Easticsearch概述(ES、Lucene、Solr)一
ES是在Lucene的基础上实现的
1、Lucene全文检索
lucene是一个全文搜索框架,而不是应用产品。因此它并不像http://www.baidu.com/或goolge Destop 那么拿来就用,它只是提供了一种工具让你能实现这些产品
1、lucene能做什么呢
要回答这个问题,先要了解lucene的本质。实际上lucene的功能很单一,说到底,就是你给它若干个字符串,然后它为你提供一个全文搜索服务,告诉你你要搜索的关键词出现在哪里。知道了这个本质,你就可以发挥想象做任何符合这个条件的事情了,,你就可以吧站内新闻都索引了,做个资料库,你可以吧一个数据库表的若干个字段索引起来,那就不用担心因为“%like%”而锁表了;你也可以写个自己的搜索引。。
2、该不该选择lucene
下面给出一些测试数据,如果你觉得可以接受,那么可以接受
测试一:250万记录,300M左右文本,生成索引380M左右,800线程下平均处理时间300ms
测试二:37000记录,索引数据库中的两个varchar字段,索引文件2.6M,800线程下平均处理时间1.5ms
3、倒排索引
正排索引
我是中国人(1)
中国是全球人口最多的国家,中国人也最多
1、我, 是 , 中国 ,中国人
2、中国,是,全球。。。。
倒排索引
1、我 (1:1{0} #第一行出现一次,在第一行中偏移量0
2、中国 (1:1){2},(2:2){0,15} #第一行出现一次,偏移量2,第二行出现2次,偏移量0和15
文章数量和索引数量之间的关系?没关系
document:java instance
使用:
nutch爬虫
solr基于Lucene做的web项目,搜索引擎
数据存储:hadoop
数据计算:MapReduce
数据的随机存储:HBase
ElasticSearch介绍:
ElasticSearch是一个基于Lucene的实时的分布式搜索和分析引擎。设计用于云计算中,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。基于RESTFUL接口
ElasticSearch VS Solr总结
1、ES基本是开箱即用,非常简单。solr安装比较哦复杂
2、Solr利用Zookeeper进行分布式管理,而ES自身带有分布式协调管理功能
3、Solr支持数据格式:JSON、XML、CSV,而ES仅支持json文件格式
4、Solr官方提供的功能很多,而ES本身更注重于狠心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
5、Solr查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;ES建立索引快(即查询慢),即实时性查询快,用于facebook、GitHub、新浪等搜索
6、Solr是传统搜索应用的有力解决方案,但ES更适用于新兴的大数据实时搜索应用
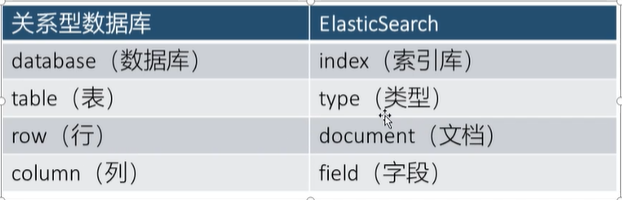
ES和关系型数据库对比
ES的优点
1、分布式:ES的自动发现机制会识别新增的节点并重新平衡分配数据
2、全文检索:ES后台使用Lucene提供全文检索,自带多语言支持、强大的查询语言、地理位置支持、上下文感知的建议、自动完成和搜索片段
