mysqldump备份容灾脚本
一.备份脚本
环境需求
编辑/etc/my.cnf文件添加在[mysqld]版块下添加如下变量,添加后重启服务。
#开启,并且可以将mysql-bin改为其它的日志名
log-bin=mysql-bin
#添加id号,如果做主从,就不能一样
server-id=1
#超过200M将生产新的文件,最大和默认值是1GB
max_binlog_size=1G
#此参数表示binlog使用最大内存的数,默认1M。
max_binlog_cache_size=1M
#此参数表示binlog日志保留的时间,默认单位是天。
expire_logs_days=7
也可以用如下方式动态更改全局变量,连接mysql服务器后配置,不用重启服务器。
set GLOBAL expire_logs_days=7;
注意:设置之后并不会立即执行,需要如下条件
手动执行flush logs(注意,如果binlog文件过多会引发IO问题,并且flush 也不会同步到从库)
重新启动时(MySQL将会new一个新文件用于记录binlog)
全量脚本
mybak-all.sh,对脚本变量部分进行配置
#!/bin/bash
#使用:./xx.sh -uroot -p'123456',使用前修改脚本进行变量配置
#过程:备份并刷新binlog,将最新的binlog文件名记录并整体压缩打包
#恢复:先进行全量备份,再对根据tim-binlog.txt中的记录,进行逐个恢复
#提示:最多每分钟执行一次,否则会覆盖同分钟内的文件,可以修改脚本来改善
# 出现问题会退出,可以到指定的日志目录查看日志输出
# 同年的tar包超过指定天数的会删除掉
#[变量]
begin_time=`date +%F-%H-%M-%S`
my_sql="/usr/local/mysql/bin/mysql"
bak_sql="/usr/local/mysql/bin/mysqldump"
binlog_dir=/usr/local/mysql/data
bak_dir=/ops/bak
log_dir=/ops/log/mybak-all.log
#保存的天数,4周就是28天
save_day=28
#[自动变量]
#当前年月
date_nian=`date +%Y-`
#所有天数的数组
save_day_zu=($(for i in `seq 1 ${save_day}`;do date -d -${i}days "+%F";done))
#开始
/usr/bin/echo >> ${log_dir}
/usr/bin/echo "time:$(date +%F-%H-%M-%S) info:开始全备份" >> ${log_dir}
#检查
${my_sql} $* -e "show databases;" &> /tmp/info_error.txt
if [[ $? -ne 0 ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) info:登陆命令错误" >> ${log_dir}
/usr/bin/cat /tmp/info_error.txt #如果错误则显示错误信息
exit 1
fi
#移动到目录
cd ${bak_dir}
bak_time=`date +%F-%H-%M`
bak_timetwo=`date +%F`
#备份
${bak_sql} $* --all-databases --flush-privileges --single-transaction --flush-logs --triggers --routines --events --hex-blob > mybak-all-${bak_time}.sql
if [[ $? -ne 0 ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) error:备份失败"
/usr/bin/echo "time:$(date +%F-%H-%M-%S) error:备份失败" >> ${log_dir}
/usr/bin/cat /tmp/bak_error.txt #如果错误则显示错误信息
exit 1
else
bin_dian=`tail -n 1 ${binlog_dir}/mysql-bin.index`
echo "${bin_dian}" > ${bak_time}-binlog.txt
fi
#压缩
if [[ -f mybak-all-${bak_time}.tar.gz ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) info:压缩包mybak-section-${bak_time}.tar.gz 已存在" >> ${log_dir}
/usr/bin/rm -irf mybak-all-${bak_time}.tar.gz ${bak_sql}-binlog.txt
fi
/usr/bin/tar -cf mybak-all-${bak_time}.tar.gz mybak-all-${bak_time}.sql ${bak_time}-binlog.txt
if [[ $? -ne 0 ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) error:压缩失败" >> ${log_dir}
