【数据结构与算法Python版学习笔记】图——词梯问题 广度优先搜索 BFS
词梯Word Ladder问题
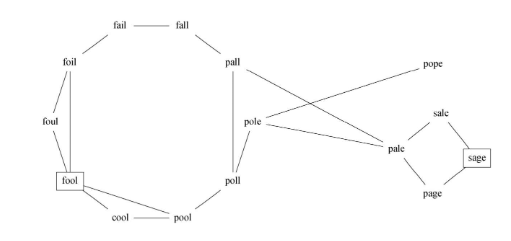
- 要求是相邻两个单词之间差异只能是1个字母,如FOOL变SAGE:
FOOL >> POOL >> POLL >> POLE >> PALE>> SALE >> SAGE
- 目标是找到最短的单词变换序列
- 用图表示单词之间的关系;
- 用一种名为
广度优先搜索 BFS的图算法找到从起始单词到结束单词的最短路径。
构建词梯图
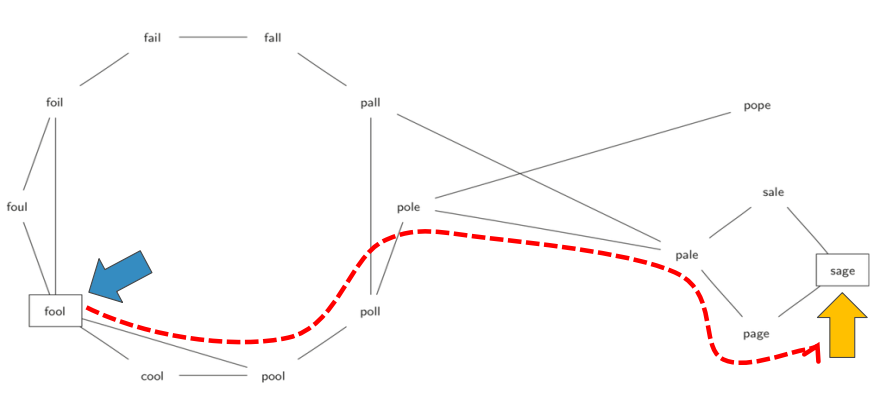
算法
- 首先是将所有单词作为顶点加入图中,再设法建立顶点之间的边
- 对每个顶点(单词) , 与其它所有单词进行比较, 如果相差仅1个字母, 则建立一条边
- 时间复杂度是O(n²),对于所有4个字母的5110个单词,需要超过2600万次比较
优化算法
- 改进的算法是创建大量的桶, 每个桶可以存放若干单词
- 桶标记是去掉1个字母,通配符“_”占空的单词
- 所有匹配标记的单词都放到这个桶里
- 所有单词就位后,再在同一个桶的单词之间建立边即可
- 单词关系图是一个非常稀疏的图
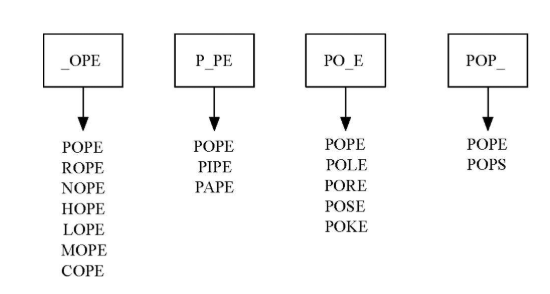
采用字典建立桶
def buildGraph(wordFile):
d = {}
g = Graph()
wfile = open(wordFile, 'r')
for line in wfile:
word = line[:-1]
for i in range(len(word)):
bucket = word[:i]+'_'+[i+1:]
if bucket in d:
d[bucket].append(word)
else:
d[bucket] = [word]
for bucket in d.keys():
for word1 in d[bucket]:
for word2 in d[bucket]:
if word1 != word2:
g.addEdge(word1, word2)
return g
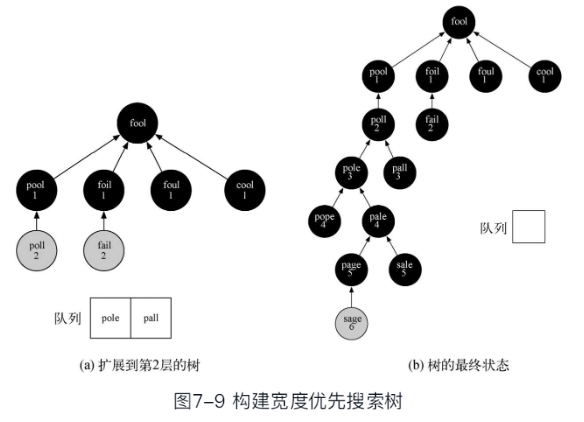
广度优先搜索 BFS (breadth first search)
在单词关系图建立完成以后, 需要继续在图中寻找词梯问题的最短序列
算法思路
- 给定图G, 以及开始搜索的起始顶点s
- BFS搜索所有从s可到达顶点的边
- 而且在达到更远的距离k+1的顶点之前, BFS会找到全部距离为k的顶点
- 可以想象为以s为根,构建一棵树的过程,从顶部向下逐步增加层次
- 广度优先搜索能保证在增加层次之前,添加了所有兄弟节点到树中
- 为了跟踪顶点的加入过程, 并避免重复顶点, 要为顶点增加3个属性
- 距离distance:从起始顶点到此顶点路径长度;
- 前驱顶点predecessor:可反向追溯到起点;
- 颜色color:
- 标识了此顶点是尚未发现(白色)
- 已经发现(灰色)
- 还是已经完成探索(黑色)
- 还需要用一个队列Queue来对已发现的顶点进行排列
决定下一个要探索的顶点(队首顶点)
算法过程
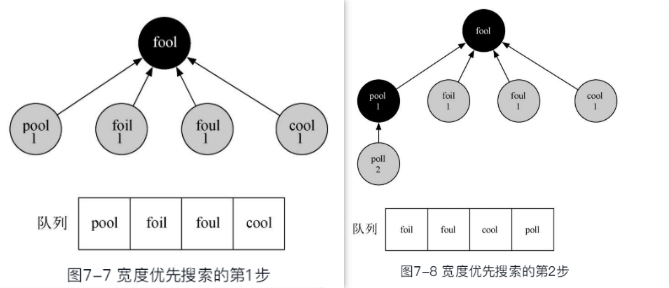
从起始顶点s开始, 作为刚发现的顶点,标注为灰色, 距离为0, 前驱为None,加入队列, 接下来是个循环迭代过程:
- 从队首取出一个顶点作为当前顶点;
- 遍历当前顶点的邻接顶点,如果是尚未发现的白色顶点,则将其颜色改为灰色(已发现),距离增加1,前驱顶点为当前顶点,加入到队列中
- 遍历完成后,将当前顶点设置为黑色(已探索过),循环回到步骤1的队首取当前顶点
代码
- 在以FOOL为起始顶点, 遍历了所有顶点, 并为每个顶点着色、 赋距离和前驱的代码
def bfs(g, start):
start.setDistance(0)
start.setPred(None)
vertQueue = Queue()
vertQueue.enqueue(start)
