第2篇-JVM虚拟机这样来调用Java主类的main()方法
在前一篇 第1篇-关于JVM运行时,开篇说的简单些 中介绍了call_static()、call_virtual()等函数的作用,这些函数会调用JavaCalls::call()函数。我们看Java类中main()方法的调用,调用栈如下:
JavaCalls::call_helper() at javaCalls.cpp
os::os_exception_wrapper() at os_linux.cpp
JavaCalls::call() at javaCalls.cpp
jni_invoke_static() at jni.cpp
jni_CallStaticVoidMethod() at jni.cpp
JavaMain() at java.c
start_thread() at pthread_create.c
clone() at clone.S
这是Linux上的调用栈,通过JavaCalls::call_helper()函数来执行main()方法。栈的起始函数为clone(),这个函数会为每个进程(Linux进程对应着Java线程)创建单独的栈空间,这个栈空间如下图所示。
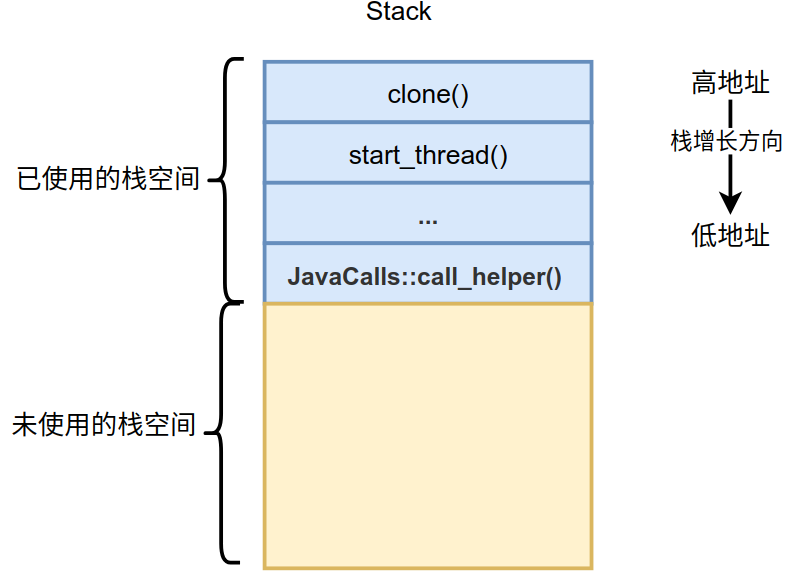
在Linux操作系统上,栈的地址向低地址延伸,所以未使用的栈空间在已使用的栈空间之下。图中的每个蓝色小格表示对应方法的栈帧,而栈就是由一个一个的栈帧组成。native方法的栈帧、Java解释栈帧和Java编译栈帧都会在黄色区域中分配,所以说他们寄生在宿主栈中,这些不同的栈帧都紧密的挨在一起,所以并不会产生什么空间碎片这类的问题,而且这样的布局非常有利于进行栈的遍历。上面给出的调用栈就是通过遍历一个一个栈帧得到的,遍历过程也是栈展开的过程。后续对于异常的处理、运行jstack打印线程堆栈、GC查找根引用等都会对栈进行展开操作,所以栈展开是后面必须要介绍的。
下面我们继续看JavaCalls::call_helper()函数,这个函数中有个非常重要的调用,如下:
// do call
{
JavaCallWrapper link(method, receiver, result, CHECK);
{
HandleMark hm(thread); // HandleMark used by HandleMarkCleaner
StubRoutines::call_stub()(
(address)&link,
result_val_address,
result_type,
method(),
entry_point,
args->parameters(),
args->size_of_parameters(),
CHECK
); result = link.result(); // circumvent MS C++ 5.0 compiler bug (result is clobbered across call)
// Preserve oop return value across possible gc points
if (oop_result_flag) {
thread->set_vm_result((oop) result->get_jobject());