exit 1
fi
#删除sql文件
/usr/bin/rm -irf mybak-all-${bak_time}.sql ${bak_time}-binlog.txt
if [[ $? -ne 0 ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) info:删除sql文件失败" >> ${log_dir}
exit 1
fi
#整理压缩的日志文件
for i in `ls | grep .tar.gz$`
do
echo $i | grep "^mybak-all.*tar.gz$" &> /dev/null
if [[ $? -eq 0 ]];then
a=`echo ${i%%.tar.gz}`
b=`echo ${a:(-16)}`
c=`echo ${b%-*}`
d=`echo ${c%-*}`
#看是否在数组中,不在则删除
echo ${save_day_zu[*]} |grep -w $d &> /dev/null
if [[ $? -ne 0 ]];then
[[ "$d" != "$bak_timetwo" ]] && rm -rf $i
fi
else
#不是当月的,其他类型压缩包,跳过
continue
fi
done
#结束
last_time=`date +%F-%H-%M-%S`
/usr/bin/echo "begin_time:${begin_time} last_time:${last_time}" >> ${log_dir}
/usr/bin/echo "time:$(date +%F-%H-%M-%S) info:全备份完成" >> ${log_dir}
/usr/bin/echo >> ${log_dir}
增量脚本
mybak-section.sh
#!/bin/bash
#使用:./xx.sh -uroot -p'123456',将第一次增量备份后的binlog文件名写到/tmp/binlog-section中,若都没有,自动填写mysql-bin.000001
#过程:增量先刷新binlog日志,再查询/tmp/binlog-section中记录的上一次备份中最新的binlog日志的值
# cp中间的binlog日志,并进行压缩。再将备份中最新的binlog日志写入。
#恢复:先进行全量恢复,再根据全量备份附带的time-binlog.txt中的记录逐个恢复。当前最新的Binlog日志要去掉有问题的语句,例如drop等。
#提示:最多每分钟执行一次,否则会覆盖同分钟内的文件,可以修改脚本来改善
# 出现问题会退出,可以到指定的日志目录查看日志输出
# 同年的tar包超过指定天数的会删除掉
#[变量]
begin_time=`date +%F-%H-%M-%S`
my_sql="/usr/local/mysql/bin/mysql"
bak_sql="/usr/local/mysql/bin/mysqldump"
binlog_dir=/usr/local/mysql/data
binlog_index=${binlog_dir}/mysql-bin.index
bak_dir=/ops/bak
log_dir=/ops/log/mybak-section.log
#保存的天数,4周就是28天
save_day=7
#[自动变量]
#当前年
date_nian=`date +%Y-`
#所有天数的数组
save_day_zu=($(for i in `seq 1 ${save_day}`;do date -d -${i}days "+%F";done))
#开始
/usr/bin/echo >> ${log_dir}
/usr/bin/echo "time:$(date +%F-%H-%M-%S) info:开始增量备份" >> ${log_dir}
#检查
${my_sql} $* -e "show databases;" &> /tmp/info_error.txt
if [[ $? -ne 0 ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) info:登陆命令错误" >> ${log_dir}
/usr/bin/cat /tmp/info_error.txt #如果错误则显示错误信息
exit 1
fi
#移动到目录
cd ${bak_dir}
bak_time=`date +%F-%H-%M`
bak_timetwo=`date +%F`
#刷新
${my_sql} $* -e "flush logs"
if [[ $? -ne 0 ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) error:刷新binlog失败" >> ${log_dir}
exit 1
fi
#获取开头和结尾binlog名字
last_bin=`cat /tmp/binlog-section`
next_bin=`tail -n 1 ${binlog_dir}/mysql-bin.index`
echo ${last_bin} |grep 'mysql-bin' &> /dev/null
if [[ $? -ne 0 ]];then
