【Python机器学习实战】决策树与集成学习(七)——集成学习(5)XGBoost实例及调参
上一节对XGBoost算法的原理和过程进行了描述,XGBoost在算法优化方面主要在原损失函数中加入了正则项,同时将损失函数的二阶泰勒展开近似展开代替残差(事实上在GBDT中叶子结点的最优值求解也是使用的二阶泰勒展开(详细上面Tips有讲解),但XGBoost在求解决策树和最优值都用到了),同时在求解过程中将两步优化(求解最优决策树和叶子节点最优输出值)合并成为一步。本节主要对XGBoot进行实现并调参。
XGBoost框架及参数
XGBoost原生框架与sklearn风格框架
XGBoost有两个框架,一个是原生的XGBoost框架,另一个是sklearn所带的XGBoost框架。二者实现基本一致,但在API的使用方法和参数名称不同,在数据集的初始化方面也有不同。
XGBoost原生库的使用过程如下:

其中主要是在DMatrix读取数据和train训练数据的类,其中DMatrix在原生XGBoost库中的需要先把数据集按输入特征部分、输出特征部分分开,然后放到DMatrix中,即:
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
dtrain = xgb.DMatrix(X_train, y_train)
dtest = xgb.DMatrix(X_test, y_test)
sklearn中参数都是写在train中(不过也有使用原生XGBoost参数风格的sklearn用法),而原生库中必须将参数写入参数param的字典中,再输入到train中,之所以这么做是因为XGBoost所涉及的参数实在过多,都放在一起太长也容易出错,比如(参数含义后面再说):
param = {'max_depth':5, 'eta':0.5, 'verbosity':1, 'objective':'binary:logistic'}
在模型训练上,一种是使用原生XGBoost接口:
import xgboost as xgb
model = xgb.train(param, dtrain,num_boost_round=10,evals=(),obj=None,feval=None,maximize=False,early_stopping_rounds=None)
第二种是使用sklearn风格的接口,sklearn风格的xgb有两种,一种是分类用的XGBClassifier,还有一个回归用的XGBRegressor:
model = xgb.XGBClassifier('max_depth':5, 'eta':0.5, 'verbosity':1, 'objective':'binary:logistic')
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="error",)
同时也可以sklearn风格下的原生参数param,只需传入**param即可:
model = xgb.XGBClassifier(**param)
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="error")
上面就是XGBoost的大致使用过程,下面主要对模型中的参数进行说明。
XGBoost框架下的参数
由于XGBoost原生库与sklearn库的参数在名字上有一定的差异,既然有sklearn风格的接口,为了与其他算法保持一致,这里主要对sklearn风格的参数进行说明,并尽量与原生库与GBDT中进行对应。
首先参数主要包括三个方面:XGBoost框架参数、弱学习器参数以及其他学习参数。
XGBoost框架参数:
这方面参数主要包括3个:booster、n_estimators、objective。
- 模型选择参数booster:该参数决定了XGBoost学习时使用的弱学习器类型,有默认的gbtree,也就是CART决策树,还有线性学习器gblinear或者DART,一般使用gbtree就可以,不需要调整。该参数在sklearn中命名一样;
- n_estimators:这是一个非常重要的参数,关系到模型的复杂度,表示了弱学习器的个数,默认为100,与GBDT中的类似,当参数过小时,容易欠拟合,过大时会过拟合,在原生库中对应的num_boost_bounds参数,默认为10;
