Transformer模型详解
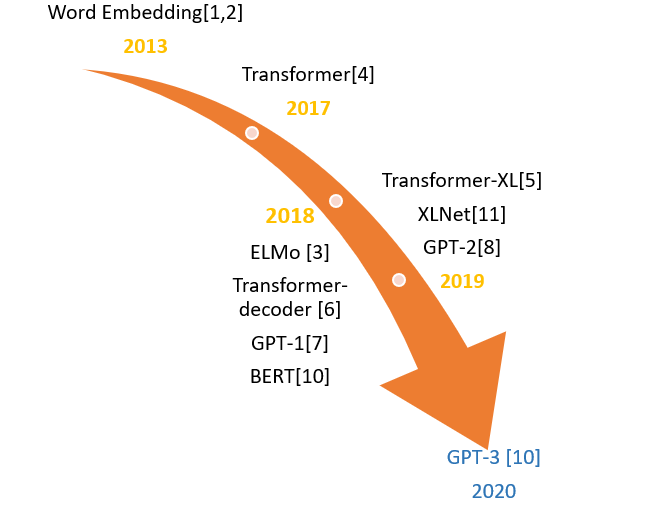
2013年----word Embedding
2017年----Transformer
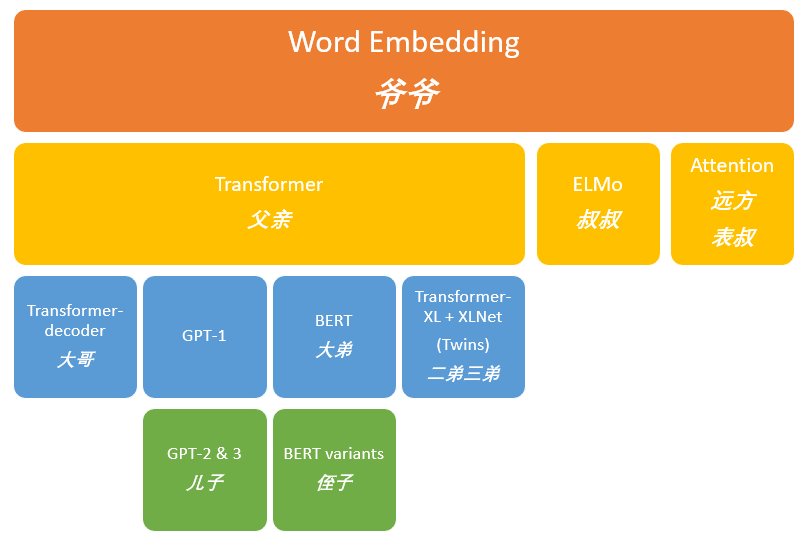
2018年----ELMo、Transformer-decoder、GPT-1、BERT
2019年----Transformer-XL、XLNet、GPT-2
2020年----GPT-3
Transformer
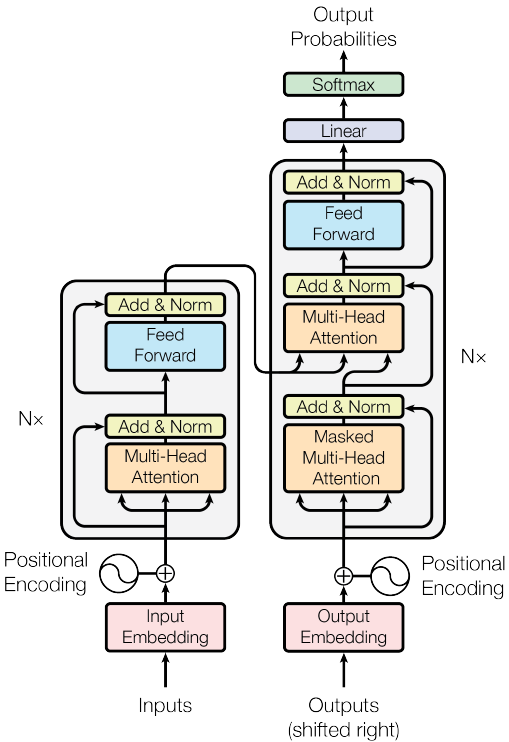
谷歌提出的Transformer模型,用全Attention的结构代替的LSTM,在翻译上取得了更好的成绩。这里基于Attention Is All You Need,对 Transformer 做一个介绍。模型结构如下图所示,模型包含 encoder 和 decoder 两部分,其中 encoder 包含 Nx 个(6个)当前单元,decoder 部分包含 Nx 个框中单元。下面我们分块对其进行描述。
Position Embedding
Encoder 的输入包含词向量和位置向量(Position Embedding),词向量 部分和正常的网络一样,通过学习获得,维度为$d_{model}$。位置向量 将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了。而位置向量则和以往不同,以往的位置向量是通过学习获得的,而这里谷歌提出了一种位置向量嵌入的方法:
$$\left\{\begin{array}{l}
P E_{2 i}(p)=\sin \left(p / 10000^{2 i / d_{p o s}}\right) \\
P E_{2 i+1}(p)=\cos \left(p / 10000^{2 i / d_{p o s}}\right)
\end{array}\right.$$
这里的意思是将id为$p$的位置映射为一个$d_{pos}$维的位置向量,这个向量的第$i$个元素的数值就是$PE_i(p)$。Google在论文中说到他们比较过直接训练出来的位置向量和上述公式计算出来的位置向量,效果是接近的。因此显然我们更乐意使用公式构造的Position Embedding了,我们称之为Sinusoidal形式的Position Embedding。
Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是:由于我们有$sin(\alpha +\beta )=sin\alpha cos\beta +cos\alpha sin\beta $以及$cos(\alpha +\beta )=cos\alpha cos\beta −sin\alpha sin\beta $,这表明位置$p+k$的向量可以表示成位置$p$的向量的线性变换,这提供了表达相对位置信息的可能性。
Encoder部分
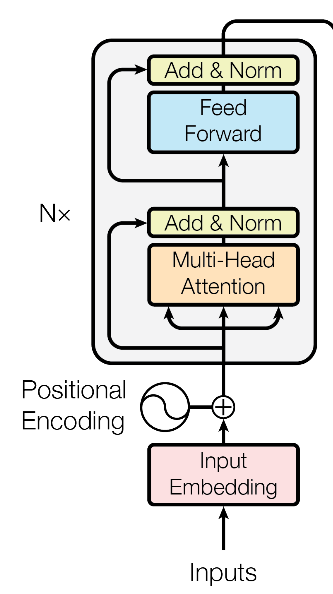
Encoder 部分由6个相同的子模块组成,每个子模块就是上面图中左侧那个方块了。包含几个子部分:
- Multi-Head Attention
- Residual connection
- Normalisation
- Position-wise Feed-Forward Networks
