【Hadoop代码笔记】Hadoop作业提交之Job初始化
一、概要描述
在上一篇博文中主要描述了JobTracker和其几个服务(或功能)模块的接收到提交的job后的一些处理。其中很重要的一部分就作业的初始化。因为代码片段图的表达问题,本应该在上篇描述的内容,分开在本篇描述。
二、 流程描述
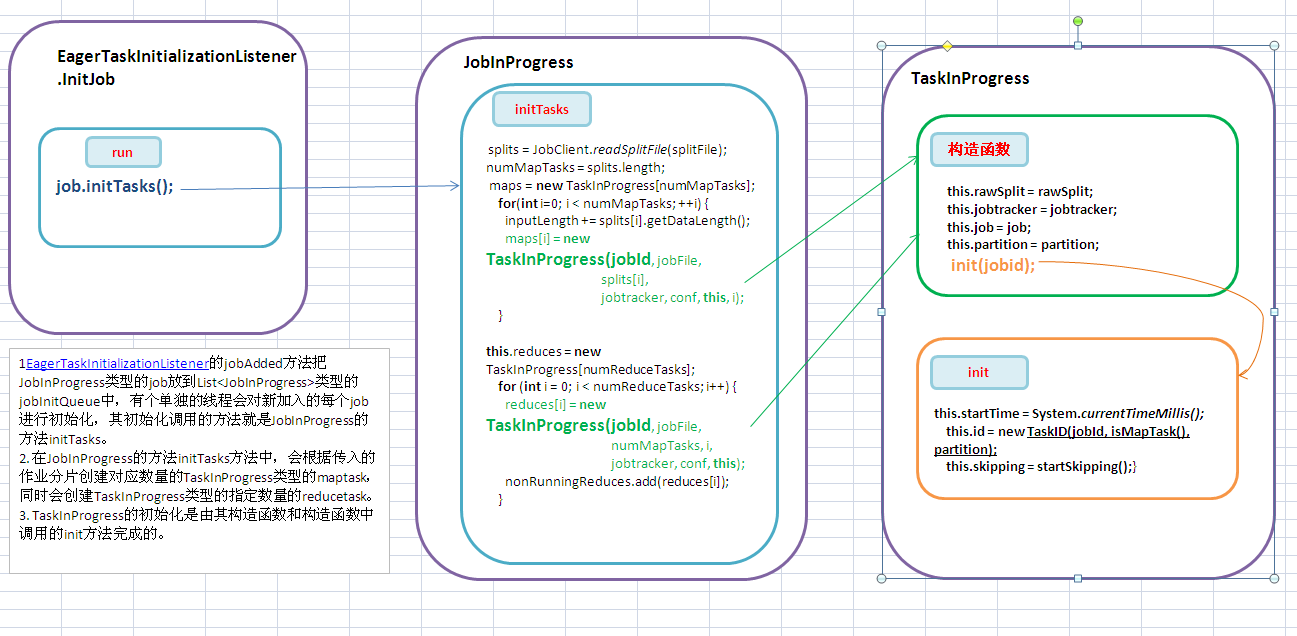
1. 代码也接上文的最后一个方法 EagerTaskInitializationListener的jobAdded方法把JobInProgress类型的job放到List<JobInProgress>类型的 jobInitQueue中,有个单独的线程会对新加入的每个job进行初始化,其初始化调用的方法就是JobInProgress的方法initTasks。
2. 在JobInProgress的方法initTasks方法中,会根据传入的作业分片创建对应数量的TaskInProgress类型的maptask,同时会创建TaskInProgress类型的指定数量的reducetask。
3. TaskInProgress的初始化是由其构造函数和构造函数中调用的init方法完成的。
三、代码详细
1. EagerTaskInitializationListener的内部InitJob线程的run方法。调用JobInProgress的初始化方法。
static class InitJob implements Runnable {
private JobInProgress job;
public InitJob(JobInProgress job) {
this.job = job;
}
public void run()
{
job.initTasks();
}
}
2. JobInProgress 类的initTasks方法。
主要流程:
1)根据读入的split确定map的数量,每个split一个map
2)如果Task数大于该jobTracker支持的最大task数,则抛出异常。
3)根据split的数量初始化maps
4)如果没有split,表示job已经成功结束。
5) 根据指定的reduce数量numReduceTasks创建reduce task
6)计算并且最少剩下多少map task ,才可以开始Reduce task。默认是总的map task的5%,即大部分Map task完成后,就可以开始reduce task了。
//1) 根据读入的split确定map的数量,每个split一个map
String jobFile = profile.getJobFile();
Path sysDir = new Path(this.jobtracker.getSystemDir());
FileSystem fs = sysDir.getFileSystem(conf);
DataInputStream splitFile =
fs.open(new Path(conf.get("mapred.job.split.file")));
JobClient.RawSplit[] splits;
splits = JobClient.readSplitFile(splitFile);
numMapTasks = splits.length; //2)如果Task数大于该jobTracker支持的最大task数,则抛出异常。
int maxTasks = jobtracker.getMaxTasksPerJob();
if (maxTasks > 0 && numMapTasks + numReduceTasks > maxTasks) {
throw new IOException(
"The number of tasks for this job " +
(numMapTasks + numReduceTasks) +
" exceeds the configured limit " + maxTasks);
} //3)根据split的数量初始化maps
maps = new TaskInProgress[numMapTasks];
for(int i=0; i < numMapTasks; ++i) {
inputLength += splits[i].getDataLength();