while(vertQueue.size > 0):
currentVert = vertQueue.dequeue()
for nbr in currentVert.getConnections():
if(nbr.getColor() == 'white'):
nbr.setColor('gray')
nbr.setDistance(currentVert.getDistance()+1)
nbr.setPred(currentVert)
vertQueue.enqueue(nbr)
currentVert.setColor('black')
- 最后,通过一个回途追溯函数来确定FOOL到任何单词顶点的最短词梯!
def traverse(y):
x = y
while(x.getPred()):
print(x.getId())
x = x.getPred()
print(x.getId())
完整代码
def buildGraph(wordFile):
d = {}
g = Graph()
wfile = open(wordFile, 'r')
for line in wfile:
word = line[:-1]
for i in range(len(word)):
bucket = word[:i]+'_'+[i+1:]
if bucket in d:
d[bucket].append(word)
else:
d[bucket] = [word]
for bucket in d.keys():
for word1 in d[bucket]:
for word2 in d[bucket]:
if word1 != word2:
g.addEdge(word1, word2)
return g
def bfs(g, start):
start.setDistance(0)
start.setPred(None)
vertQueue = Queue()
vertQueue.enqueue(start)
while(vertQueue.size > 0):
currentVert = vertQueue.dequeue()
for nbr in currentVert.getConnections():
if(nbr.getColor() == 'white'):
nbr.setColor('gray')
nbr.setDistance(currentVert.getDistance()+1)
nbr.setPred(currentVert)
vertQueue.enqueue(nbr)
currentVert.setColor('black')
def traverse(y):
x = y
while(x.getPred()):
print(x.getId())
x = x.getPred()
print(x.getId())
if __name__ == "__main__":
wordgrah = buildGraph("fourletterwords.txt")
bfs(wordgrah, wordgrah.getVertex('FOOL'))
traverse(wordgrah.getVertex('SAGE'))
算法分析
- BFS算法主体是两个循环的嵌套
- while循环对每个顶点访问一次,所以是O(|V|)
- 而嵌套在while中的for,由于每条边只有在其起始顶点u出队的时候才会被检查一次
- 而每个顶点最多出队1次,所以边最多被检查1次,一共是O(|E|)
- 综合起来BFS的时间复杂度为O(|V|+|E|)
- 词梯问题还包括两个部分算法
- 建立BFS树之后, 回溯顶点到起始顶点的过程,最多为O(|V|)
- 创建单词关系图也需要时间,最多为O(|V|2)
【数据结构与算法Python版学习笔记】图——词梯问题 广度优先搜索 BFS的更多相关文章
- 【数据结构与算法Python版学习笔记】目录索引
引言 算法分析 基本数据结构 概览 栈 stack 队列 Queue 双端队列 Deque 列表 List,链表实现 递归(Recursion) 定义及应用:分形树.谢尔宾斯基三角.汉诺塔.迷宫 优化 ...