在Encoder 内部又可以看做包含两个子层,一个是 Multi-Head Self-Attention为主,另一个是 Position-wise Feed-Forward Networks,每个子层内的运算可以总结为:
$$sub\_layer\_output = LayerNorm(x + (SubLayer(x)))$$
接下来着重介绍 两个子层。Multi-Head Self-Attention由 Scaled Dot-product Attention 和 Multi-Head Attention 以及 Self Attention 组成,下面依次进行讲解。
Scaled Dot-Product Attention
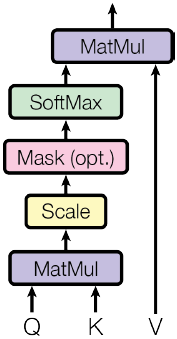
$$Attention(Q,\ K,\ V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$$
其中$Q,K,V$分别是query、key、value,他们的shape分别为$(n×d_k)、(m×d_k)、(m×d_v)$。这个公式相比于正常的Dot Attention多了一个缩放因子$\frac{1}{\sqrt{d_k}}$,这个缩放因子可以防止内积过大,防止它经过 softmax 后落入饱和区间,因为饱和区的梯度几乎为0,容易发生梯度消失。如果忽略激活函数softmax的话,那么事实上它就是$Q,K,V$三个矩阵相乘,最后的结果是一个$n×d_v$的矩阵。于是我们可以认为:这是一个Attention层,将序列$Q$编码成了一个新的$n×d_v$的序列。我们可以理解为:Q通过与K内积并sofrmax的方式,来得到Q与V的相似度。
在这个 scaled dot-product attention 中,还有一个 mask部分,在训练时它将被关闭,在测试或者实际使用中,它将被打开去遮蔽当前预测词后面的序列。
事实上这种Attention的定义并不新鲜,但由于Google的影响力,我们可以认为现在是更加正式地提出了这个定义,并将其视为一个层来看待;此外这个定义只是注意力的一种形式,还有一些其他选择,比如$query$跟$key$的运算方式不一定是点乘(还可以是拼接后再内积一个参数向量),甚至权重都不一定要归一化,等等。
Multi-Head Attention
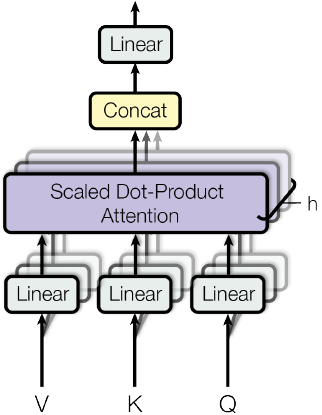
Multi-Head Attention就是把$Q,K,V$通过参数矩阵映射一下,然后再做Attention,把这个过程重复做$h$次,结果拼接起来。具体来说
$$\begin{equation}head_i = Attention(\boldsymbol{Q}\boldsymbol{W}_i^Q,\boldsymbol{K}\boldsymbol{W}_i^K,\boldsymbol{V}\boldsymbol{W}_i^V)\end{equation}$$
其中$W_i^Q、W_i^K、W_i^V$的shape分别为$(d_k\times \tilde{d}_k)、(d_k\times \tilde{d}_k)、(d_v\times \tilde{d}_v)$,然后
$$\begin{equation}MultiHead(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = Concat(head_1,...,head_h)\end{equation}$$