- objective:表示所解决的问题是分类问题还是回归问题,或者其它问题,以及对应的损失函数,具体取值有很多情况,这里主要说明在分类或者回归所使用的参数:silent:静默参数,指训练中每次是否打印训练结果,在sklearn中默认为True,原生库中默认为False
- 在回归问题中,这个参数一般使用reg:squarederror,即MSE均方误差;
- 在二分类问题中,这个参数一般使用binary:logistic;
- 在多分类中,这个参数一般使用multi:softmax。
弱学习器参数:
由于默认学习器为gbtree,其效果较好,这里只介绍gbtree相关参数,其包含参数较多,大多与GBDT中的一样,下面一一说明:
- 学习率learning_rate:通过较少每一步的权重,提高模型的泛化能力,该参数与GBDT中的学习率相同,默认为0.1,在原生库中该参数对应着eta,默认为0.3(GBDT中默认为1),一般取值0.01~0.2;
- 最小叶子结点权重和min_child_weight:如果某树节点的权重小于该阈值,则不再进行分裂,即这个树节点就是叶子结点,树节点的权重和也就是该节点所有样本二阶导数和:
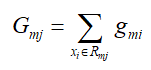
该参数与GBDT中的min_samples_split类似,但又不完全一样,XGBoost中是最小样本权重和,GBDT中限定的是样本的数量,在原生库中该参数一致;
- 树的最大深度max_depth:限定树的深度,与DGBT中一样(默认为3),这里默认为6,原生库中该参数一致;
- 损失所减小的阈值gamma:XGBoost树分裂所带来的的损失减小的阈值,当小于该值时不进行分裂,默认为0,在原生库中一致,即XGBoost原理中γ,该值需要进行网格搜索调参:

- 子采样参数subsample:和GBDT中的参数一样,控制样本数量,默认为1,sklearn中一致;
- 特征采样参数colsample_bytree/colsample_bylevel:前者和GBDT中的max_features相似,用来控制采样特征数量,这里一般只能输入浮点类型,表示采样特征比例,后者是每一层数再进行特征采样,在原生库中参数一致,默认都是1,即不做采样;
- 正则化参数reg_alpha/reg_lambda:原理篇中的正则化项的参数,alpha默认为0,lambda默认1,在原生库中为alpha、lambda;
- scale_pos_weight:用于类别不平衡的时候,负例和正例的比例,类似于GBDT中的class_weight参数,默认为1,原生库中一致;
上面除了scale_pos_weight,其他基本都是需要进行调参的参数,一般先调learning_rate,n_eatimators,max_depth,min_child_weight和gamma,如果还是过拟合,继续调节后面的参数。
其他参数
其他参数主要用于控制XGBoost性能以及结果的相关参数,主要有以下这些:
- n_jobs:控制算法的线程数,默认为最大线程;
- early_stop_rounds:这是一种自动查找n_estimators的方法。通常是设置一个较大的n_estimators,然后通过该参数来找到最佳停止迭代的时间,由于随机几率有时候会导致单次验证分数没有提高,您需要指定一个数字,设置验证分数连续恶化多少轮时停止。设置
early_stopping_rounds=5是一个合理的选择。此时,训练过程中验证分数连续5轮恶化就会停止;
- eval_set:在指定early_stop_rounds时,需要指定验证集来计算验证分数,如eval_set=[(X_valid, y_valid)];
- eval_metric:计算目标函数值的方式,默认取值为objective中的参数的取值,根据目标函数的形式,回归问题默认为rmse,分类问题为error,还有以下几种:

- 还有importance_type:可以查询各个特征的重要性程度,可以选择“gain”、“weight”,“cover”,“total gain”或者“total cover”,然后通过booster中的get_score方法获得对应的特征权重。“weight”通过特征被选中作为分裂特征的计数来计算重要性,“gain”和“total gain”则通过分别计算特征被选中最为分裂特征所带来的增益和总增益来计算重要性,“cover”和“total cover”通过计算特征被选中作分裂时的平均样本覆盖度和总体样本覆盖度来计算重要性。
