Flink去重统计-基于自定义布隆过滤器
一、背景说明
在Flink中对流数据进行去重计算是常有操作,如流量域对独立访客之类的统计,去重思路一般有三个:
- 基于Hashset来实现去重
数据存在内存,容量小,服务重启会丢失。 - 使用状态编程ValueState/MapState实现去重
常用方式,可以使用内存/文件系统/RocksDB作为状态后端存储。 - 结合Redis使用布隆过滤器实现去重
适用对上亿数据量进行去重实现,占用资源少效率高,有小概率误判。
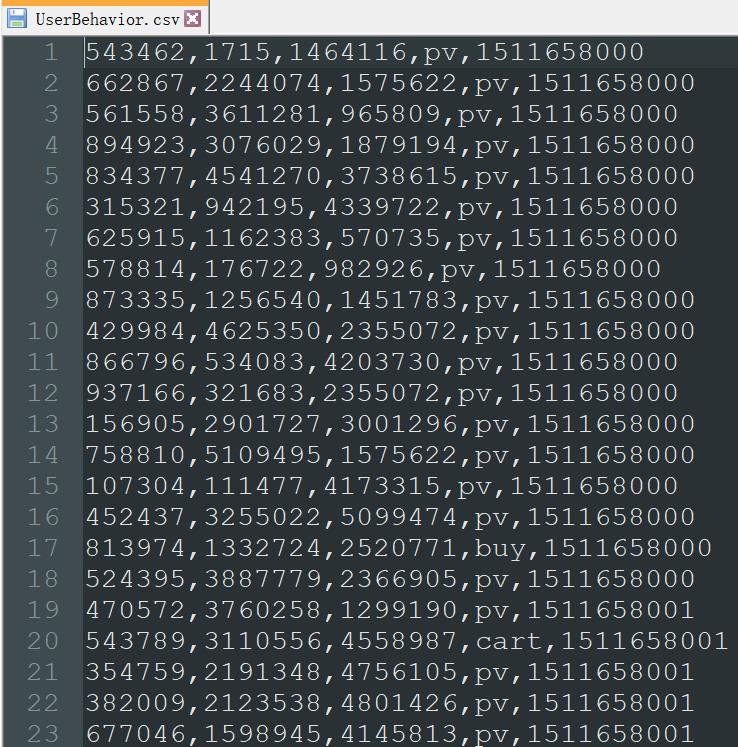
这里以自定义布隆过滤器的方式,实现Flink窗口计算中独立访客的统计,数据集样例如下:
二、布隆过滤器部分说明
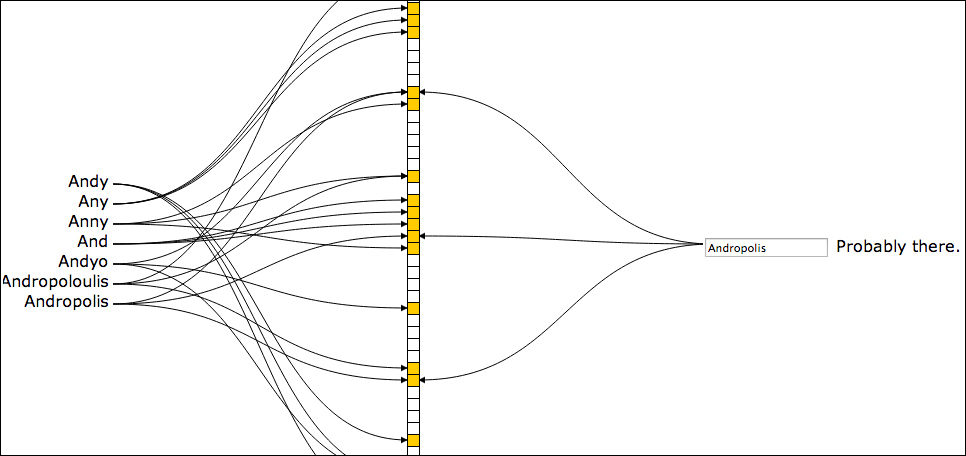
布隆过滤器简单点说就是哈希算法+bitmap,如上图,对字符串结合多种哈希算法,基于bitmap作为存储,由于只用0/1存储,所以可以大量节省存储空间,也就特别适合在上百亿数据里面做去重这种动作。在后续要进行字符串查找时,对要查找的字符串同样计算这多个哈希算法,根据在bitmap上的位置,可以确认该字符串一定不在或者极大概率在(由于哈希冲突问题会有极小概率误判)。
引申一下,如上所述,能对哈希冲突进行更好的优化,便能更好解决误判问题,当然也不能无限的增加多种哈希算法的策略,会相应带来计算效率的下降。
在本次开发中,使用自定义的布隆过滤器,其中对哈希算法部分做了几点优化:
- 结合Redis使用,Redis原生支持bitmap
- 对bitmap容量扩容,一般为数据的3-10倍,这里使用2^30,使用2的整数幂,能让后续查找输出使用位与运算,实现比取模查找更高的效率。
myBloomFilter = new MyBloomFilter(1 << 30);
- 优化哈希算法,这里对要查找的id转为char类型,并行单个剔除后基于Unicode编码乘以质数31再相加,来避免不同字符串计算出同样哈希值的问题。
for (char c : value.toCharArray()){
result += result * 31 + c;
}
另外,谷歌提供的工具Guava也包含了布隆过滤器,加入相关依赖即可使用,主要参数如下源码,输入要建立的过滤器容器大小及误判概率即可。
public static <T> BloomFilter<T> create(Funnel<? super T> funnel, int expectedInsertions, double fpp) {
return create(funnel, (long)expectedInsertions, fpp);
}
三、代码部分
package com.test.UVbloomfilter;
import bean.UserBehavior;
import bean.UserVisitorCount;
import java.sql.Timestamp;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.Trigger;
import org.apache.flink.streaming.api.windowing.triggers.TriggerResult;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import redis.clients.jedis.Jedis;
public class UserVisitorTest {
public static void main(String[] args) throws Exception {
//建立环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.setParallelism(1);
//指定时间语义
WatermarkStrategy<UserBehavior> wms = WatermarkStrategy
.<UserBehavior>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<UserBehavior>() {
@Override
public long extractTimestamp(UserBehavior element, long recordTimestamp) {
return element.getTimestamp() * 1000L;
}
});
//读取数据、映射、过滤
SingleOutputStreamOperator<UserBehavior> userBehaviorDS = env
.readTextFile("input/UserBehavior.csv")
.map(new MapFunction<String, UserBehavior>() {
@Override
public UserBehavior map(String value) throws Exception {
String[] split = value.split(",");
return new UserBehavior(Long.parseLong(split[0])
, Long.parseLong(split[1])
, Integer.parseInt(split[2])
, split[3]
, Long.parseLong(split[4]));
}
})
//.filter(data -> "pv".equals(data.getBehavior())) //lambda表达式写法
.filter(new FilterFunction<UserBehavior>() {
@Override
public boolean filter(UserBehavior value) throws Exception {
if (value.getBehavior().equals("pv")) {
return true;
}return false; }})
.assignTimestampsAndWatermarks(wms);
//去重按全局去重,故使用行为分组,仅为后续开窗使用、开窗
WindowedStream<UserBehavior, String, TimeWindow> windowDS = userBehaviorDS.keyBy(UserBehavior::getBehavior)