最后得到一个$n\times (h\tilde{d}_v)$的序列,所谓Multi-Head(多头),就是只多做几次同样的事情(参数不共享),然后把结果拼接。其中需要注意的是,一方面不同的head的矩阵是不同的,另一方面multi-head-Attention可以并行计算,论文里$h=8,d_k=d_v=d_{model}/4=64$
一般来说一个多头 attention 的效果要优于单个 attention。按照谷歌官方的说法,这么做形成多个子空间,可以让模型关注不同方面的信息,体现出差异性。但有实验表明,头之间的差距随着所在层数变大而减小,因此这种差异性是否是模型追求的还不一定。
至于头数 h 的设置,并不是越大越好,到了某一个数就没效果了。
Self Attention
在Google的论文中,大部分的Attention都是Self Attention,即“自注意力”,或者叫内部注意力。也就是说,在序列内部做Attention,寻找序列内部的联系。体现在公式上就是$Attention(X,X,X)$,$X$是输入序列。内部注意力在机器翻译(甚至是一般的Seq2Seq任务)的序列编码上是相当重要的,而之前关于Seq2Seq的研究基本都只是把注意力机制用在解码端。
当然,更准确来说,Google所用的是Self Multi-Head Attention:
$$\begin{equation}\boldsymbol{Y}=MultiHead(\boldsymbol{X},\boldsymbol{X},\boldsymbol{X})\end{equation}$$
Position-wise Feed-Forward Networks
论文里说,它是一个前馈全连接网络,它被等同的应用到每一个位置上(Pplied to each position separately and identically),它由两个线性变换和ReLU激活函数组成:
$$FFN(x)=max(0,xW_1+b_1)W_2+b_2$$
这个线性变换被应用到各个位置上,并且它们的参数是相同的。不过不同层之间的参数就不同了。这相当于一个核大小为1 的卷积。
一个注意的地方是,$W_1$的维度是(2048,512),$W_2$是 (512,2048)。 即先升维,后降维,这是为了扩充中间层的表示能力,从而抵抗 ReLU 带来的模型表达能力的下降。
Decoder部分
Decoder 部分相比于 Encoder ,结构上多了一个 Masked Multi-Head Attention 子层,它对decoder 端的序列做 attention。相比于正常的 Scaled Dot-Product Attention,它在 Scale 后加了一个Mask 操作。这是因为在解码时并不是一下子出来的,它还是像传统 decoder 那样,一个时间步一个时间步的生成,因此在生成当前时间步的时候,我们看不到后面的东西,因此用 MASK 给后面的 遮住。
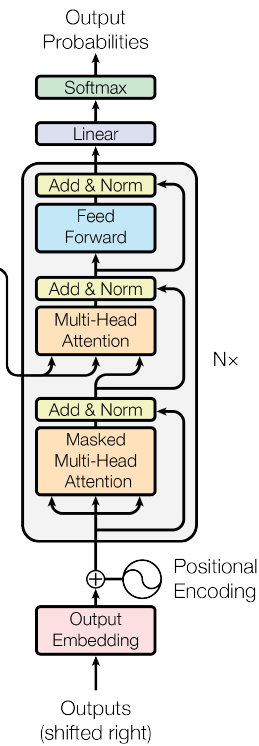
因此在解码时的流程为:
- 假设当前已经解码的序列为$s1,s2,…,st−1$,把该序列做词向量和位置向量嵌入
- 对上述向量做 Masked Multi-Head Attention,把得到的结果作为 Q
- Encoder 端的输出向量看做 K,V
- 结合 Q,K,V 做 Multi-Head Attention 和 FFN等操作