以上就是XGBoost的基本参数,通常先通过网格搜索找出比较合适的n_estimators和learning_rate的组合,然后调整max_depth和gamma,查看模型的处于什么样的状态(过拟合还是欠拟合)然后再决定是否进行剪枝调整其他参数,通常来说是需要进行剪枝的,为了增强模型的泛化能力,因为XGB属于天然过拟合模型。
XGBoost的实例及调参
下面我们就来使用XGBoost进行分类,数据集采用Kaggle入门比赛中的Titanic数据集来根据乘客特征,预测是否生存,数据集的下载可以在官网网站中:https://www.kaggle.com/c/titanic,数据集包含train、test和gender submission,首先来导入数据并对数据进行有个初步的认知:
import pandas as pd
import numpy as np
import seaborn as sns
import missingno as msno_plot
import matplotlib.pyplot as plt train_data = pd.read_csv('./train.csv')
test_data = pd.read_csv('./test.csv') train_data.describe()
test_data.describe()
可以看到训练数据有891条,测试集有418条数据。由于我们是要利用乘客特征预测是否生还“Survive”,测试集上没有直接给出结果,因此我们就拿训练集上的数据进行训练和测试。(由于目前Kaggle需要爬梯子提交,暂时先不提交验证了)。
然后是对数据进行一个初步的分析,首先查看是否存在缺失值:
plt.figure(figsize=(10, 8))
msno_plot.bar(train_data)
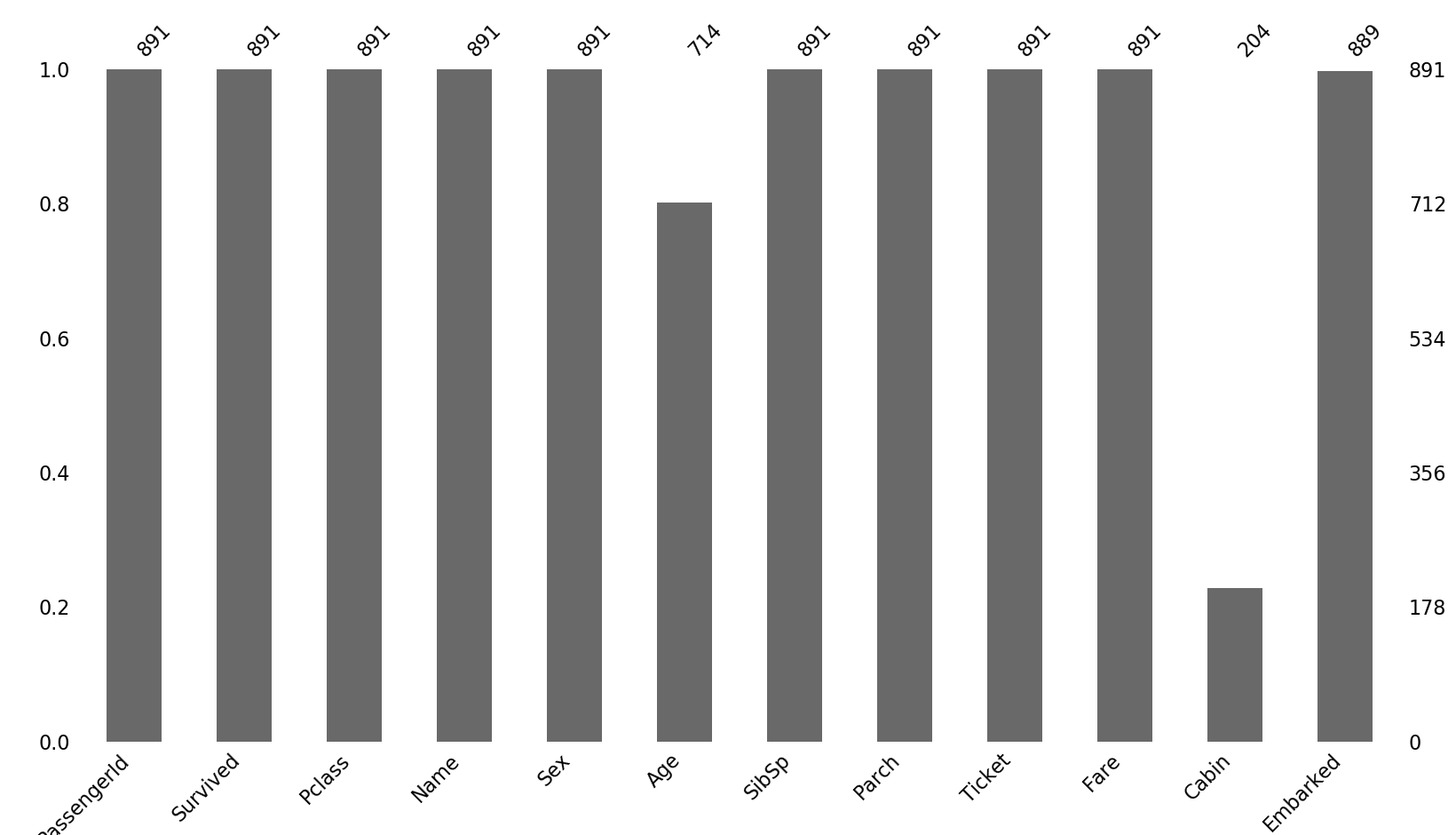
可以看到Age属性和Cabin属性还是存在很多缺失值的,同时由于生存与否与姓名、PassengerId、Ticket无关(主观认知),这里先对这几个属性特征进行删除,由于Cabin缺失值较多,且为非数值型数据,这里也暂且删除,然后将Age属性缺失值填补Age的均值(为简单起见,还有其他很多方式),Embark属性填补出现最多的值:
# 删除属性
train_data.drop(['Name', 'PassengerId', 'Ticket', 'Cabin'], axis=1, inplace=True)
test_data.drop(['Name', 'PassengerId', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 填补缺失值
train_data['Age'].fillna(30, inplace=True)
train_data['Embarked'].fillna('S', inplace=True)
test_data['Age'].fillna(30, inplace=True)
test_data['Embarked'].fillna('S', inplace=True) for i in range(8):
plt.subplot(241+i)
sns.countplot(x=train_data.iloc[:, i])
填补后的数据分布如上图中,然后就是对一些属性进行数值化处理,主要有Sex和Embark:
train_data['Sex'].replace('male', 0, inplace=True)
train_data['Sex'].replace('female', 1, inplace=True)
train_data['Embarked'] = [0 if example == 'S' else 1 if example=='Q' else 2 for example in train_data['Embarked'].values.tolist()]
这里数据就初步处理完成了,处理后的数据包含7个特征和1个类别“Survive”,然后就要开始利用XGBoost对数据进行分类了,首先导入所需要的包:
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
将数据进一步分为训练集和测试集两部分:
trainX, testX, trainy, testy = train_test_split(train_data.drop(['Survived'], axis=1), train_data['Survived'], test_size=0.2, random_state=10)