}
}
} // Exit JavaCallWrapper (can block - potential return oop must be preserved)
调用StubRoutines::call_stub()函数返回一个函数指针,然后通过函数指针来调用函数指针指向的函数。通过函数指针调用和通过函数名调用的方式一样,这里我们需要清楚的是,调用的目标函数仍然是C/C++函数,所以由C/C++函数调用另外一个C/C++函数时,要遵守调用约定。这个调用约定会规定怎么给被调用函数(Callee)传递参数,以及被调用函数的返回值将存储在什么地方。
下面我们就来简单说说Linux X86架构下的C/C++函数调用约定,在这个约定下,以下寄存器用于传递参数:
- 第1个参数:rdi c_rarg0
- 第2个参数:rsi c_rarg1
- 第3个参数:rdx c_rarg2
- 第4个参数:rcx c_rarg3
- 第5个参数:r8 c_rarg4
- 第6个参数:r9 c_rarg5
在函数调用时,6个及小于6个用如下寄存器来传递,在HotSpot中通过更易理解的别名c_rarg*来使用对应的寄存器。如果参数超过六个,那么程序将会用调用栈来传递那些额外的参数。
数一下我们通过函数指针调用时传递了几个参数?8个,那么后面的2个就需要通过调用函数(Caller)的栈来传递,这两个参数就是args->size_of_parameters()和CHECK(这是个宏,扩展后就是传递线程对象)。
所以我们的调用栈在调用函数指针指向的函数时,变为了如下状态:
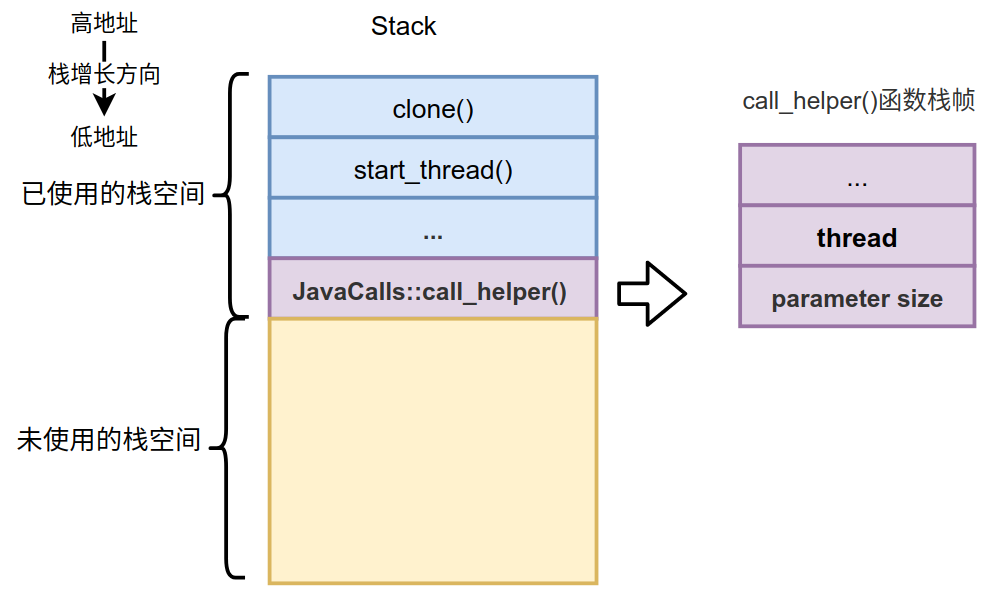
右边是具体的call_helper()栈帧中的内容,我们把thread和parameter size压入了调用栈中,其实在调目标函数的过程还会开辟新的栈帧并在parameter size后压入返回地址和调用栈的栈底,下一篇我们再详细介绍。先来介绍下JavaCalls::call_helper()函数的实现,我们分3部分依次介绍。
1、检查目标方法是否"首次执行前就必须被编译”,是的话调用JIT编译器去编译目标方法;
代码实现如下:
void JavaCalls::call_helper(JavaValue* result, methodHandle* m, JavaCallArguments* args, TRAPS) {
methodHandle method = *m;
JavaThread* thread = (JavaThread*)THREAD;
...
assert(!thread->is_Compiler_thread(), "cannot compile from the compiler");
if (CompilationPolicy::must_be_compiled(method)) {
CompileBroker::compile_method(method, InvocationEntryBci,
CompilationPolicy::policy()->initial_compile_level(),
methodHandle(), 0, "must_be_compiled", CHECK);
}
...