- 【数据结构与算法Python版学习笔记】引言
学习来源 北京大学-数据结构与算法Python版 目标 了解计算机科学.程序设计和问题解决的基本概念 计算机科学是对问题本身.问题的解决.以及问题求解过程中得出的解决方案的研究.面对一 个特定问题,计 ...
- 【数据结构与算法Python版学习笔记】图——最短路径问题、最小生成树
最短路径问题 概念 可以通过"traceroute"命令来跟踪信息传送的路径: traceroute www.lib.pku.edu.cn 可以将互联网路由器体系表示为一个带权边的 ...
- 【数据结构与算法Python版学习笔记】图——强连通分支
互联网 我们关注一下互联网相关的非常巨大图: 由主机通过网线(或无线)连接而形成的图: 以及由网页通过超链接连接而形成的图. 网页形成的图 以网页(URI作为id)为顶点,网页内包含的超链接作为边,可 ...
- 【数据结构与算法Python版学习笔记】图——骑士周游问题 深度优先搜索
骑士周游问题 概念 在一个国际象棋棋盘上, 一个棋子"马"(骑士) , 按照"马走日"的规则, 从一个格子出发, 要走遍所有棋盘格恰好一次.把一个这样的走棋序列 ...
- 【数据结构与算法Python版学习笔记】图——拓扑排序 Topological Sort
概念 很多问题都可转化为图, 利用图算法解决 例如早餐吃薄煎饼的过程 制作松饼的难点在于知道先做哪一步.从图7-18可知,可以首先加热平底锅或者混合原材料.我们借助拓扑排序这种图算法来确定制作松饼的步 ...
- 【数据结构与算法Python版学习笔记】图——基本概念及相关术语
概念 图Graph是比树更为一般的结构, 也是由节点和边构成 实际上树是一种具有特殊性质的图 图可以用来表示现实世界中很多有意思的事物,包括道路系统.城市之间的航班.互联网的连接,甚至是计算机专业的一 ...
- 【数据结构与算法Python版学习笔记】查找与排序——散列、散列函数、区块链
散列 Hasing 前言 如果数据项之间是按照大小排好序的话,就可以利用二分查找来降低算法复杂度. 现在我们进一步来构造一个新的数据结构, 能使得查找算法的复杂度降到O(1), 这种概念称为" ...
- 【数据结构与算法Python版学习笔记】算法分析
什么是算法分析 算法是问题解决的通用的分步的指令的聚合 算法分析主要就是从计算资源的消耗的角度来评判和比较算法. 计算资源指标 存储空间或内存 执行时间 影响算法运行时间的其他因素 分为最好.最差和平 ...
随机推荐
- SQL语句之高级使用
1.select top select top 用于规定要返回的数据的数目 注意:并非所有的数据库系统都支持 SELECT TOP 语句. MySQL 支持 LIMIT 语句来选取指定的条数数据, ...
- TDSQL(MySQL版)之DB组件升级
随着数据库产品的更新迭代,修复bug等等,产品避免不了会出现升级的需求.TDSQL(MysqL版)也会有这方面的需求.接下来我就说说如何对现有TDSQL(MySQL版)集群组件进行升级,而不影响业务. ...
- rtl8188eu 驱动移植
测试平台 宿主机平台:Ubuntu 16.04.6 目标机:iMX6ULL 目标机内核:Linux 4.1.15 rtl8188eu 驱动移植 在网上下载Linux版的驱动源码: wifi驱动的实现有 ...
- Mysql常用sql语句(3)- select 查询语句基础使用
测试必备的Mysql常用sql语句系列 https://www.cnblogs.com/poloyy/category/1683347.html 前言 针对数据表里面的每条记录,select查询语句叫 ...
- MyBatis的Mapper代理笔记
MaBatis--Mapper代理 目前使用SqlSession进行增删改查的缺点: 没有办法实现多参传值 书写的时候没有接口,后期的维护低 使用Mapper的动态代理方式来解决问题 具体实现 首先我 ...
- openswan协商流程之(五):main_inR2_outI3()
主模式第五包:main_inR2_outI3 文章目录 主模式第五包:main_inR2_outI3 1. 序言 2.函数调用关系 3. 第五个报文流程图 4. main_inR2_outI3()源码 ...
- shell脚本中的多行注释
shell 中注释的使用方法 1. 单行注释 单行注释最为常见,它是通过一个'#'来实现的.注意shell脚本的最开始部分"#!/bin/bash"的#号不是用来注释的. 2. 多 ...
- vue项目 'node-sass'问题
Cannot find module 'node-sass' 解决办法: 运行命令:cnpm install node-sass@latest 即可解决,( 网络差的同学可以选择重新下载no-modu ...
- PULPino datasheet中文翻译并给了部分论文注释(前四章:Overview、Memory Map、CPU Core、Advanced Debug Unit)
参考: (1).PULPino datasheet:https://github.com/pulp-platform/pulpino/blob/master/doc/datasheet/datashe ...
- [第十六篇]——Docker 安装 CentOS之Spring Cloud直播商城 b2b2c电子商务技术总结
Docker 安装 CentOS CentOS(Community Enterprise Operating System)是 Linux 发行版之一,它是来自于 Red Hat Enterprise ...