然后我们初始随便给定一组参数建立一个模型:
model = xgb.XGBClassifier(learning_rate=0.1, n_estimators=100, max_depth=6, min_child_weight=1, gamma=0, subsample=1,
objective='binary:logistic')
model.fit(trainX, trainy)
print(model.score(trainX, trainy))
#0.9269662921348315
可以看到在训练集上的分数已经很高了,然后利用GridSearchCV进行调参,首先调整n_estimators和max_depth两个参数,调参方法跟GBDT中一样:
gsearch = GridSearchCV(estimator=model, param_grid={'n_estimators': range(10, 301, 10), 'max_depth': range(2, 7, 1)})
gsearch.fit(trainX, trainy)
means = gsearch.cv_results_['mean_test_score']
params = gsearch.cv_results_['params']
for i in range(len(means)):
print(params[i], means[i])
print(gsearch.best_score_)
print(gsearch.best_params_)
# 0.8244262779474048
# {'max_depth': 5, 'n_estimators': 30}
可以看到分数降低了很多,说明原先模型确实存在过拟合,接下来继续调整gamma和subsample参数:
model2 = xgb.XGBClassifier(learning_rate=0.1, n_estimators=30, max_depth=5, min_child_weight=1, gamma=0, subsample=1,
objective='binary:logistic', random_state=1)
gsearch = GridSearchCV(estimator=model2, param_grid={'gamma': np.linspace(0, 1, 11), 'subsample': np.linspace(0.1, 1, 10)})
gsearch.fit(trainX, trainy)
means = gsearch.cv_results_['mean_test_score']
params = gsearch.cv_results_['params']
for i in range(len(means)):
print(params[i], means[i])
print(gsearch.best_score_)
print(gsearch.best_params_)
# 0.825824879346006
# {'gamma': 0.7, 'subsample': 0.7}
分数略微提升了一些,继续调整min_child_weight参数:
model3 = xgb.XGBClassifier(learning_rate=0.1, n_estimators=30, max_depth=5, min_child_weight=1, gamma=0.7, subsample=0.7,
objective='binary:logistic', random_state=1, silent=False)
gsearch = GridSearchCV(estimator=model3, param_grid={'min_child_weight': range(1, 11)})
gsearch.fit(trainX, trainy)
# 0.825824879346006
# {'min_child_weight': 1}
分数已经不再提升了,应该是已经达到极限了,再进行正则化也没有意义了,这里尝试了一下:
model4 = xgb.XGBClassifier(learning_rate=0.1, n_estimators=30, max_depth=5, min_child_weight=1, gamma=0.7, subsample=0.7,
objective='binary:logistic', random_state=1)