3、近实时搜索和分析:数据从进入ES到能够搜索到是近实时的,除了搜索,ES也可以进行聚合分析操作
4、高可用:ES会自动发现新的或失败的节点,重组和重新平衡数据,确保数据是安全和可访问的
5、模式自由:ES的动态Mapping机制可以自动检测数据的结构和类型,创建索引,并使数据可搜索
6、RESTFUL API:几乎任何操作都可以使用一个简单的Restful API,JSON基于HTTP请求来实现,客户端也可以使用多种编程语言
ES应用场景:
站内搜索:Facebook、新浪微博、论坛等的站内搜索
NoSQl数据库:ES读写性能优于MongoDB,同时也支持地理位置查询
日志分析:日志分析由实时日志分析平台ELK完成,能够对日志进行集中的收集、存储、搜索、分析、监控以及可视化
ES的单机模式架构原理图:
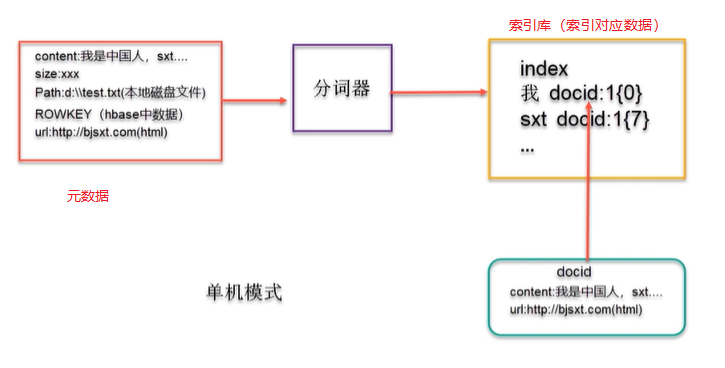
在单台ES服务器节点上,随着业务量的发张索引文件慢慢增多,会影响效率和内存存储问题等
可以采用ES集群,将单个索引的分片到多个不同分布式物理机器上存储,从而可以实现高可用、容错性等
ES集群中索引可能由多个分片构成,并且每个分片可以拥有多个副本,通过将一个单独的索引分为多个分片,我们可以处理不在一个单一的服务器上面运行的大型索引,简单的说就是索引的大小过大,导致效率问题。不能运行的原因可能是内存也可能是存储。由于每个分片可以有多个副本,通过将副本分配到多个服务器,可以提高查询的负载能力
ES集群架构图:
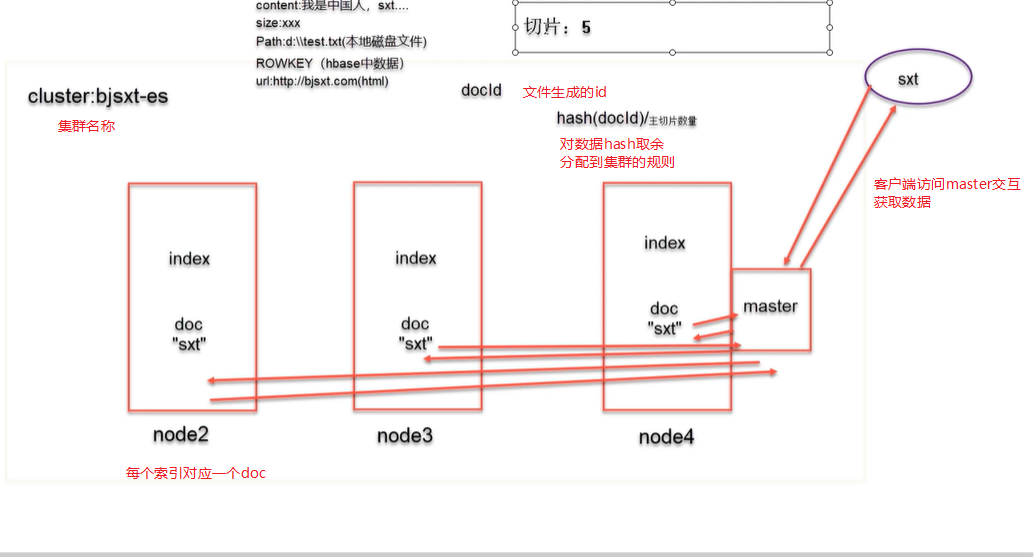
ES集群中的名词:
Cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点,这个结案是可以通过选举产生的,主从节点是对于集群内部来说。ES的一个概念就是去中心化,字面上理解就是务中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上时个整体,你与任何一个节点的通信和与整个ES集群通信时等价的
Shards
代表索引分片,es可以吧一个完整的索引分成多个分片,这样的好处是可以吧一个大的索引分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改
replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复,二十提高es的查询效率,es会自动对索引请求进行负载均衡
Recovery
代表数据恢复或数据重新分布。es在有节点假如或退出时会根据机器的负载均衡对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复
Easticsearch概述(ES、Lucene、Solr)一的更多相关文章
- Lucene/Solr开发经验
1.开篇语2.概述3.渊源4.初识Solr5.Solr的安装6.Solr分词顺序7.Solr中文应用的一个实例8.Solr的检索运算符 [开篇语]按照惯例应该写一篇技术文章了,这次结合Lucene/S ...
- apache lucene solr 官网历史版本下载地址
官网上一般只提供最新版本的下载,下面两个链接为所有历史版本的下载地址: lucene地址:archive.apache.org/dist/lucene/java/ solr地址:archive.apa ...
