python 之爬虫基本流程
python 之爬虫基本流程
一 用户获取网络数据的方式:
方式1:浏览器提交请求--->下载网页代码--->解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中爬虫要做的就是方式2;

1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)
文件
三、http协议 请求与响应
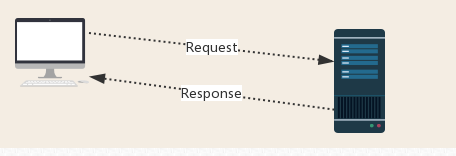
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据
四、 request
1、请求方式:
常见的请求方式:GET / POST
2、请求的URL
url全球统一资源定位符,用来定义互联网上一个唯一的资源 例如:一张图片、一个文件、一段视频都可以用url唯一确定
url编码
图片会被编码(看示例代码)
网页的加载过程是:
加载一个网页,通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
3、请求头
User-agent:请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户host;
cookies:cookie用来保存登录信息
注意: 一般做爬虫都会加上请求头
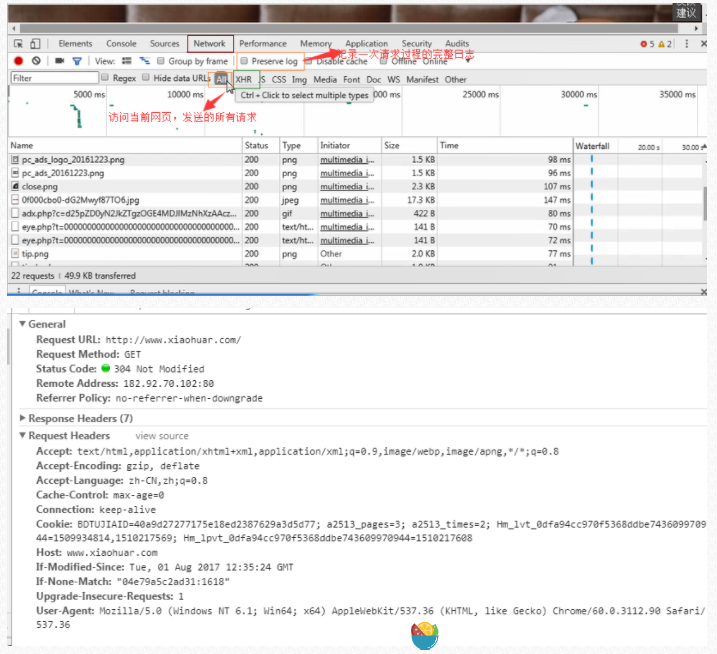
请求头需要注意的参数:
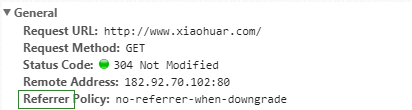
(1)Referrer:访问源至哪里来(一些大型网站,会通过Referrer 做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent:访问的浏览器(要加上否则会被当成爬虫程序)
(3)cookie:请求头注意携带
4、请求体
请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应Response
1、响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:无权限访问
502:服务器错误
2、respone header
响应头需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/:可能有多个,是来告诉浏览器,把cookie保存下来
(2)Content-Location:服务端响应头中包含Location返回浏览器之后,浏览器就会重新访问另一个页面
3、preview就是网页源代码
JSO数据
如网页html,图片
二进制数据等
python 之爬虫基本流程的更多相关文章
- python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件)
python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件) requests是一个Python第三方库,用于向URL地址发起请求 bs4 全名 BeautifulSoup4, ...
- [Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset.beachmark等等.但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的.最近在国内一家互联网公司实习, ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- Python简单爬虫记录
为了避免自己忘了Python的爬虫相关知识和流程,下面简单的记录一下爬虫的基本要求和编程问题!! 简单了解了一下,爬虫的方法很多,我简单的使用了已经做好的库requests来获取网页信息和Beauti ...