gsearch = GridSearchCV(estimator=model4, param_grid={'reg_lambda': [1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1, 10, 100, 1000]})
gsearch.fit(trainX, trainy)
# 0.825824879346006
# {'reg_lambda': 1}
已经不能够再提升了,然后再次尝试改变learning_rate和n_estimators的值,成倍的放大和缩小相应的值,learning_rate缩小10倍,n_estimators放大10倍:
odel3 = xgb.XGBClassifier(learning_rate=0.01, n_estimators=300, max_depth=5, min_child_weight=1, gamma=0.7, subsample=0.7,
objective='binary:logistic', random_state=1, silent=False)
model3.fit(trainX, trainy)
model3.score(trainX, trainy)
# 0.848314606741573
再进一步提升发现分数已经不再增长,然后确定最终模型即为上述的model3,然后最后进行训练:
model3.fit(trainX, trainy, early_stopping_rounds=10, eval_metric='error', eval_set=[(testX, testy)])
print(model3.score(trainX, trainy))
print(model3.score(testX, testy))
# 0.84831460674157
# 0.875
利用前面GBDT算法,找到的一组参数,所带来的表现跟XGBoost差不多,略微低于XGBoost一点:
model3_2 = GradientBoostingClassifier(n_estimators=80, learning_rate=0.1, subsample=0.7, max_depth=5, max_features=7, min_samples_leaf=31, min_samples_split=17)
model3_2.fit(trainX, trainy)
print(model3_2.score(trainX, trainy))
print(model3_2.score(testX, testy))
# 0.875
# 0.8547486033519553
但总体来说准确率并不是很高,这个可能数据处理不当等问题吧,后面会找一下原因,该数据集只作为算法的训练和熟悉用,在某乎上搜到一些原因:“一般来说姓名对于预测能否生还没有太大的价值,但在这个赛题的设置下,适当的考虑姓名可以发挥意想不到的作用。如训练集中头等舱一个姓Abel(随便起的,但是ms确实有这样的实例)的男性生还了,那么测试集中头等舱同样姓Abel的女子和小孩则很可能也能够生还,因为一家子基本上男的活下来了老婆孩子也问题不大”。所以这里就不深究了,后面会找其他一些数据集再进行测试和训练。
到这里集成学习内容已基本完了,后面还是要利用一些有价值的数据集进行实战,此外还有一个lightGBM算法,但lightGBM在算法本身的优化的内容不多。更多的还是运行速度提升和内存占用降低。唯一值得讨论的是它的决策树深度分裂方式,相比之下XGBoost使用的决策树广度分裂方式。后面有时间会对这一算法进行了解,之后可能在进行算法学习的同时对机器学习的一些基础知识进行整理和回顾。
【Python机器学习实战】决策树与集成学习(七)——集成学习(5)XGBoost实例及调参的更多相关文章
- 【Python机器学习实战】决策树和集成学习(一)
摘要:本部分对决策树几种算法的原理及算法过程进行简要介绍,然后编写程序实现决策树算法,再根据Python自带机器学习包实现决策树算法,最后从决策树引申至集成学习相关内容. 1.决策树 决策树作为一种常 ...
- 【Python机器学习实战】决策树与集成学习(六)——集成学习(4)XGBoost原理篇
XGBoost是陈天奇等人开发的一个开源项目,前文提到XGBoost是GBDT的一种提升和变异形式,其本质上还是一个GBDT,但力争将GBDT的性能发挥到极致,因此这里的X指代的"Extre ...
