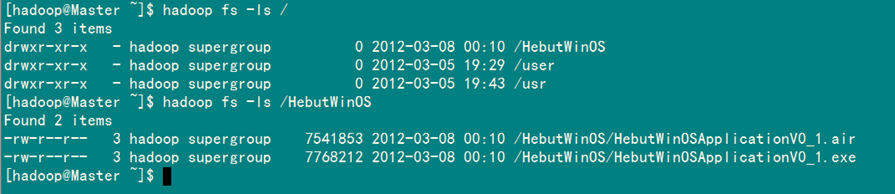
运行结果可以通过控制台、项目浏览器和SecureCRT查看,如下图所示。
1)控制台结果

2)项目浏览器

3)SecureCRT结果
6.2 创建HDFS文件
通过“FileSystem.create(Path f)"可在HDFS上创建文件,其中f为文件的完整路径。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
byte[] buff="hello hadoop world!\n".getBytes();
Path dfs=new Path("/test");
FSDataOutputStream outputStream=hdfs.create(dfs);
outputStream.write(buff,0,buff.length);
}
}
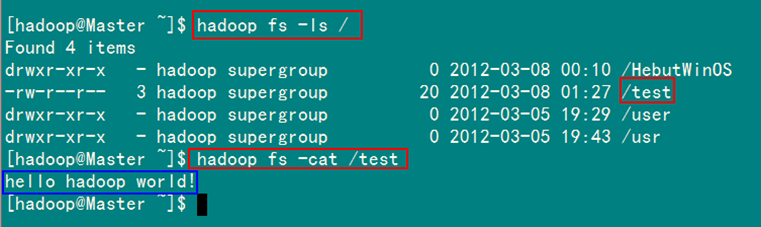
运行结果,如下图所示。
1)项目浏览器

2)SecureCRT结果
6.3 创建HDFS目录
通过”FileSystem.mkdirs(Path f)“可在HDFS上创建文件夹,其中f为文件夹的完整路径。具体实现如下所示。
package com.hebut.dir;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class CreateDir { public static void main(String[] args) throws Exception{ Configuration conf=new Configuration(); FileSystem hdfs=FileSystem.get(conf); Path dfs=new Path("/TestDir"); hdfs.mkdirs(dfs);
} }
运行结果,如下图所示。
1)项目浏览器
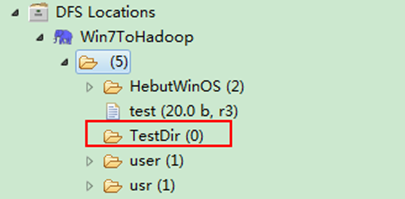
2)SecureCRT结果

6.4 重命名HDFS文件
通过”FileSystem.rename(Path src, Path dst)“可为指定的HDFS文件重命名,其中src和dst均为文件的完整路径,具体实现如下所示。
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Rename{
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path frpaht=new Path("/test"); //旧的文件名
Path topath=new Path("/test1"); //新的文件名
boolean isRename=hdfs.rename(frpaht, topath);
String result=isRename?"成功":"失败";
System.out.println("文件重命名结果为:"+result);
}
}
运行结果,如下图所示。
1)项目浏览器

2)SecureCRT结果

6.5 删除HDFS上的文件
通过”FileSystem.delete(Path f, Boolean recursive)“可删除指定的HDFS文件,其中f为需要删除的完整路径,recuresive用来确定是否进行递归删除。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class DeleteFile { public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); FileSystem hdfs=FileSystem.get(conf);
Path delef=new Path("/test1"); boolean isDeleted=hdfs.delete(delef,false); //递归删除 //boolean isDeleted=hdfs.delete(delef,true); System.out.println("Delete?"+isDeleted);
}
}
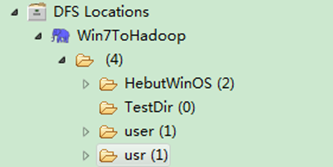
运行结果,如下图所示。
1)控制台结果