- 重复 decoder 部分 的子结构得到输出,而后解码得到输出词的概率
Attention的原理
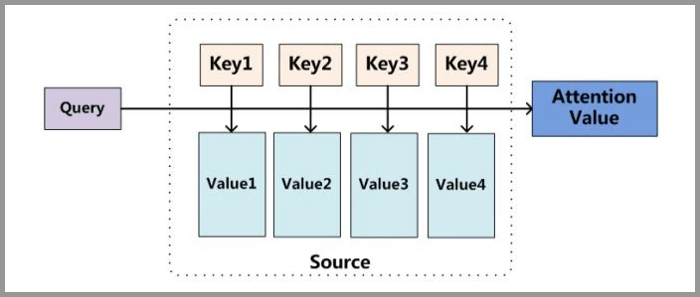
我罗列了两种理解方式,个人还是喜欢第一种,直接了当的,
直接解释:Source里面有很多value,为了方便查找,我们给每个value都标记一个key,当我们想要了解query的时候,就可以通过key去查找相关的value了。
案例解释:图书馆(source)里面有很多书(value),为了方便查找,我们给书做了编号(key),当我们想要了解漫威(query)的时候,我们就可以看看那些动漫、电影、甚至二战相关的书籍。
如果做阅读理解的话,Q可以是篇章的向量序列,取K=V为问题的向量序列,那么输出就是所谓的Aligned Question Embedding。
Attention原理的3步分解
第一步:query和key进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权值
第三步:将权值和value进行加权求和
从上面的建模,我们可以大致感受到Attention的思路简单,四个字“带权求和”就可以高度概括,大道至简。
Attention的N中类型
下面从模型结构、计算区域、所用信息、使用模型等方面对Attention的形式进行归类,如下图所示
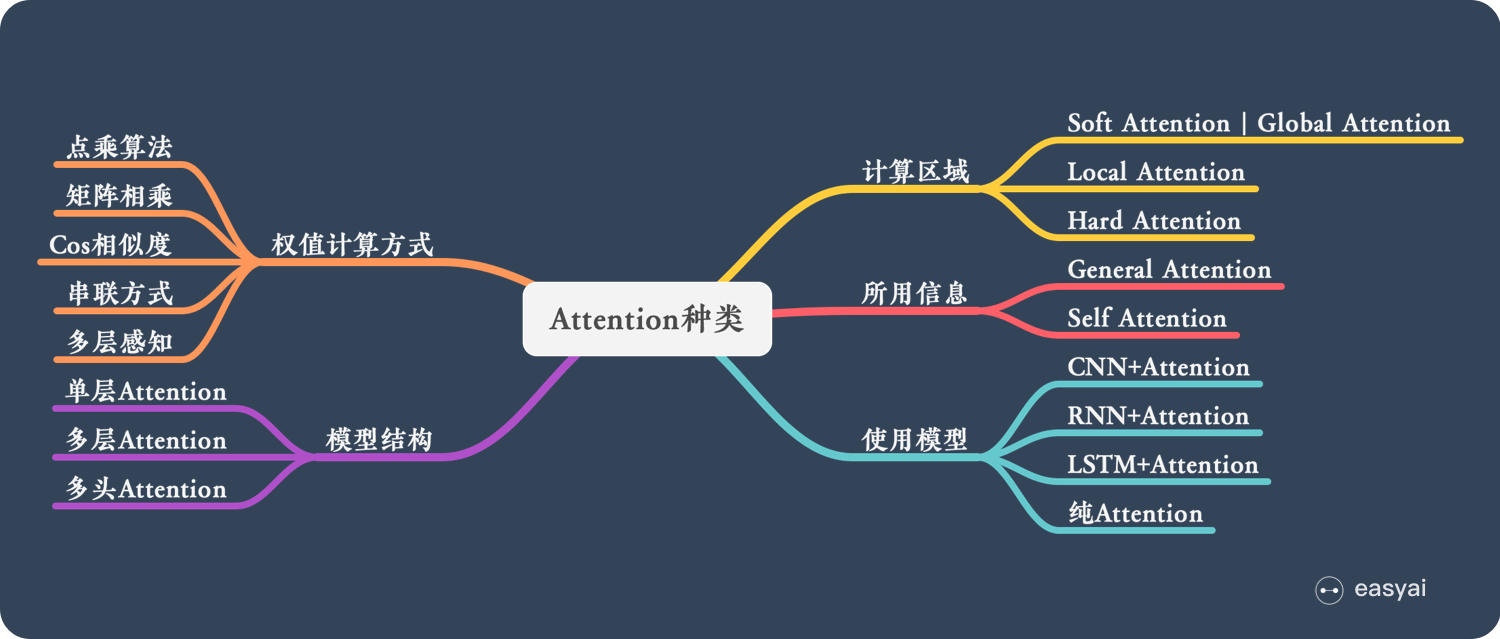
计算区域
根据Attention的计算区域,可以分成以下几种:
Soft Attention:这是比较常见的Attention方式,对所有key求权重概率,每个key都有对应的权重,是一种全局的计算方式(也可以叫做Global Attention)。这种方式比较理想,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。
Hard Attention:这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部都是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练(或者使用gumbel softmax子类的)。
Local Attention:这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
结构层次
单层Attention:用一个query对一段原文进行一次attention
多层Attention:一般用于文本具有层次关系的模型,假设我们把一个document划分成多个句子,在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),最后再用这个文档向量去做任务。
多头Attention:这是Attention is All You Need中提到的multi-head attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention
使用模型
从模型上看,Attention一般用在CNN和LSTM上,也可以直接进行纯Attention计算。
CNN+Attention:CNN的卷积操作可以提取重要特征,我觉得这也算是Attention的思想,但是CNN的卷积感受视野是局部的,需要通过叠加多层卷积区去扩大视野。另外,Max Pooling直接提取数值最大的特征,也像是hard attention的思想,直接选中某个特征。