- 机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理、源码解析及测试
机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理.源码解析及测试 关键字:决策树.python.源码解析.测试作者:米仓山下时间:2018-10-2 ...
- Python 机器学习实战 —— 监督学习(下)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- Python 机器学习实战 —— 无监督学习(上)
前言 在上篇<Python 机器学习实战 -- 监督学习>介绍了 支持向量机.k近邻.朴素贝叶斯分类 .决策树.决策树集成等多种模型,这篇文章将为大家介绍一下无监督学习的使用.无监督学习顾 ...
- Python 机器学习实战 —— 监督学习(上)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- Python 机器学习实战 —— 无监督学习(下)
前言 在上篇< Python 机器学习实战 -- 无监督学习(上)>介绍了数据集变换中最常见的 PCA 主成分分析.NMF 非负矩阵分解等无监督模型,举例说明使用使用非监督模型对多维度特征 ...
- python机器学习实战(一)
python机器学习实战(一) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7140974.html 前言 这篇notebook是关于机器 ...
- python机器学习实战(二)
python机器学习实战(二) 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7159775.html 前言 这篇noteboo ...
随机推荐
- 2021年最新字节跳动Android面试真题解析
概述 时间过得是真TM快,回想自己是16年从学校毕业,现在是出来工作的第五个年头啦.在不同的大小公司都待过,就在前段时间顺利的完成了一次跳槽涨薪,面试了几家公司,最终选择了字节跳动.今特此前来跟大家进 ...
- Android太太太太太卷了,累了
我们聊到互联网行业的时候,一个不可避免的话题就是"内卷",而在程序员这个群体中,Android,绝对是卷得最厉害的. 毕竟前几年Android兴起的时候,入门门槛低,培训机构培养了 ...
- Quartz 实现同一辅助类 重复开启多任务
前言: 最近做一个项目,需要用到定时任务,第一就想到了Quartz,然后很开心的就实现了功能,但是后来发现一个问题,如果需要开启多个定时任务,需要写多个辅助类,而辅助类里面的功能基本差不多,这是我就想 ...
- Esxi安装Kali2并开启远程桌面
Kali安装 登录Vmware Esxi页面,选择"创建/注册虚拟机",步骤和创建其它Linux主机类似(Esxi的安装和介绍可以参考上一篇文章) 不同的地方是,客户机操作系统版本 ...
- 1~n数字中1出现的个数
1~n数字中1出现的个数 LeetCode 给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数. 感觉挺有意思 对于一个数,我们先局部分析一下,比如123456,我们考虑百位这个 ...
- 在STM32F401上移植uC/OS的一个小问题 [原创]
STM32F401xx是意法半导体新推出的Cortex-M4内核的MCU,相较于已经非常流行的STM32F407xx和STM32F427xx等相同内核的MCU而言,其特点是功耗仅为128uA/MHz, ...
- MySQL全面瓦解27:主从复制(原理 + 实践)
概念 主从复制,是指建立一个和主数据库完全一样的数据库环境(称为从数据库),并将主库的操作行为进行复制的过程:将主数据库的DDL和DML的操作日志同步到从数据库上, 然后在从数据库上对这些日志进行重新 ...
- Redis实现分布式锁那件事
今天我们来聊一聊分布式锁的那些事. 相信大家对锁已经不陌生了,我们在多线程环境中,如果需要对同一个资源进行操作,为了避免数据不一致,我们需要在操作共享资源之前进行加锁操作.在计算机科学中,锁(lock ...
- Proteus仿真—51单片机实现AC信号测频、显示、双机通信
文章目录 一.原理图部分 二.源码部分 单片机1 单片机2 在Proteus仿真软件里面使用STC89C52实现指定频率的AC信号的测频.显示.双机通信. 一.原理图部分 整体的电路图如示: DC-A ...
- comm tools
RTL:寄存器传输级别 LRM:语言参考手册 FSM:有限状态机 EDIF:电子数据交换格式 LSO:库搜索目录 XCF:XST 约束条件 1. par -ol. high 命令总是 '-'开头,参 ...