2)项目浏览器
6.6 删除HDFS上的目录
同删除文件代码一样,只是缓存删除目录路径即可,如果目录下有文件,要进行递归删除。
6.7 查看某个HDFS文件是否存在
通过”FileSystem.exists(Path f)“可查看指定HDFS文件是否存在,其中f为文件的完整路径。具体事项如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class CheckFile { public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); FileSystem hdfs=FileSystem.get(conf); Path findf=new Path("/test1"); boolean isExists=hdfs.exists(findf); System.out.println("Exist?"+isExists); }
}
运行结果,如下图所示。
1)控制台结果

2)项目浏览器

6.8 查看HDFS文件的最后修改时间
通过”FileSystem.getModificationTime()“可查看指定HDFS文件的修改时间。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class GetLTime {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path fpath =new Path("/user/hadoop/test/file1.txt");
FileStatus fileStatus=hdfs.getFileStatus(fpath);
long modiTime=fileStatus.getModificationTime();
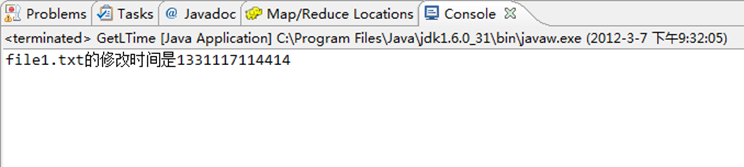
System.out.println("file1.txt的修改时间是"+modiTime);
}
}
运行结果,如下图所示。
1)控制台结果
6.9 读取HDFS某个目录下的所有文件
通过”FileStatus.getPath()“可以查看指定HDFS中某个目录下所有文件。具体实现如下所示。
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class ListAllFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path listf =new Path("/user/hadoop/test");
FileStatus stats[]=hdfs.listStatus(listf);
for(int i = 0; i < stats.length; ++i)
{
System.out.println(stats[i].getPath().toString());
}
hdfs.close();
}
}
运行结果,如下图所示。
1)控制台结果

2)项目浏览器

6.10 查找某个文件在HDFS集群的位置
通过”FileSystem.getFileBlockLocation(FileStatus file, long start, long len)“可查找指定文件在HDFS集群上的位置,其中file为文件的完整路径,start和len来标识查找文件的路径。具体实现如下:
package com.hebut.file;
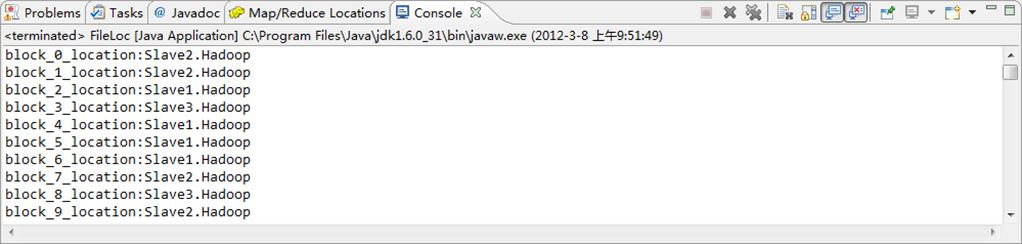
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.BlockLocation; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class FileLoc { public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); FileSystem hdfs=FileSystem.get(conf); Path fpath=new Path("/user/hadoop/cygwin"); FileStatus filestatus = hdfs.getFileStatus(fpath); BlockLocation[] blkLocations = hdfs.getFileBlockLocations(filestatus, 0, filestatus.getLen()); int blockLen = blkLocations.length; for(int i=0;i<blockLen;i++){ String[] hosts = blkLocations[i].getHosts(); System.out.println("block_"+i+"_location:"+hosts[0]); }
} }
运行结果,如下图所示。
1)控制台结果
6.11 获取HDFS集群上所有节点名称信息
通过”DatanodeInfo.getHostName()“可获取HDFS集群上的所有节点名称。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.hdfs.DistributedFileSystem;
import org.apache.hadoop.hdfs.protocol.DatanodeInfo;
public class GetList {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
DistributedFileSystem hdfs = (DistributedFileSystem)fs;
DatanodeInfo[] dataNodeStats = hdfs.getDataNodeStats();
for(int i=0;i<dataNodeStats.length;i++){
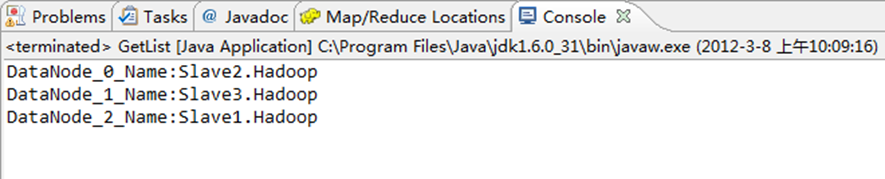
System.out.println("DataNode_"+i+"_Name:"+dataNodeStats[i].getHostName());
}
}
}
运行结果,如下图所示。
1)控制台结果
7、HDFS的读写数据流
7.1 文件的读取剖析