- Lucene/Solr搜索引擎开发笔记 - 第1章 Solr安装与部署(Jetty篇)
一.为何开博客写<Lucene/Solr搜索引擎开发笔记> 本人毕业于2011年,2011-2014的三年时间里,在深圳前50强企业工作,从事工业控制领域的机器视觉方向,主要使用语言为C/ ...
- Lucene/Solr搜索引擎开发笔记 - 第2章 Solr安装与部署(Tomcat篇)
一.安装环境 图1-1 Tomcat和Solr的版本 我本机目前使用的Java版本为JDK 1.8,因为Solr 4.9要求Java版本为1.7+,请注意. 二.Solr部署到Tomcat流程 图1- ...
- lucene&solr学习——solr学习(一)
1.什么是solr solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文检索服务器.Solr提供了比lucene风味丰富的查询语言,同时实现了可配置,可扩展,并对索 ...
- 全文检索(Lucene&Solr)
全文检索(Lucene&Solr) 1)什么是全文检索?为什么需要全文检索? 结构化数据(mysql等)方便查询,而非结构化数据(如多篇文章)是难以查询到自己需要的,所以要使用全文检索. 全文 ...
- Lucene&Solr框架之第二篇
2.1.开发环境准备 2.1.1.数据库jar包 我们这里可以尝试着从数据库中采集数据,因此需要连接数据库,我们一直用MySQL,所以这里需要MySQL的jar包 2.1.2.MyBatis的jar包 ...
- es与solr对比
solr相关资料 自带Jetty服务器,也可以在tomcat发布solr,默认端口8983: 利用SolrJ操作solr API: Document文档和JavaBean相互转换,用到@Field(& ...
- lucene/solr 修改评分规则方法总结
说明:由于solr底层使用的是lucene,因此修改solr打分机制归根结底还是依赖于lucene的打分机制,本文主要讨论lucene的打分机制. 本文说明lucene 常用的四种影响评分结果的方式. ...
随机推荐
- pwnable_start
第一次接触这种类型的题,例行检查一下 题目是32位 没有开启nx保护可以通过shellocode来获得shell 将题目让如ida中 由于第一次碰到这种题,所以我会介绍的详细一点, 可以看到程序中调用 ...
- CSAcademy Prefix Suffix Counting 题解
CSAcademy Prefix Suffix Counting 题解 目录 CSAcademy Prefix Suffix Counting 题解 题意 思路 做法 程序 题意 给你两个数字\(N\ ...
- LuoguP6857 梦中梦与不再有梦 题解
Update \(\texttt{2020.10.20}\) 增加了证明.感谢@东北小蟹蟹(dbxxxqwq)的提醒. Content 有一个 \(n\) 个点的无向图,每两个点之间都有一条边直接相连 ...
- 查看服务backlog大小 Send-Q
ss -ntl 如下图 LISTEN 状态: Recv-Q 表示的当前等待服务端调用 accept 完成三次握手的 listen backlog 数值,也就是说,当客户端通过 con ...
- InnoDB学习(五)之数据库锁
InnoDB存储引擎的默认隔离级别事可重复读,MVCC多版本并发控制仅仅解决了快照读情况下的数据隔离,而对于当前读,InnoDB通过锁来进行并发控制. InnoDB锁 本文主要参考了MySQL官方文档 ...
- AcWing 466. 回文日期
题目: 在日常生活中,通过年.月.日这三个要素可以表示出一个唯一确定的日期. 牛牛习惯用 8 位数字表示一个日期,其中,前 4 位代表年份,接下来 2 位代表月份,最后 2 位代表日期. 显然:一个日 ...
- 【LeetCode】910. Smallest Range II 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 【LeetCode】935. Knight Dialer 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 动态规划TLE 空间换时间,利用对称性 优化空间复杂 ...
- Chapter 20 Treatment-Confounder Feedback
目录 20.1 The elements of treatment-confounder feedback 20.2 The bias of traditional methods 20.3 Why ...
- css怎么实现雪人
冬天来了,怎么能少的了雪人呢,不管是现实中还是程序员的代码中统统都的安排上,那就一次安排几个雪人兄弟,咱们先看效果图: 有喜欢的就赶紧cv拿走吧!!! 其详细代码如下: 图1 html部分: < ...