- python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程 在pycharm中打开此工程目录:并在Run中选择Edit Configuration 点击+创建一个Pytho ...
- Python开发爬虫之理论篇
爬虫简介 爬虫:一段自动抓取互联网信息的程序. 什么意思呢? 互联网是由各种各样的网页组成.每一个网页对应一个URL,而URL的页面上又有很多指向其他页面的URL.这种URL之间相互的指向关系就形成了 ...
- Python网络爬虫入门篇
1. 预备知识 学习者需要预先掌握Python的数字类型.字符串类型.分支.循环.函数.列表类型.字典类型.文件和第三方库使用等概念和编程方法. 2. Python爬虫基本流程 a. 发送请求 使用 ...
- python分布式爬虫打造搜索引擎--------scrapy实现
最近在网上学习一门关于scrapy爬虫的课程,觉得还不错,以下是目录还在更新中,我觉得有必要好好的做下笔记,研究研究. 第1章 课程介绍 1-1 python分布式爬虫打造搜索引擎简介 07:23 第 ...
- Python分布式爬虫抓取知乎用户信息并进行数据分析
在以前的文章中,我写过一篇使用selenium来模拟登录知乎的文章,然后在很长一段时间里都没有然后了... 不过在最近,我突然觉得,既然已经模拟登录到了知乎了,为什么不继续玩玩呢?所以就创了一个项目, ...
随机推荐
- 一文讲全了Python 类和对象内容
摘要:这是一个关于 Python 类和对象的全部内容. 本文分享自华为云社区<从零开始学python | Python 类和对象-面向对象编程>,原文作者:Yuchuan . Pytho ...
- Spring @Transaction 注解是如何执行事务的?
前言 相信小伙伴一定用过 @Transaction 注解,那 @Transaction 背后的秘密又知道多少呢? Spring 是如何开启事务的?又是如何进行提交事务和关闭事务的呢? 画图猜测 在开始 ...
- Kafka 总结学习
Kafka Need No Keeper 最近在鹅厂工作中不断接触到Kafka,虽然以前也使用过,但是对其架构和发展过程总是模模糊糊,所以在回学校准备末考的时候找些资料总结一下. Kafka Need ...
- Centos8.3、docker部署springboot项目实战记录
引言 目前k8s很是火热,我也特意买了本书去学习了一下,但是k8s动辄都是成百上千的服务器运维,对只有几台服务器的应用来说使用k8s就有点像大炮打蚊子.只有几台服务器的应用运维使用传统的tomc ...
- docker4-docker网络,容器编排,集群部署
1,docker网络 1.1,docker0 有三个网络环境,那么docker是如何处理容器网络访问的? 1.2,测试 docker run -d -p 80:8080 --name tomcat01 ...
- Java并发之ReentrantLock源码解析(四)
Condition 在上一章中,我们大概了解了Condition的使用,下面我们来看看Condition再juc的实现.juc下Condition本质上是一个接口,它只定义了这个接口的使用方式,具体的 ...
- k8s-生产环境部署django项目k8s-dashboard管理系统
1. k8s-生产环境部署django项目k8s-dashboard管理系统 gitee地址: https://gitee.com/scajy/django-k8s-dashboard.git 部署架 ...
- JUnit5的Tag、Filter、Order、Lifecycle
Tag JUnit5可以使用@Tag注解给测试类和测试方法打tag,这些tag能用来在执行时进行过滤,它跟group有点类似. tag应该遵循以下规则: 不能为null或者为空. 不能包含空格. 不能 ...
- SpringBoot:WebSocket使用Service层的方法
方法一: 创建工具类 ApplicationContextRegister.java import org.springframework.beans.BeansException; import o ...
- 25 Linux中的信号
Linux中的信号 信号是进程在运行过程中,由自身产生或由进程外部发过来的消息(事件).每个信号用一个整型常量宏表示,以SIG开头,比如SIGCHLD.SIGINT等,它们在系统头文件中定义,也可以通 ...