[DB] Spark Core (2)
RDD
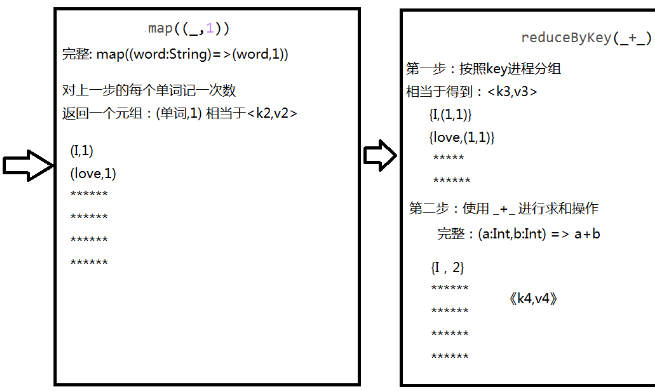
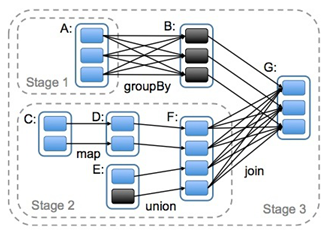
WordCount处理流程
- sc.textFile("/root/temp/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

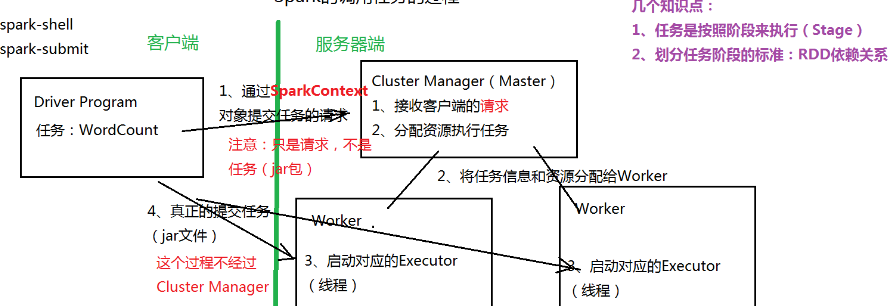
调用任务过程
- 客户端将任务通过SparkContext对象提交给Manager
- Manager将任务分配给Worker
- 客户端将任务提交给Worker
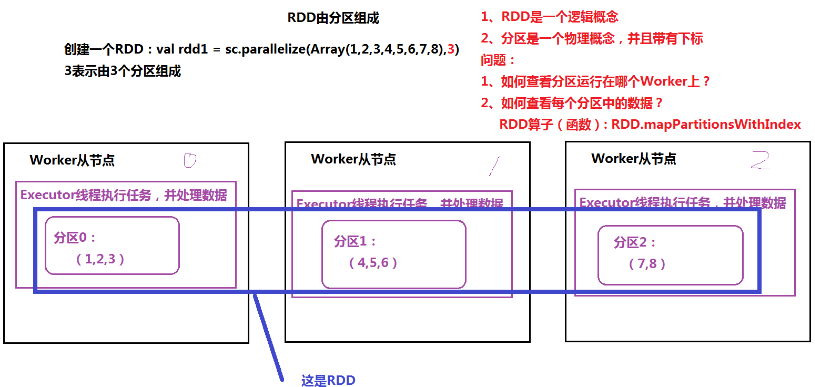
特性
- 由分区组成,每个分区运行在不同的worker上
- 通过算子(函数)处理每个分区中的数据
- RDD之间存在依赖关系(宽依赖、窄依赖),根据依赖关系,划分任务的Stage(阶段)
创建
- 通过集合创建:SparkContext.parallelize
- 通过读取外部数据源:HDFS,本地目录
算子(函数)
- Transformation:由一个RDD生成一个新的RDD。延时加载(计算)
- map(func):对原来的RDD进行某种操作,返回一个新的RDD
- filter(func):过滤
- flatMap(func):压平,类似Map
- mapPartitions(func):对RDD中的每个分区进行操作
- sample(withReplacement, fraction, seed)
- union(otherDataset):集合操作
- distinct([numTasks]):去重
- groupByKey([numTasks]):聚合操作(分组)
- sortByKey([ascending],[numTasks]):排序(针对<key,value>)
- sortBy()
- Action:对RDD计算出一个结果
- reduce(func)
- collect():
- foreach(func):类似map,但没有返回值
缓存
- 默认将RDD的数据缓存在内存中
- 提高性能
- 表示RDD可以被缓存,函数:persist 或 cache
容错
- 检查点(Checkpoint)
- 复习:HDFS中,由SecondaryNameNode进行日志的合并
- 一种容错机制,Lineage(血统)表示任务执行的声明周期(整个任务的执行过程)
- 血统越长,出错概率越大,出错时不需要从头计算,从最近检查点的位置往后计算即可
- 命令(本地模式和集群模式操作一样):
- sc.setCheckpointDir("/root/temp/spark"):指定检查点文件保存目录
- rdd1.checkpoint:标识RDD可以生成检查点
依赖
- 单步WordCount程序:
- val rdd1 = sc.textFile("/root/temp/input/data.txt")
- val rdd2 = rdd1.flatMap(_.split(" "))
- val rdd3 = rdd2.map((_,1)) 完整: val rdd3 = rdd2.map((word:String)=>(word,1) )
- val rdd4 = rdd3.reduceByKey(_+_)
- rdd4.collect
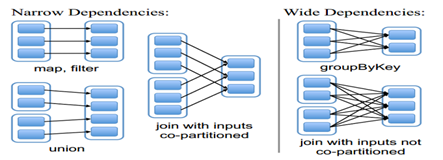
- 根据依赖关系划分任务执行的Stage(阶段)
- 宽依赖(类似“超生”):多个RDD的分区依赖了同一个父RDD分区(左父右子),如groupBy
- 窄依赖(类似“独生子女”):每个父RDD分区,最多被一个RDD的分区使用,如map
- 宽依赖是划分stage的依据
参考
官方API
http://spark.apache.org/docs/2.1.0/api/scala/index.html#org.apache.spark.package
[DB] Spark Core (2)的更多相关文章
- [DB] Spark Core (1)
生态 Spark Core:最重要,其中最重要的是RDD(弹性分布式数据集) Spark SQL Spark Streaming Spark MLLib:机器学习算法 Spark Graphx:图计算 ...