文件读取的过程如下:
1)解释一
- 客户端(client)用FileSystem的open()函数打开文件;
- DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息;
- 对于每一个数据块,元数据节点返回保存保存数据块的数据节点的地址;
- DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据;
- 客户端调用stream的read()函数开始读取数据;
- DFSInputStream连接保存此文件第一个数据块的最近的数据节点;
- Data从数据节点读到客户端(client);
- 当此数据块读取完毕后,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点;
- 当客户端读取完毕数据的时候,调用FSDataInputStream的close函数;
- 在读取数据的过程中,如果客户端在与数据点通信出现错误,则尝试连接包含此数据块的下一个数据节点;
- 失败的数据节点将被记录,以后不再连接;
2)解释二
- 使用HDFS提供的客户端开发库,向远程的NameNode发起RPC请求;
- NameNode会视情况返回文件的部分或全部的block列表,对于每个block,Namenode都会返回有该block拷贝的datanode地址;
- 客户端开发库会选取离客户端最接近的datanode来读取block;
- 读取完当前block数据后,关闭与当前datanode连接,并为读取下一个block寻找最佳的datanode;
- 当读完列表的block后,且文件读取还没有结束,客户端开发库会继续向NameNode获取下一批的block列表;
- 读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读;
7.2 文件的写入剖析