echo "mysql-bin.000001" > /tmp/binlog-section #不存在则默认第一个
last_bin=`cat /tmp/binlog-section`
fi
#截取需要备份的binlog行数
a=`/usr/bin/sort ${binlog_dir}/mysql-bin.index | uniq | grep -n ${last_bin} | awk -F':' '{print $1}'`
b=`/usr/bin/sort ${binlog_dir}/mysql-bin.index | uniq | grep -n ${next_bin} | awk -F':' '{print $1}'`
let b--
#输出最新节点
/usr/bin/echo "${next_bin}" > /tmp/binlog-section
#创建文件
rm -rf mybak-section-${bak_time}
/usr/bin/mkdir mybak-section-${bak_time}
for i in `sed -n "${a},${b}p" ${binlog_dir}/mysql-bin.index | awk -F'./' '{print $2}'`
do
if [[ ! -f ${binlog_dir}/${i} ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) error:binlog文件${i} 不存在" >> ${log_dir}
exit 1
fi
cp -rf ${binlog_dir}/${i} mybak-section-${bak_time}/
if [[ ! -f mybak-section-${bak_time}/${i} ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) error:binlog文件${i} 备份失败" >> ${log_dir}
exit 1
fi
done
#压缩
if [[ -f mybak-section-${bak_time}.tar.gz ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) info:压缩包mybak-section-${bak_time}.tar.gz 已存在" >> ${log_dir}
/usr/bin/rm -irf mybak-section-${bak_time}.tar.gz
fi
/usr/bin/tar -cf mybak-section-${bak_time}.tar.gz mybak-section-${bak_time}
if [[ $? -ne 0 ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) error:压缩失败" >> ${log_dir}
exit 1
fi
#删除binlog文件夹
/usr/bin/rm -irf mybak-section-${bak_time}
if [[ $? -ne 0 ]];then
/usr/bin/echo "time:$(date +%F-%H-%M-%S) info:删除sql文件失败" >> ${log_dir}
exit 1
fi
#整理压缩的日志文件
for i in `ls | grep "^mybak-section.*tar.gz$"`
do
echo $i | grep ${date_nian} &> /dev/null
if [[ $? -eq 0 ]];then
a=`echo ${i%%.tar.gz}`
b=`echo ${a:(-16)}` #当前日志年月日
c=`echo ${b%-*}`
d=`echo ${c%-*}`
#看是否在数组中,不在其中,并且不是当前时间,则删除。
echo ${save_day_zu[*]} |grep -w $d &> /dev/null
if [[ $? -ne 0 ]];then
[[ "$d" != "$bak_timetwo" ]] && rm -rf $i
fi
else
#不是当月的,其他类型压缩包,跳过
continue
fi
done
#结束
last_time=`date +%F-%H-%M-%S`
/usr/bin/echo "begin_time:${begin_time} last_time:${last_time}" >> ${log_dir}
/usr/bin/echo "time:$(date +%F-%H-%M-%S) info:增量备份完成" >> ${log_dir}
/usr/bin/echo >> ${log_dir}
二.备份策略
周日晚3点进行全量备份 周一到周六每天进行增量备份, 全量保存4周 增量保存近一周的每天数据
crontab -e 添加计划任务
1 3 * * 6 /bin/bash /root/bin/mybak-all.sh -uroot -p'123456'
1 2 * * * /bin/bash /root/bin/mybak-section.sh -uroot -p'123456'
三.容灾测试
准备
按照第一步,环境需求中,将mysql开启binlog并重启,也可以设置全局变量,不用重启
