pandas 取 groupby 后每个分组的前 N 行
原始数据如下:
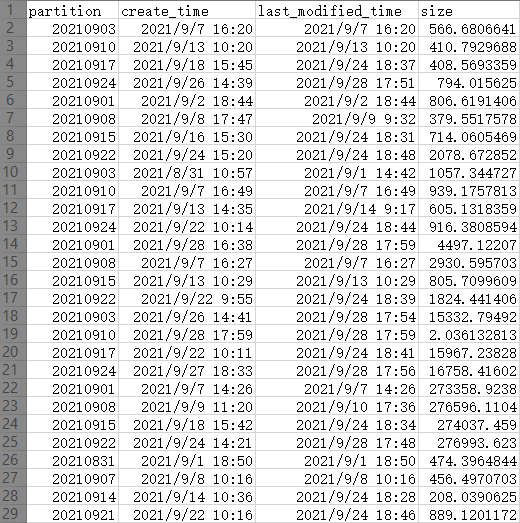
(图是从 excel 截的,最左1行不是数据,是 excel 自带的行号,为了方便说明截进来的)
除去首行是标题外,有效数据为 28行 x 4列
目前的需求是根据 partition 分组,然后取每组的前 2 行,如果不考虑排序,代码如下:
(把head()里面的数字改成 n 就可以取 n 行)
import pandas as pd
esp_df = pd.read_excel('excel文件路径', sheet_name='Sheet名')
esp_df.groupby(['partition', 'create_time', 'last_modified_time']).mean().reset_index(drop=False).groupby('partition').head(2)
结果如下:
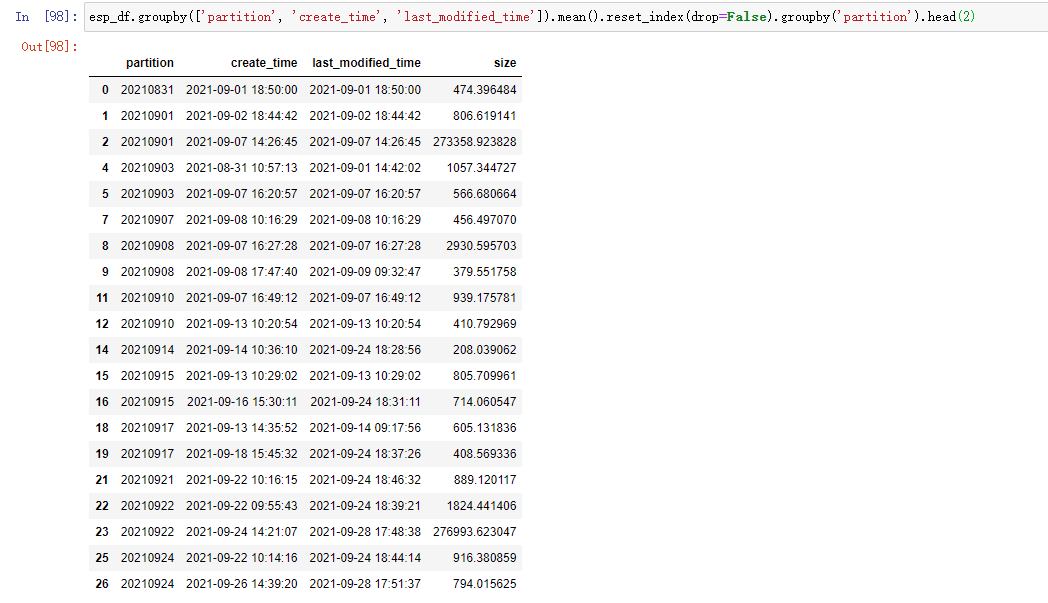
分别说明如下:
- groupby:分组,这里是根据数据中的 3 列来一起分组,因为我们并不需要做聚合运算,所以这么取可以保留原始数据不变。原始数据只有 4 列,这里 groupby 了 3 列,只剩下 size(其实把 size 放进去一起 groupby 也没问题)
- mean:求平均值,但是在这里没用,因为上一步的 groupby 取了前面的 3 列,在本例中,前 3 列并在一起就能得到一个唯一的一行,所以这里其实也只是每一行数据自己求平均数,结果等于它本身。同理,这里替代成求和函数
sum()也是一样的。但是不能省略,因为**省略后它就是一个DataFrameGroupBy类型的变量,不是DataFrame,而DataFrameGroupBy是没有后面的reset_index方法的 - reset_index:重置索引,groupby 之后,结果集的索引就变成了 groupby 里面的 key,这个
reset_index把这个索引重新退回为数据。
举例说明,在应用reset_index之前,即使用mean()之后的数据是这样的:

可以看到左边的 3 列,也就是 groupby key 的 partition、create_time、last_modified_time 是加粗了的,说明此时这 3 列都是索引;而且 partition 因为有相同的行,还被合并了。显然这不是我们想要的。reset_index 把它们重新放回到数据列里

