[Python] 爬虫系统与数据处理实战 Part.1 静态网页
爬虫技术基础
- HTTP/HTTPS(7层):应用层,浏览器
- SSL:加密层,传输层、应用层之间
- TCP/IP(4层):传输层
- 数据在传输过程中是加密的,浏览器显示的是解密后的数据,对爬虫没有影响
- 中间人攻击:在传输过程中对数据包进行解析,抓包抓的是IP包,数据是加密的
- 网页类型
- 静态网页:HTML,或PHP+JSP后台写HTML
- 动态网页(前后分离):前端HTML+JavaScript,后端提供数据接口,js请求数据
- APP内嵌HTML(WebView引擎)
- 云端下发完整HTML(今日头条)
- 本地HTML模板+远程数据(微信)
- 移动端APP(抖音)
- 反编译APP
- 爬虫应用
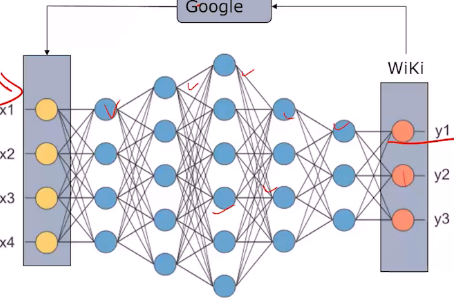
- 搜索引擎:google
- 推荐系统:今日头条
- 社交软件冷启动:探探(爬取新浪微博的数据构造假用户)
- 自然语言处理的训练集:先从维基爬取信息作为标注的输出结果集,再用google查询结果集作为训练集构建模型
- 图像训练:训练过滤器(照片、油画、素描),提高搜索准确性
- 关系分析:天眼查,记录全国所有公司股东信息、关联关系
- 价格追踪:pricegrabber,比价网站

HTTP
- 应用层协议
- 无连接:每次连接只处理一个请求(手机给电脑传数据,传完就拔线;有连接,socket通信,三次握手)
- 无状态:每次连接、传输都是独立的
- HEADER(头信息)、body(数据)
- Request(Client->Server)、Response(Server->Client)
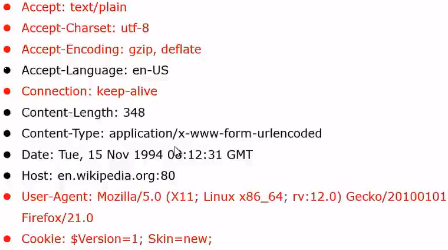
- Request 的 HTTP Header
Charset:编码,Python默认utf-8
Encoding:源代码压缩方式,不写不压缩
keep-alive:不关闭socket连接
User-Agent:客户端类型(手机、电脑打开淘宝网址,会自适应屏幕),爬虫代码中需要伪装成浏览器,通过服务器检查
Cookie:服务端response发放给客户端,客户端下次访问时携带方便识别(买了课的用户才能看视频,门票,证件),用于需要登录才能获取数据的网站(微博),登录--获取cookie--设置到header--爬取
- Request 方法
- GET:向服务器请求数据,只有header,没有body,安全(不修改服务器数据),抓网页用
- POST:向服务器发送内容,有header和body,不安全(可能修改服务器数据),抓API用
- Idempotent:幂等,多次操作结果不变

- Response的Header
- Location:跳转到地址
- Set-Cookie:服务端给客户端的Cookie
- Status:状态码,表示请求结果
- 2XX:成功
- 3XX:跳转(302:重定向,urllib2库会对重定向做处理,实现自动跳转)
- 4XX:客户端错误(401:未授权,403:拒绝提供服务,404:资源不存在)
- 5XX:服务器错误(500:服务器未知错误,503:服务器不能处理请求)
- 错误处理
- 400:Bad Request,检查请求的参数或路径