vim /root/bin/mybak-all.sh,将全量脚本复制到其中,并 chmod+ x /root/bin/mybak-all.sh 添加执行权限。
vim /root/bin/mybak-section.sh,将增量脚本复制到其中,并 chmod +x /root/bin/mybak-section.sh 添加执行权限。
创建测试数据库
create database test;
切换数据库
use test;
创建测试表
create table s1(id int AUTO_INCREMENT PRIMARY KEY,name char(20),age int);
用 vim /root/bin/testsql.sh 命令创建一个数据插入脚本,随机插入一千条数据用于测试。
#!/bin/bash
ku=one
biao=s1
zi() {
zu=(q w e r t y u i o p a s d f g h j k l z x c v b n m)
for i in `seq 1 5`
do
a=`echo $[RANDOM%24]`
echo -n ${zu[a]}
done
}
for i in `seq 1 1000`
do
b=`zi`
mysql -uroot -p'123456' -e "use test;insert into s1(name,age) values('${b}',${i});"
done
执行脚本
bash /root/bin/testsql.sh
用如下命令检查表的条目数是否是1000条
mysql -uroot -p'123456' -e "use test;select count(*) from s1;"
测试
第一次:
更改时间
date -s 2016-04-04
执行全量脚本
bash /root/bin/mybak-all.sh -uroot -p'123456'
再执行增量脚本
bash /root/bin/mybak-section.sh -uroot -p'123456'
查看是否有2个tar包。可以看到tar包
ls /ops/bak
mybak-all-2016-04-04-00-00.tar.gz
mybak-section-2016-04-04-00-00.tar.gz
执行脚本插入1000条数据
bash /root/bin/testsql.sh
用如下命令检查表的条目数是否是2000条
mysql -uroot -p'123456' -e "use test;select count(*) from s1;"
第二次:
更改时间
date -s 2016-04-05
执行全量脚本
bash /root/bin/mybak-all.sh -uroot -p'123456'
再执行增量脚本
bash /root/bin/mybak-section.sh -uroot -p'123456'
用查看是否有4个tar包。可以看到如下
ls /ops/bak
mybak-all-2016-04-04-00-00.tar.gz / mybak-section-2016-04-04-00-00.tar.gz
mybak-all-2016-04-05-00-00.tar.gz / mybak-section-2016-04-05-00-00.tar.gz
执行脚本插入1000条数据
bash /root/bin/testsql.sh
用如下命令检查表的条目数是否是3000条
mysql -uroot -p'123456' -e "use test;select count(*) from s1;"
第三次
更改时间
date -s 2016-04-06
执行全量脚本
bash /root/bin/mybak-all.sh -uroot -p'123456'
再执行增量脚本
bash /root/bin/mybak-section.sh -uroot -p'123456'
用查看是否有4个tar包。可以看到如下
ls /ops/bak
mybak-all-2016-04-04-00-00.tar.gz / mybak-section-2016-04-04-00-00.tar.gz
mybak-all-2016-04-05-00-00.tar.gz / mybak-section-2016-04-05-00-00.tar.gz
mybak-all-2016-04-06-00-00.tar.gz / mybak-section-2016-04-06-00-00.tar.gz
执行脚本插入1000条数据
bash /root/bin/testsql.sh
用如下命令检查表的条目数是否是4000条
mysql -uroot -p'123456' -e "use test;select count(*) from s1;"
误删除
删除:
登陆mysql服务器
mysql -uroot -p'123456'
删除test数据库,用来模拟误操作
drop database test;
恢复第一步:准备
移动到备份所在的目录
cd /ops/bak
解开最近时间点的全量备份包,最近时间是2016-04-06
tar -xf mybak-all-2016-04-06-00-00.tar.gz
解压后可以看到 mybak-all-2016-04-06-00-00.sql 和 2016-04-06-00-00-binlog.txt