- 在卷积操作前做Attention,比如Attention-Based BCNN-1,这个任务是文本蕴含任务需要处理两段文本,同时对两段输入的序列向量进行attention,计算出特征向量,再拼接到原始向量中,作为卷积层的输入。
- 在卷积操作后做attention,比如Attention-Based BCNN-2,对两段文本的卷积层的输出做attention,作为pooling层的输入。
- 在pooling层做attention,代替max pooling。比如Attention pooling,首先我们用LSTM学到一个比较好的句向量,作为query,然后用CNN先学习到一个特征矩阵作为key,再用query对key产生权重,进行attention,得到最后的句向量。
LSTM+Attention:LSTM内部有Gate机制,其中input gate选择哪些当前信息进行输入,forget gate选择遗忘哪些过去信息,我觉得这算是一定程度的Attention了,而且号称可以解决长期依赖问题,实际上LSTM需要一步一步去捕捉序列信息,在长文本上的表现是会随着step增加而慢慢衰减,难以保留全部的有用信息。LSTM通常需要得到一个向量,再去做任务,常用方式有:
- 直接使用最后的hidden state(可能会损失一定的前文信息,难以表达全文)
- 对所有step下的hidden state进行等权平均(对所有step一视同仁)。
- Attention机制,对所有step的hidden state进行加权,把注意力集中到整段文本中比较重要的hidden state信息。性能比前面两种要好一点,而方便可视化观察哪些step是重要的,但是要小心过拟合,而且也增加了计算量。
纯Attention:Attention is all you need,没有用到CNN/RNN,乍一听也是一股清流了,但是仔细一看,本质上还是一堆向量去计算attention。
Self-Attention优缺点
优点
参数少:self-attention的参数为$O(n^{2}d)$,而循环网络的参数为$O(nd^{2})$,卷积的参数为$O(knd^{2})$,当n远小于d时,self-attention更快
可并行化:RNN需要一步步递推才能捕捉到,而CNN则需要通过层叠来扩大感受野。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
捕捉全局信息:更好的解决了长时依赖问题,同时只需一步计算即可获取全局信息,在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。
缺点
计算量:可以看到,事实上Attention的计算量并不低。比如Self Attention中,首先要对X做三次线性映射,这计算量已经相当于卷积核大小为3的一维卷积了,不过这部分计算量还只是O(n)的;然后还包含了两次序列自身的矩阵乘法,这两次矩阵乘法的计算量都是$O(n^2)$的,要是序列足够长,这个计算量其实是很难接受的。
没法捕捉位置信息,即没法学习序列中的顺序关系。这点可以通过加入位置信息,如通过位置向量来改善,具体可以参考最近大火的BERT模型。
实践中 RNN 可以轻易解决的事,Transformer 没做到,如 复制 string,尤其是碰到比训练时的 序列更长时
Transformer vs CNN vs RNN
假设输入序列长度为$n$,每个元素的维度为$d$,输出序列长度也为$n$,每个元素的维度也是$d$。