- 401:Unauthorized,需授权的网页的Cookie到期,尝试重新登录
- 403:Forbidden,需要登录的网站,尝试重新登录;IP被封,暂定爬取,增加爬虫等待时间
- 404:Not Found,直接丢弃
- 5XX:直接丢弃,并计数,如连续不成功,停止爬取
CSS
- class、id可帮助定位爬取内容
DOM树
- 通过路径找到内容
JavaScript
- 动态网页:如京东,价格信息通过js动态请求然后渲染,不能通过直接下载HTML获取信息
- 通过AJAX接口爬取,可能更简单
爬取原理
- 网页间通过<a>构成网页树
- 宽度优先:把孩子节点放入队列
- 深度优先
- 选取原则
- 重要网页距种子站点较近
- 万维网的深度并没有很深(<=17层),一个网页有很多路径可以到达
- 宽度优先有利于多爬虫合作爬取
- 深度限制与宽度优先结合(深度到达关注网页,再宽度抓取)
- 类比:学的深还是学的专?创业办某领域小公司还是平台型公司
- 深度优先注意限制层数,否则不会停
如何记录抓取历史
- 不重复抓取策略:记录已抓取网页,避免重复访问
- 保存在数据库中,效率较低(几十万以下可用)
- 用HashSet将访问的URL保存,只需O(1)代价就可查到是否访问过,消耗内存(URL可能很长)
- URL经MD5(都是16字节)或SHA-1等单向哈希后再保存到HashSet或数据库
- Java的HashTable是一个Hash表再跟一个链表,链表中保存碰撞结果
- Bit-Map方法,建立一个BitSet,将每个URL经哈希函数映射到某一BIT
- Bloom Filter:使用了多个哈希函数映射URL,减少碰撞,提高空间利用率,只能插入不能删除
- pip install murmurhash3 bitarray
- pip install pybloomfilter
如已经爬取了10w网页,又来了1个新网页,如何判断它是否在保存的10w个网页当中[爬虫陷阱]

如何提高效率
- 评估网站数量
- site:www.mafengwo.cn
- 选择合适HASH算法和空间阈值,降低碰撞几率
- 选择合适的存储结构和算法
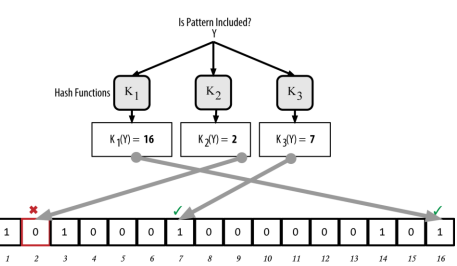
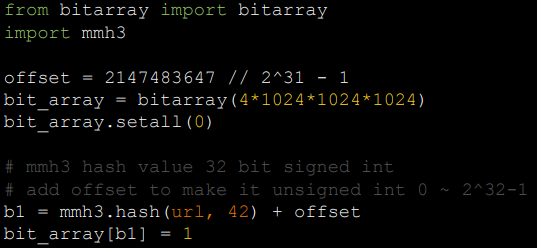
总结
- 多数情况不需要压缩,尤其网页数量少的情况
- 网页数量大的情况,使用Bloom Filter压缩
- 重点是验算碰撞概率,并根据碰撞概率来确定存储空间的阈值
- 分布式系统,将散列映射到多台主机的内存
[Python] 爬虫系统与数据处理实战 Part.1 静态网页的更多相关文章
- Python爬虫开发与项目实战
Python爬虫开发与项目实战(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1MFexF6S4No_FtC5U2GCKqQ 提取码:gtz1 复制这段内容后打开百度 ...
- Python爬虫开发与项目实战pdf电子书|网盘链接带提取码直接提取|
Python爬虫开发与项目实战从基本的爬虫原理开始讲解,通过介绍Pthyon编程语言与HTML基础知识引领读者入门,之后根据当前风起云涌的云计算.大数据热潮,重点讲述了云计算的相关内容及其在爬虫中的应 ...