参数中的 drop 作用是是否保留(重置前)的索引
数据就又回来了,索引变成了原来默认的(0123...)
- groupby:再次根据 partition 分组
- head: 取每个分组的前 n 行
如果要排序
本例中,如果要先根据 partition 分组,然后再根据 size 倒序(从大到小)再取前 2 行,则代码如下:
esp_df.groupby(['partition']).apply(lambda x: x.sort_values(["size"], ascending = False)).reset_index(drop=True).groupby('partition').head(2)
结果如下:

pandas 取 groupby 后每个分组的前 N 行的更多相关文章
- 第十三节:pandas之groupby()分组
1.Series()对象分组 1.1.单级索引 1.2.多级索引 2.DataFrame()对象分组 3.获取一个分组,遍历分组,filter过滤.
- pandas之groupby分组与pivot_table透视
一.groupby 类似excel的数据透视表,一般是按照行进行分组,使用方法如下. df.groupby(by=None, axis=0, level=None, as_index=True, so ...
- sql-实现select取行号、分组后在分组内排序、每个分组中的前n条数据
表结构设计: 实现select取行号 sql局部变量的2种方式 set @name='cm3333f'; select @id:=1; 区别:set 可以用=号赋值,而select 不行,必须使用:= ...
- pandas获取groupby分组里最大值所在的行,获取第一个等操作
pandas获取groupby分组里最大值所在的行 10/May 2016 python pandas pandas获取groupby分组里最大值所在的行 如下面这个DataFrame,按照Mt分组, ...
- Pandas之groupby分组
释义 groupby用来分组,调用groupby 之后返回pandas.core.groupby.generic.DataFrameGroupBy,其实就是由一个个格式为(key, 分组后的dataf ...
- sql server 分组,取每组的前几行数据
sql中group by后,获取每组中的前N行数据,目前我知道的有2种方法 比如有个成绩表: 里面有字段学生ID,科目,成绩.我现在想取每个科目的头三名. 1. 子查询 select * from ...
- mysql分组取最大(最小、最新、前N条)条记录
在数据库开发过程中,我们要为每种类型的数据取出前几条记录,或者是取最新.最小.最大等等,这个该如何实现呢,本文章向大家介绍如何实现mysql分组取最大(最小.最新.前N条)条记录.需要的可以参考一下. ...
- pandas之groupby分组与pivot_table透视表
zhuanzi: https://blog.csdn.net/qq_33689414/article/details/78973267 pandas之groupby分组与pivot_table透视表 ...
- Pandas系列(九)-分组聚合详解
目录 1. 将对象分割成组 1.1 关闭排序 1.2 选择列 1.3 遍历分组 1.4 选择一个组 2. 聚合 2.1 一次应用多个聚合操作 2.2 对DataFrame列应用不同的聚合操作 3. t ...
随机推荐
- MySQL-SQL基础-DCL
mysql> grant select,insert on sakila.* to 'zl'@'localhost' identified by '123'; Query OK, 0 rows ...
- Linux与Windows文件同步
Linux与Windows文件同步 本次采用的同步方式是rsync,Rsync是一款免费且强大的同步软件,可以镜像保存整个目录树和文件系统,同时保持原来文件的权限.时间.软硬链接.第一次同步时会复制全 ...
- https(ssl) 免费证书
https://letsencrypt.org/getting-started/ https://certbot.eff.org/lets-encrypt/centosrhel7-nginx http ...
- Java实现一个死锁
Java实现一个死锁 有一个藏宝图(treasureMapFragment)分成两份jack持有treasureMapFragment1残片1,json持有残片2.jack要求必须先看到json的残图 ...
- Install Docker Engine on CentOS 在CentOS 7 上安装Docker
Install Docker Engine on CentOS OS Requirements 系统要求 To install Docker Engine,you need a maintained ...
- hibernate关联关系(一对多)
什么是关联(association)关联指的是类之间的引用关系.如果类A与类B关联,那么被引用的类B将被定义为类A的属性.例如: class B{ private String name; } pub ...
- 从环境搭建到打包使用TypeScript
目录 1.TypeScript是什么 2.TypeScript增加了什么 3.TypeScript环境的搭建 4.TypeScript的基本类型 5.TypeScrip编译选项 6.TypeScrip ...
- Python__requests模块的基本使用
1 - 安装和导入 pip install requests import requests 2 - requsts的请求方法 requests.get('https://www.baidu.com/ ...
- Appium问题解决方案(2)- AttributeError:module 'appium.webdriver' has no attribute 'Remote'
背景 运行脚本的时候,就直接报这个错误了,然后去看了下 appium.webdriver 库 结果发现啥都没有,就知道有问题了,然后一步步排查 步骤一 检查Appium-Python-Client 和 ...
- JS003. 事件监听和监听滚动条的三种参数( addEventListener( ) )
全局 1 window.addEventListener('scroll', () => { 2 console.log('------') 3 console.log(document.doc ...