其中mybak-all-2016-04-06-00-00.sql 是sql语句,用于恢复某个时间点的全部内容,如果只误操作某个库,可以单独恢复某个库。2016-04-06-00-00-binlog.txt中记录了全备过程中刷新的Binlog文件名。
解压增量备份的文件夹 ,因为这2个脚本是先后执行的,所以不需要解压6号前的,只解压6号及以后的。
tar -xf mybak-section-2016-04-06-00-00.tar.gz
解压后可以看到 mysql-bin.000008 和 mysql-bin.000009 2个binlog日志
恢复第二步:全备份恢复
导入数据进去
mysql -uroot -p'123456' < mybak-all-2016-04-06-00-00.sql
用如下命令检查表的条目数是否是3000条,6号备份完成后,才添加的最后1000条。
mysql -uroot -p'123456' -e "use test;select count(*) from s1;"
恢复第三步:增量恢复
查看应该从哪个binlog文件恢复。当前获得 ./mysql-bin.000014
cat 2016-04-06-00-00-binlog.txt
将 mybak-section-2016-04-06-00-00 文件夹中的 mysql-bin.000014 恢复,因为操作有问题的binlog日志在15中,14日志可以直接用于恢复
mysqlbinlog mybak-section-2016-04-06-00-00/ysql-bin.000014 | mysql -uroot -p'123456'
检查表的条目数是否是3000条,因为在写入3000条后,mysqldmp全备刷新了一下binlog,这个最新的是14,而还没有写入任何东西时便执行增量备份了,刷新了一下binlog,最新的是15,这时候才导入了最新的1000条。如果是持续的在写入,恢复14后会有数据变化。
mysql -uroot -p'123456' -e "use test;select count(*) from s1;"
在mysql数据目录/ops/server/mysql/data/下找到mysql-bin.000015
找出binlog日志中有删除数据库语句的行数,当前为728
mysql -uroot -p'123456' -e "show binlog events in 'mysql-bin.000015'\G" | grep -n "drop database "

找出728前后几行的内容,可以看到出现问题的pos点为5519,恢复到5519之前的数据即可。
mysql -uroot -p'123456' -e "show binlog events in 'mysql-bin.000015'\G" | sed -n '715,730p'
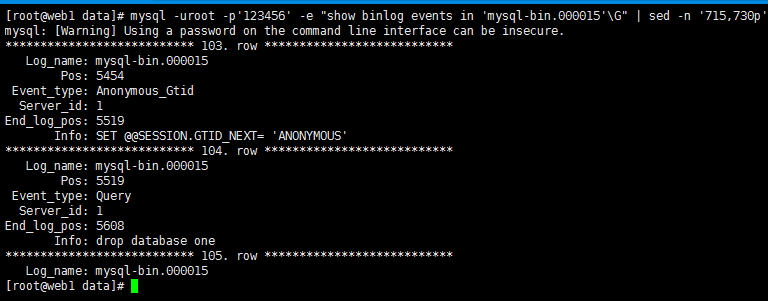
进行恢复,stop-position是指定恢复截止的pos点。
mysqlbinlog --stop-position=5519 mysql-bin.000015 | mysql -uroot -p'123456'
检查表的条目数是否是4000条
mysql -uroot -p'123456' -e "use test;select count(*) from s1;"
mysqldump备份容灾脚本的更多相关文章
- centos6.5环境通过shell脚本备份php的web及mysql数据库并做远程备份容灾
centos6.5环境通过shell脚本备份php的web及mysql数据库并做远程备份容灾 系统:centos6.5 1.创建脚本目录 mkdir -p /usr/local/sh/ 创建备份web ...
- Hbase数据备份&&容灾方案
Hbase数据备份&&容灾方案 标签(空格分隔): Hbase 一.Distcp 在使用distcp命令copy hdfs文件的方式实现备份时,需要禁用备份表确保copy时该表没有数据 ...
- 数据备份与恢复 半持久化 全持久化 fork aof rdb Backing up Disaster recovery 备份 容灾
Redis数据备份与恢复 - 流年晕开时光 - 博客园 https://www.cnblogs.com/deny/p/11531355.html Redis数据备份与恢复 Redis所有数据都是保存在 ...
- 删库到跑路?还得看这篇Redis数据库持久化与企业容灾备份恢复实战指南
本章目录 0x00 数据持久化 1.RDB 方式 2.AOF 方式 如何抉择 RDB OR AOF? 0x01 备份容灾 一.备份 1.手动备份redis数据库 2.迁移Redis指定db-数据库 3 ...
- mysql容灾备份脚本
一,环境需求 **安装前准备 操作系统环境:Centos 7.2 [root@localhost soft]# rpm -qa | grep mariadb [root@localhost soft] ...
- Redis全方位详解--磁盘持久化和容灾备份
序言 在上一篇博客中,博客介绍了redis的数据类型使用场景和redis分布式锁的正确姿势.我们知道一旦Redis重启,存在redis里面的数据就会全部丢失.所以这篇博客中向大家介绍Redis的磁盘持 ...