写入文件的过程比读取较为复杂:
1)解释一
- 客户端调用create()来创建文件
- DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。
- 元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
- DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
- 客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。
- Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。
- Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
- DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
- 如果数据节点在写入的过程中失败:
- 关闭pipeline,将ack queue中的数据块放入data queue的开始。
- 当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。
- 失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。
- 元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
- 当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
2)解释二
- 使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
- Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
- 当客户端开始写入文件的时候,开发库会将文件切分成多个packets,并在内部以"data queue"的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表,列表的大小根据在Namenode中对replication的设置而定。
- 开始以pipeline(管道)的形式将packet写入所有的replicas中。开发库把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
- 最后一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。
- 如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replicas设定的数量。
这部分需要实践,先记录下来,等周末实践下。
感谢作者,原文链接:http://www.cnblogs.com/xia520pi/archive/2012/05/28/2520813.html
HDFS初探之旅(二)的更多相关文章
- HDFS初探之旅(一)
1.HDFS简介 ...
- 初探JavaScript(二)——JS如何动态操控HTML
除去五一三天,我已经和<JavaScript Dom编程艺术>磨合了六天,第一印象很好.慢慢的,我发现这是一块排骨,除了肉还有骨头.遇到不解的地方就会多看几遍,实在不懂的先跳过,毕竟,初次 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- 非常不错 Hadoop 的HDFS (Hadoop集群(第8期)_HDFS初探之旅)
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- Hadoop集群(第8期)_HDFS初探之旅
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- 滴滴Booster移动APP质量优化框架 学习之旅 二
推荐阅读: 滴滴Booster移动App质量优化框架-学习之旅 一 Android 模块Api化演练 不一样视角的Glide剖析(一) 续写滴滴Booster移动APP质量优化框架学习之旅,上篇文章分 ...
- Hadoop集群_HDFS初探之旅
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- MongoDB初探系列之二:认识MongoDB提供的一些经常使用工具
在初探一中,我们已经能够顺利的将MongoDB在我们自己的机器上跑起来了. 可是在其bin文件夹以下另一些我们不熟知的工具.接下来,将介绍一下各个小工具的用途以及初探一中MongoDB在data文件夹 ...
- artDialog学习之旅(二)之扩展方法详解
名称 描述 核心方法 art.dialog.top 获取artDialog可用最高层window对象.这与直接使用window.top不同,它能排除artDialog对象不存在已经或者顶层页面为框架集 ...
随机推荐
- 虚拟机克隆后修改mac地址和ip地址
(1)虚拟机克隆在新的虚拟机下会有文件产生变化. /etc/udev/rules.d/70-persistent-net.rules 文件中会多一个eth1 网卡的文件 ,eth0 的那行文件是原虚 ...
- SpringCloud微服务实战——搭建企业级开发框架(十四):集成Sentinel高可用流量管理框架【限流】
Sentinel 是面向分布式服务架构的高可用流量防护组件,主要以流量为切入点,从限流.流量整形.熔断降级.系统负载保护.热点防护等多个维度来帮助开发者保障微服务的稳定性. Sentinel 具有 ...
- Cobar SQL审计的设计与实现
背景介绍 Cobar简介 Cobar 是阿里开源的一款数据库中间件产品. 在业务高速增长的情况下,数据库往往成为整个业务系统的瓶颈,数据库中间件的出现就是为了解决数据库瓶颈而产生的一种中间层产品. 在 ...
- git rebase 合并提交
git rebase 合并提交 合并最近多次提交记录 语法 git rebase -i HEAD~n 1.进入合并模式 合并最近三次提交 git rebase -i HEAD~3 然后你会看到一个像下 ...
- Centos8上安装Mysql8.X
一.下载Mysql 下载地址:https://dev.mysql.com/downloads/mysql/ 二.将压缩包通过ftp软件服务器的目标位置:并解压 1.我的是放在:/root/softwa ...
- 在Jenkins中执行 PowerShell 命令实现高效的CD/CI部署
相比于cmd,powershell支持插件.语法扩展和自定义扩展名,是智能化部署中闪闪的新星,越来越多的开发者偏爱使用Powershell. 如何让Jenkins支持Powershell呢?本文即展开 ...
- 96-00年CPU功耗感知调度研究
最近读了一些1996-2000年的通过调度来降低cpu能耗的文章,主要文章有[1] [2] [3] [4] [5], 简单总结一些该时期单核CPU功耗感知的调度策略. 该时期还出现了很多关于低功耗电路 ...
- [hdu7082]Pty loves lcm
先将问题差分,即仅考虑上限$R$(和$L-1$) 注意到$f(x,y)$增长是较快的,对其分类讨论: 1.若$y\ge x+2$,此时满足$f(x,y)\le 10^{18}$的$(x,y)$只有约$ ...
- [cf1491I]Ruler Of The Zoo
为了统一描述,下面给出题意-- 有$n$只动物,编号为$i$的动物有属性$a_{i,j}$($0\le i<n,0\le j\le 2$) 初始$n$只动物从左到右编号依次为$0,1,...,n ...
- Spark SQL知识点与实战
Spark SQL概述 1.什么是Spark SQL Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块. 与基本的Spark RDD API不同,Sp ...