- [DB] Spark Core (3)
高级算子 mapPartitionWithIndex:对RDD中每个分区(有下标)进行操作,通过自己定义的一个函数来处理 def mapPartitionsWithIndex[U](f: (Int, ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9a7c0a1 转换为 spark.core.IViewport。
1.错误描述 TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9aa90a1 转换为 spark.core.IViewport. ...
- Spark Core
Spark Core DAG概念 有向无环图 Spark会根据用户提交的计算逻辑中的RDD的转换(变换方法)和动作(action方法)来生成RDD之间的依赖关系,同时 ...
- spark core (二)
一.Spark-Shell交互式工具 1.Spark-Shell交互式工具 Spark-Shell提供了一种学习API的简单方式, 以及一个能够交互式分析数据的强大工具. 在Scala语言环境下或Py ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
随机推荐
- 日志文件删除shell脚本
大日志文件切割shell脚本 #!/bin/bash # --------------------------------------------------------------------- # ...
- ( ) 与 { } 差在哪?-- Shell十三问<第七问>
( ) 与 { } 差在哪?-- Shell十三问<第七问> 先说一下,为何要用 ( ) 或 { } 好了. 许多时候,我们在 shell 操作上,需要在一定条件下一次执行多个命令,也就是 ...
- 2,turicreate入门 - 一个简单的回归模型
turicreate入门系列文章目录 1,turicreate入门 - jupyter & turicreate安装 2,turicreate入门 - 一个简单的回归模型 3,turicrea ...
- 99%的Python用户都不知道的f-string隐秘技巧
f-string想必很多Python用户都基础性的使用过,作为Python3.6版本开始引入的特性,通过它我们可以更加方便地向字符串中嵌入自定义内容,但f-string真正蕴含的功能远比大多数用户知道 ...
- AOE网与关键路径
声明:图片及内容基于https://www.bilibili.com/video/BV1BZ4y1T7Yx?from=articleDetail 原理 AOE网 关键路径 数据结构 核心代码 Topo ...
- PBFT共识算法详解
PBFT(Practical Byzantine Fault Tolerance,实用拜占庭容错) 一.概述 拜占庭将军问题最早是由 Leslie Lamport 在 1982 年发表的论文<T ...
- OAuth2.0理解和用法
现在网络的资料到处都是,很容易搜索到自己想要的答案.但答案通常只能解决自己一部分的问题.如果自己想要有一套自己的解决方案,还得重新撸一遍靠谱. 我需要学下OAuth2.0吗? 没看之前以为OAuth2 ...
- Math类的random()方法
Math类的random()方法 Math类的random()方法可以生成大于等于0.0.小于1.0的double型随机数. Math.random()方法语句基础上处理可获得多种类型.或任意范围的随 ...
- 2020.1 PyCharm 激活
1 下载安装 平台windows,官网: 选路径后, 选项分别是64位的快捷方式,添加运行目录到环境变量PATH,添加右键菜单"打开文件夹作为一个工程",python文件关联,按需 ...
- 如何使用natapp来实现内网穿透及案例
1. 业务场景 当我们的项目是部署在本地的时候,如何让其他用户(不在同一个局域网之下)来进行调用呢?这时我们就可以使用内网穿透将自己的IP通过映射成相应的地址,然后再通过映射后的地址来进行访问本地的项 ...