- 13.在项目中部署redis企业级数据备份方案以及各种踩坑的数据恢复容灾演练
到这里为止,其实还是停留在简单学习知识的程度,学会了redis的持久化的原理和操作,但是在企业中,持久化到底是怎么去用得呢? 企业级的数据备份和各种灾难下的数据恢复,是怎么做得呢? 1.企业级的持久化 ...
- Mysqldump备份说明及数据库备份脚本分享-运维笔记
MySQLdump是MySQL自带的导出数据工具,即mysql数据库中备份工具,用于将MySQL服务器中的数据库以标准的sql语言的方式导出,并保存到文件中.Mysqldump是一个客户端逻辑备份的工 ...
- (4.4)mysql备份还原——备份存储容灾基础知识
存储知识 1.为什么需要存储,存储一般解决哪些问题? 容量.速度.易于管理.安全(容灾与备份).可扩展性 2.存储发展历史 [2.1]大型机 [2.2]c/s结构(客户端->服务器) [2.3] ...
随机推荐
- js 函数和函数的参数
/* * 函数 function * - 函数也是一个对象 * - 函数中可以封装一些功能(代码),在需要时可以执行这些功能(代码) * - 函数中可以保存一些代码在需要的时候 ...
- Go语言核心36讲(Go语言实战与应用七)--学习笔记
29 | 原子操作(上) 我们在前两篇文章中讨论了互斥锁.读写锁以及基于它们的条件变量,先来总结一下. 互斥锁是一个很有用的同步工具,它可以保证每一时刻进入临界区的 goroutine 只有一个.读写 ...
- Windows11下的快捷键(win10通用,部分win11独有的不通用)
给大家介绍一下win11下我常用的几个快捷键,在微软官方的文档里面都可以查到,官网链接 https://support.microsoft.com/zh-cn/windows/windows-%E7% ...
- [年薪60W分水岭]基于Netty手写Apache Dubbo(带注册中心和注解)
阅读这篇文章之前,建议先阅读和这篇文章关联的内容. 1. 详细剖析分布式微服务架构下网络通信的底层实现原理(图解) 2. (年薪60W的技巧)工作了5年,你真的理解Netty以及为什么要用吗?(深度干 ...
- python-内置函数(搭配lambda使用)
目录 常用的内置函数 需要注意的知识点: enumerate()函数 map()函数 zip()函数 filter()函数 reduce()函数 sum()函数 max()/ min()函数 sort ...
- Dapr-Actor构建块
前言: 前篇-绑定 文章对Dapr的绑定构建块进行了解,本篇继续对 Actor 构建块进行了解学习. 一.Actor简介: Actors 为最低级别的"计算单元". 换句话说,您将 ...
- Java-ASM框架学习-从零构建类的字节码
Tips: ASM使用访问者模式,学会访问者模式再看ASM更加清晰 什么是ASM ASM是一个操作Java字节码的类库 学习这个类库之前,希望大家对Java 基本IO和字节码有一定的了解. 高版本的A ...
- Codeforces Round #717 (Div.2) 题解
我 AK 的第二场(?)的 Div.2,还捡了个 rk4(虽然我 div2 only 的最高记录是 rk2)祭之( A 这题我竟然 WA 了两发,丢人( 直接贪心,对于 \(i=1,2,\cdots, ...
- 认识Influxdb时序数据库及Influxdb基础命令操作
认识Influxdb时序数据库及Influxdb基础命令操作 一.什么是Influxdb,什么又是时序数据库 Influxdb是一个用于存储时间序列,事件和指标的开源数据库,由Go语言编写而成,无需外 ...
- python包之drmaa:集群任务管理
目录 1. drmaa简介 2. 安装和配置 3. 示例 3.1 开始和终止会话 3.2 运行工作 3.3 等待工作 3.4 控制工作 3.5 查询工作状态 4. 应用 4.1 写一个简单应用 4.2 ...