}
对于main()方法来说,如果配置了-Xint选项,则是以解释模式执行的,所以并不会走上面的compile_method()函数的逻辑。后续我们要研究编译执行时,可以强制要求进行编译执行,然后查看执行过程。
2、获取目标方法的解释模式入口from_interpreted_entry,也就是entry_point的值。获取的entry_point就是为Java方法调用准备栈桢,并把代码调用指针指向method的第一个字节码的内存地址。entry_point相当于是method的封装,不同的method类型有不同的entry_point。
接着看call_helper()函数的代码实现,如下:
address entry_point = method->from_interpreted_entry();
调用method的from_interpreted_entry()函数获取Method实例中_from_interpreted_entry属性的值,这个值到底在哪里设置的呢?我们后面会详细介绍。
3、调用call_stub()函数,需要传递8个参数。这个代码在前面给出过,这里不再给出。下面我们详细介绍一下这几个参数,如下:
(1)link 此变量的类型为JavaCallWrapper,这个变量对于栈展开过程非常重要,后面会详细介绍;
(2)result_val_address 函数返回值地址;
(3)result_type 函数返回类型;
(4)method() 当前要执行的方法。通过此参数可以获取到Java方法所有的元数据信息,包括最重要的字节码信息,这样就可以根据字节码信息解释执行这个方法了;
(5)entry_point HotSpot每次在调用Java函数时,必然会调用CallStub函数指针,这个函数指针的值取自_call_stub_entry,HotSpot通过_call_stub_entry指向被调用函数地址。在调用函数之前,必须要先经过entry_point,HotSpot实际是通过entry_point从method()对象上拿到Java方法对应的第1个字节码命令,这也是整个函数的调用入口;
(6)args->parameters() 描述Java函数的入参信息;
(7)args->size_of_parameters() 描述Java函数的入参的大小;
(8)CHECK 当前线程对象。
这里最重要的就是entry_point了,这也是下一篇要介绍的内容。
搭建过程中如果有问题可直接评论留言或加作者微信mazhimazh。
关注公众号,有HotSpot源码剖析系列文章!

第2篇-JVM虚拟机这样来调用Java主类的main()方法的更多相关文章
- 第4篇-JVM终于开始调用Java主类的main()方法啦
在前一篇 第3篇-CallStub新栈帧的创建 中我们介绍了generate_call_stub()函数的部分实现,完成了向CallStub栈帧中压入参数的操作,此时的状态如下图所示. 继续看gene ...
- 第29篇-调用Java主类的main()方法
在第1篇中大概介绍过Java中主类方法main()的调用过程,这一篇介绍的详细一点,大概的调用过程如下图所示. 其中浅红色的函数由主线程执行,而另外的浅绿色部分由另外一个线程执行,这个线程最终也会负责 ...
- java 主类的main方法调用其他方法
方法1:A a=new test().new A(); 内部类对象通过外部类的实例对象调用其内部类构造方法产生,如下: public class test{ class A{ void fA(){ S ...
- 22.编写一个类A,该类创建的对象可以调用方法showA输出小写的英文字母表。然后再编写一个A类的子类B,子类B创建的对象不仅可以调用方法showA输出小写的英文字母表,而且可以调用子类新增的方法showB输出大写的英文字母表。最后编写主类C,在主类的main方法 中测试类A与类B。
22.编写一个类A,该类创建的对象可以调用方法showA输出小写的英文字母表.然后再编写一个A类的子类B,子类B创建的对象不仅可以调用方法showA输出小写的英文字母表,而且可以调用子类新增的方法sh ...
- 编写Java应用程序。首先,定义一个时钟类——Clock,它包括三个int型 成员变量分别表示时、分、秒,一个构造方法用于对三个成员变量(时、分、秒) 进行初始化,还有一个成员方法show()用于显示时钟对象的时间。其次,再定义 一个主类——TestClass,在主类的main方法中创建多个时钟类的对象,使用这 些对象调用方法show()来显示时钟的时间。
package com.hanqi.test; public class Clock { int hh; int mm; int ss; String time; Clock(int h,int m, ...