.window(TumblingEventTimeWindows.of(Time.hours(1)));
SingleOutputStreamOperator<UserVisitorCount> processDS = windowDS
.trigger(new MyTrigger()).process(new UserVisitorWindowFunc());
processDS.print();
env.execute();
}
//自定义触发器:来一条计算一条(访问Redis一次)
private static class MyTrigger extends Trigger<UserBehavior, TimeWindow> {
@Override
public TriggerResult onElement(UserBehavior element, long timestamp, TimeWindow window, TriggerContext ctx) throws Exception {
return TriggerResult.FIRE_AND_PURGE; //触发计算和清除窗口元素。
}
@Override
public TriggerResult onProcessingTime(long time, TimeWindow window, TriggerContext ctx) throws Exception {
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onEventTime(long time, TimeWindow window, TriggerContext ctx) throws Exception {
return TriggerResult.CONTINUE;
}
@Override
public void clear(TimeWindow window, TriggerContext ctx) throws Exception {
}
}
private static class UserVisitorWindowFunc extends ProcessWindowFunction<UserBehavior,UserVisitorCount,String,TimeWindow> {
//声明Redis连接
private Jedis jedis;
//声明布隆过滤器
private MyBloomFilter myBloomFilter;
//声明每个窗口总人数的key
private String hourUVCountKey;
@Override
public void open(Configuration parameters) throws Exception {
jedis = new Jedis("hadoop102",6379);
hourUVCountKey = "HourUV";
myBloomFilter = new MyBloomFilter(1 << 30); //2^30
}
@Override
public void process(String s, Context context, java.lang.Iterable<UserBehavior> elements, Collector<UserVisitorCount> out) throws Exception {
//1.取出数据
UserBehavior userBehavior = elements.iterator().next();
//2.提取窗口信息
String windowEnd = new Timestamp(context.window().getEnd()).toString();
//3.定义当前窗口的BitMap Key
String bitMapKey = "BitMap_" + windowEnd;
//4.查询当前的UID是否已经存在于当前的bitMap中
long offset = myBloomFilter.getOffset(userBehavior.getUserId().toString());
Boolean exists = jedis.getbit(bitMapKey, offset);
//5.根据数据是否存在做下一步操作
if (!exists){
//将对应offset位置改为1
jedis.setbit(bitMapKey,offset,true);
//累加当前窗口的综合
jedis.hincrBy(hourUVCountKey,windowEnd,1);
}
//输出数据
String hget = jedis.hget(hourUVCountKey, windowEnd);
out.collect(new UserVisitorCount("UV",windowEnd,Integer.parseInt(hget)));
}
}
private static class MyBloomFilter {
//减少哈希冲突优化1:增加过滤器容量为数据3-10倍
//定义布隆过滤器容量,最好传入2的整次幂数据
private long cap;
public MyBloomFilter(long cap) {
this.cap = cap;
}
//传入一个字符串,获取在BitMap中的位置
public long getOffset(String value){
long result = 0L;
//减少哈希冲突优化2:优化哈希算法
//对字符串每个字符的Unicode编码乘以一个质数31再相加
for (char c : value.toCharArray()){
result += result * 31 + c;
}
//取模,使用位与运算代替取模效率更高
return result & (cap - 1);
}}}
输出结果在Redis查看如下:

学习交流,有任何问题还请随时评论指出交流。
Flink去重统计-基于自定义布隆过滤器的更多相关文章
- 基于Redis扩展模块的布隆过滤器使用
什么是布隆过滤器?它实际上是一个很长的二进制向量和一系列随机映射函数.把一个目标元素通过多个hash函数的计算,将多个随机计算出的结果映射到不同的二进制向量的位中,以此来间接标记一个元素是否存在于一个 ...