- Python爬虫的概括以及实战
第一章主要讲解爬虫相关的知识如:http.网页.爬虫法律等,让大家对爬虫有了一个比较完善的了解和一些题外的知识点. 今天这篇文章将是我们第二章的第一篇,我们从今天开始就正式进入实战阶段,后面将会有更 ...
- Python爬虫系统学习(1)
Python爬虫系统化学习(1) 前言:爬虫的学习对生活中很多事情都很有帮助,比如买房的时候爬取房价,爬取影评之类的,学习爬虫也是在提升对Python的掌握,所以我准备用2-3周的晚上时间,提升自己对 ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- 如何让Python爬虫一天抓取100万张网页
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 王平 源自:猿人学Python PS:如有需要Python学习资料的 ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- python爬虫入门新手向实战 - 爬取猫眼电影Top100排行榜
本次主要爬取Top100电影榜单的电影名.主演和上映时间, 同时保存为excel表个形式, 其他相似榜单也都可以依葫芦画瓢 首先打开要爬取的网址https://maoyan.com/board/4, ...
随机推荐
- Typora标题自动编号+设定快捷键技巧
Typora标题自动编号 提示:要了解将这些CSS片段放在哪里,请参阅添加自定义CSS. 打开Typora偏好设置,打开主题文件夹,在主题文件夹中创建base.user.css文件,放置以下内容,则T ...
- 前端er必须知道的Git地址及常用工具地址
商城篇(找工作必练) 开源商城 推荐指数:5星,掌握了它,可以说,今后工作中的各种需求都不是问题,工作1~2年的也可以学习其中的思路(建议收藏). 这是一个集小程序/公众号/app为一体的商城系统,包 ...
- [BFS]电子老鼠闯迷宫
电子老鼠闯迷宫 Description 如下图12×12方格图,找出一条自入口(2,9)到出口(11,8)的最短路径. Input Output Sample Input 12 //迷宫大小 2 9 ...
- flexbox(弹性盒布局模型),以及适用场景
一.是什么 Flexible Box 简称 flex,意为"弹性布局",可以简便.完整.响应式地实现各种页面布局 采用Flex布局的元素,称为flex容器container 它的所 ...
- 【C++】 C++知识点总结
作者:李春港 出处:https://www.cnblogs.com/lcgbk/p/14643010.html 目录 前言 一.C++常用后缀 二.头文件 1.C++输入输出 2.在C++中使用C的库 ...
- 看过这篇剖析,你还不懂 Go sync.Map 吗?
hi, 大家好,我是 haohongfan. 本篇文章会从使用方式和原码角度剖析 sync.Map.不过不管是日常开发还是开源项目中,好像 sync.Map 并没有得到很好的利用,大家还是习惯使用 M ...
- 网络编程Netty IoT百万长连接优化
目录 IoT推送系统 IoT是什么 IoT推送系统的设计 心跳检测机制 简述心跳检测 心跳检测机制代码示例 百万长连接优化 连接优化代码示例 TCP连接四元组 配置优化 IoT推送系统 IoT是什么 ...
- 阿里巴巴面试-Java后端-社招5面技术总结(Offer已拿)
最近接到阿里妈妈的面试通知,历经一个月,虽然过程挺坎坷,但总算是拿到了offer.这里简单记录下面试所遇问题,仅供各位大佬参考. 由于前面两面的时间过去的有点久了,只能根据记忆大概写些记得问题. 部门 ...
- HTTP 基础(特性、请求方法、状态码、字段)
1. HTTP 简介(含义.特性.缺点) 2. HTTP 报文 3. GET 和 POST 4. 状态码 5. HTTP 头字段 1. HTTP 简介 HTTP 的含义 HTTP (HyperText ...
- eks 使用案例 部署jenkins
https://aws.amazon.com/cn/blogs/storage/deploying-jenkins-on-amazon-eks-with-amazon-efs/ 这个链接挺好的,包含了 ...