可以从每层的计算复杂度、并行的操作数量、学习距离长度三个方面比较 Transformer、CNN、RNN 三个特征提取器。

计算复杂度
Self-Attention:考虑到 n 个 key 和 n 个 query 两两点乘,每层计算复杂度为 $O(n^2*d)$
RNN:考虑到矩阵(维度为$n*n$)和输入向量相乘,每层计算复杂度为$O(n*d^2)$
CNN:对于$k$个卷积核经过$n$次一维卷积,每层计算复杂度为$O(k*n*d^2)$。
深度可分离卷积:每层计算复杂度为 $O(k*n*d+n*d^2)$。
因此:
当$n\leq d$时,self attention 要比 RNN 和 CNN 快,这也是大多数常见满足的条件。
当$n>d$时,可以使用受限 self attention,即:计算 attention时仅考虑每个输出位置附近窗口的$r$个输入。这带来两个效果:
- 每层计算复杂度降为$O(r*n*d)$
- 最长学习距离降低为$r$,因此需要执行$O(n/r)$次才能覆盖到所有输入。
并行操作数量
可以通过必须串行的操作数量来描述
- 对于 self-attention,CNN,其串行操作数量为$O(1)$,并行度最大。
- 对于 RNN,其串行操作数量为$O(n)$,较难并行化。
最长计算路径
覆盖所有输入的操作的数量
- 对于self-attention,最长计算路径为$O(1)$;对于 self-attention stricted,最长计算路径为$O(n/r)$ 。
- 对于常规卷积,则需要$O(n/k)$个卷积才能覆盖所有的输入;对于空洞卷积,则需要$O(log_kn)$才能覆盖所有的输入。
- 对于 RNN,最长计算路径为$O(n)$
作为额外收益,self-attention 可以产生可解释性的模型:通过检查模型中的注意力分布,可以展示与句子语法和语义结构相关的信息。
代码
(不做Mask)
pytorch代码:https://github.com/jadore801120/attention-is-all-you-need-pytorch
tensorflow代码:https://github.com/bojone/attention/blob/master/attention_tf.py
keras代码:https://github.com/bojone/attention/blob/master/attention_keras.py
参考
【论文】《Attention Is All You Need》
【科学空间】《Attention is All You Need》浅读(简介+代码)
【华校专个人网站】Transformer的计算复杂度
【知乎问答】有了Transformer框架后是不是RNN完全可以废弃了?
【代码】Attention Is All You Need的代码
【easyaitech】一文看懂 Attention(本质原理+3大优点+5大类型)
【easyaitech】一文看懂 NLP 里的模型框架 Encoder-Decoder 和 Seq2Seq
Transformer模型详解的更多相关文章
- ASP.NET Core的配置(2):配置模型详解
在上面一章我们以实例演示的方式介绍了几种读取配置的几种方式,其中涉及到三个重要的对象,它们分别是承载结构化配置信息的Configuration,提供原始配置源数据的ConfigurationProvi ...