- 按要求编写Java应用程序: (1)编写西游记人物类(XiYouJiRenWu) 其中属性有:身高(height),名字(name),武器(weapon) 方法有:显示名字(printName),显示武器(printWeapon) (2)在主类的main方法中创建二个对象:zhuBaJie,sunWuKong。并分别为他 们的两个属性(name,weapon)赋值,最后分别调用printName,
package com.hanqi.test; public class xiyoujirenwu { private double height;// 身高 private String name; ...
- 编写Java应用程序。首先,定义一个Print类,它有一个方法void output(int x),如果x的值是1,在控制台打印出大写的英文字母表;如果x的值是2,在 控制台打印出小写的英文字母表。其次,再定义一个主类——TestClass,在主类 的main方法中创建Print类的对象,使用这个对象调用方法output ()来打印出大 小写英文字母表。
package zuoye; public class print1 { String a="abcdefghigklmnopqrstuvwxyz"; String B=" ...
- 定义一个时钟类——Clock,它包括三个int型 成员变量分别表示时、分、秒,一个构造方法用于对三个成员变量(时、分、秒) 进行初始化,还有一个成员方法show()用于显示时钟对象的时间。其次,再定义 一个主类——TestClass,在主类的main方法中创建多个时钟类的对象,使用这 些对象调用方法show()来显示时钟的时间
package java1; public class Clock { int hhh; int mmm; int sss; Clock(int h,int m,int s) { hhh=h; mmm ...
- 编写一个类A,该类创建的对象可以调用方法f输出小写的英文字母表。然 后再编写一个A类的子类B,要求子类B必须继承类A的方法f(不允许重写), 子类B创建的对象不仅可以调用方法f输出小写的英文字母表,而且可以调用子 类新增的方法g输出大写的英文字母表。最后编写主类C,在主类的main方法 中测试类A与类B。
package zimu; public class A { public void f() { for (int i = 97; i <123; i++) { System.out.print ...
随机推荐
- CSS3转换(transform)基本用法介绍
一个炫酷的网页离不开css的transform.transition.animation三个属性,之前一直没有涉及到这块内容,刚好最近要做一个相关东西,趁此机会好好学一学这三个属性. 一.功能 实现元 ...
- 基于 Electron 实现 uTools 的超级面板
前言 为了进一步提高开发工作效率,最近我们基于 electron 开发了一款媲美 uTools 的开源工具箱 rubick.该工具箱不仅仅开源,最重要的是可以使用 uTools 生态内所有开源插件!这 ...
- 6、inotify实时备份
备份用户nfs共享文件系统,存储单点解决方案inotify+rsync(增量,无差异备份),inotify是单线程, inotify是一种强大的,细粒度的,异步的文件系统事件监控机制,通过加入了ino ...
- 9.4、安装zabbix(1)
1.什么是zabbix: zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案: zabbix能监视各种网络参数,保证服务器系统的安全运营:并提供灵活的通知机制以 ...
- activiti版本下载
activiti工作流历史各个版本下载地址修改版本号后在浏览器地址栏回车即可 例如: https://github.com/Activiti/Activiti/releases/download/ac ...
- POJ 1279 Art Gallery 半平面交 多边形的核
题意:求多边形的核的面积 套模板即可 #include <iostream> #include <cstdio> #include <cmath> #define ...
- Docker:docker搭建redis6.0.8集群
下载redis镜像 #拉取镜像 docker pull redis:6.0.8 查看版本 #查看版本 docker inspect redis 生成redis.conf配置文件 #在 /home/re ...
- Redis:redis.conf配置文件 - 及配置详解
配置文件详解(文章最后有完整的redis.conf文件) ################################### NETWORK ######################### ...
- 1.3.2、通过Cookie匹配
server: port: 8080 spring: application: name: gateway cloud: gateway: routes: - id: guo-system4 uri: ...
- 【并查集模板】并查集模板 luogu-3367
题目描述 简单的并查集模板 输入描述 第一行包含两个整数N.M,表示共有N个元素和M个操作. 接下来M行,每行包含三个整数Zi.Xi.Yi 当Zi=1时,将Xi与Yi所在的集合合并 当Zi=2时,输出 ...