- 布隆过滤器(Bloom Filter)详解——基于多hash的概率查找思想
转自:http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- 基于Java实现简化版本的布隆过滤器
一.布隆过滤器: 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率 ...
- 【布隆过滤器】基于Hutool库实现的布隆过滤器Demo
布隆过滤器出现的背景: 如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定.链表.树.散列表(又叫哈希表,Hash table)等等数据结构都是这种思路,存储 ...
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 三十七 Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详解 基本概念 如 ...
- 将bloomfilter(布隆过滤器)集成到scrapy-redis中
Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详解 基本概念 如 ...
- Redis解读(4):Redis中HyperLongLog、布隆过滤器、限流、Geo、及Scan等进阶应用
Redis中的HyperLogLog 一般我们评估一个网站的访问量,有几个主要的参数: pv,Page View,网页的浏览量 uv,User View,访问的用户 一般来说,pv 或者 uv 的统计 ...
- 布隆过滤器(BloomFilter)持久化
摘要 Bloomfilter运行在一台机器的内存上,不方便持久化(机器down掉就什么都没啦),也不方便分布式程序的统一去重.我们可以将数据进行持久化,这样就克服了down机的问题,常见的持久化方法包 ...
随机推荐
- Ubuntu18.04美化(Mac OS主题) 美化小白专用
本文主要针对第一次接触Ubuntu美化的童鞋们,有些啰嗦的地方大神勿喷 先上效果图 首先安装神器 gnome-tweak-tool 开启一个终端,输入 sudo apt install gnome-t ...
- Linux命令的应用
目录 Linux命令 Linux文件管理命令 用户管理 权限管理 vi文本编辑器 find查找命令 磁盘管理命令 压缩及解压 Linux 进程 Linux运行tomcat Linux安装mysql 卸 ...
- [BFS]最小转弯问题
最小转弯问题 Description 给出一张地图,这张地图被分为 n×m(n,m<=100)个方块,任何一个方块不是平地就是高山.平地可以通过,高山则不能.现在你处在地图的(x1,y1)这块平 ...
- 基于scrapy框架的爬虫基本步骤
本文以爬取网站 代码的边城 为例 1.安装scrapy框架 详细教程可以查看本站文章 点击跳转 2.新建scrapy项目 生成一个爬虫文件.在指定的目录打开cmd.exe文件,输入代码 scrapy ...
- maven setting.xml 阿里云镜像 没有一句废话
<?xml version="1.0" encoding="UTF-8"?> <!-- Licensed to the Apache Soft ...
- 构建一个Flowable命令行应用
官网链接 [(https://flowable.com/open-source/docs/bpmn/ch02-GettingStarted/#building-a-command-line-appli ...
- 一个Bug,让我发现了 Java 界的.AJ(锥)!
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 话我放这,踩过的坑越多头发越少! 说来也是奇怪,只要是学编程的,从初次接触的 Jav ...
- 《C++编程思想》部分章节学习笔记整理
简介 此笔记为<C++编程思想>中部分章节的学习笔记,主要是第15章--多态性和虚函数 的学习笔记,此外还有少量其他章节的内容. 目录 文档:<C++编程思想>
- python工业互联网应用实战13—基于selenium的功能测试
本章节我们再来说说测试,单元测试和功能测试.单元测试我们在数据验证章节简单提过了,本章我们进一步如何用单元测试来测试view的功能代码:同时,也涉及一下基于selenium的功能测试做法.笔者过去的项 ...
- Smith Numbers(分解质因数)
Smith Numbers Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 14173 Accepted: 4838 De ...