- ISO七层模型详解
ISO七层模型详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在我刚刚接触运维这个行业的时候,去面试时总是会做一些面试题,笔试题就是看一个运维工程师的专业技能的掌握情况,这个很 ...
- 28、vSocket模型详解及select应用详解
在上片文章已经讲过了TCP协议的基本结构和构成并举例,也粗略的讲过了SOCKET,但是讲解的并不完善,这里详细讲解下关于SOCKET的编程的I/O复用函数. 1.I/O复用:selec函数 在介绍so ...
- 第94天:CSS3 盒模型详解
CSS3盒模型详解 盒模型设定为border-box时 width = border + padding + content 盒模型设定为content-box时 width = content所谓定 ...
- JVM的类加载过程以及双亲委派模型详解
JVM的类加载过程以及双亲委派模型详解 这篇文章主要介绍了JVM的类加载过程以及双亲委派模型详解,类加载器就是根据指定全限定名称将 class 文件加载到 JVM 内存,然后再转化为 class 对象 ...
- 云时代架构阅读笔记六——Java内存模型详解(二)
承接上文:云时代架构阅读笔记五——Java内存模型详解(一) 原子性.可见性.有序性 Java内存模型围绕着并发过程中如何处理原子性.可见性和有序性这三个特征来建立的,来逐个看一下: 1.原子性(At ...
- css 06-CSS盒模型详解
06-CSS盒模型详解 #盒子模型 #前言 盒子模型,英文即box model.无论是div.span.还是a都是盒子. 但是,图片.表单元素一律看作是文本,它们并不是盒子.这个很好理解,比如说,一张 ...
- 图解机器学习 | LightGBM模型详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/34 本文地址:http://www.showmeai.tech/article-det ...
- flink内存模型详解与案例
任务提交时的一些yarn设置(通用客户端模式) 指定并行度 -p 5 \ 指定yarn队列 -Dyarn.appl ...
随机推荐
- 【LeetCode】952. Largest Component Size by Common Factor 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 并查集 日期 题目地址:https://leetco ...
- 【LeetCode】704. Binary Search 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 线性查找 二分查找 日期 题目地址:https:// ...
- oralce索引中INDEX SKIP SCAN 和 INDEX RANGE SCAN区别
INDEX SKIP SCAN 当表中建立有复合索引的时候,查询时,除复合索引第一列外,别的列作为条件时,且优化器模式为CBO,这个时候查询可能会用到INDEX SKIP SCAN skip scan ...
- Spring企业级程序设计 • 【第6章 深入Spring MVC开发】
全部章节 >>>> 本章目录 6.1 模型数据解析及控制器返回值 6.1.1 ModelAndView多种用法 6.1.2 Map添加模型数据和返回String类型值 6 ...
- 你还不了解SpringSecurity吗?快来看看SpringSecurity实战总结~
SpringSecurity简介: 权限管理中的相关概念 主体 principal: 使用系统的用户或设备或从其他系统远程登录的用户等等,简单说就是谁使用系统谁就是主体. 认证 authentic ...
- .NET5.0 依赖注入,关于 Autofac 使用
前置 工具 VS2019 概念 关于以下几个概念,自行百度. 控制反转:IoC(Inversion of Control) 依赖注入: 容器:DI 容器(.NET Core 自带),Autofac(本 ...
- redis-ha手动切换slave节点为master
仅做个人记录,请慎重参考!! 问题描述:使用redis-ha启动了3个pod,现在还有一个pod正常运行,并且为slave(理论上第一个起来的pod应该为master) 通过info命令查看下图 尝试 ...
- CSS基础 水平居中案例
html结构 <body> <div class="father"> <div class="son"></div&g ...
- Drupal 8 环境搭建部署
运行环境安装 系统:Ubuntu Server 16.04 (ubuntu-16.04.4-server-amd64.iso) Web服务器:Apache / 2.4.18 数据库:Mysql / ...
- Python_关于python2的encode(编码)和decode(解码)的使用
在使用Python2时,我们习惯于在文件开头声明编码 # coding: utf-8 不然在文件中出现中文,运行时就会报错 SyntaxError: Non-ASCII character... 之类 ...