maps[i] = new TaskInProgress(jobId, jobFile,
splits[i],
jobtracker, conf, this, i);
}
LOG.info("Input size for job "+ jobId + " = " + inputLength);
if (numMapTasks > 0) {
LOG.info("Split info for job:" + jobId + " with " +
splits.length + " splits:");
nonRunningMapCache = createCache(splits, maxLevel);
} this.launchTime = System.currentTimeMillis(); //4)如果没有split,表示job已经成功结束。 if (numMapTasks == 0) {
//设定作业的完成时间避免下次还会判断。
this.finishTime = this.launchTime;
status.setSetupProgress(1.0f);
status.setMapProgress(1.0f);
status.setReduceProgress(1.0f);
status.setCleanupProgress(1.0f);
status.setRunState(JobStatus.SUCCEEDED);
tasksInited.set(true);
JobHistory.JobInfo.logInited(profile.getJobID(),
this.launchTime, 0, 0);
JobHistory.JobInfo.logFinished(profile.getJobID(),
this.finishTime, 0, 0, 0, 0,
getCounters());
return;
} //5) 根据指定的reduce数量numReduceTasks创建reduce task
this.reduces = new TaskInProgress[numReduceTasks];
for (int i = 0; i < numReduceTasks; i++) {
reduces[i] = new TaskInProgress(jobId, jobFile,
numMapTasks, i,
jobtracker, conf, this);
nonRunningReduces.add(reduces[i]);
} // 6)计算最少剩下多少map task ,才可以开始Reduce task。默认是总的map task的5%,即大部分Map task完成后,就可以开始reduce task了。
completedMapsForReduceSlowstart =
(int)Math.ceil(
(conf.getFloat("mapred.reduce.slowstart.completed.maps",
DEFAULT_COMPLETED_MAPS_PERCENT_FOR_REDUCE_SLOWSTART) *
numMapTasks)); tasksInited.set(true);
}
3. TaskInProgress的构造函数
有构造MapTask的构造函数和构造ReduceTask的构造函数。分别是如下。其主要区别在于构造mapTask是要传入输入分片信息的RawSplit,而Reduce Task则不需要。两个构造函数都要调用init方法,进行其他的初始化。
public TaskInProgress(JobID jobid, String jobFile,
RawSplit rawSplit,
JobTracker jobtracker, JobConf conf,
JobInProgress job, int partition) {
this.jobFile = jobFile;
this.rawSplit = rawSplit;
this.jobtracker = jobtracker;
this.job = job;
this.conf = conf;
this.partition = partition;
this.maxSkipRecords = SkipBadRecords.getMapperMaxSkipRecords(conf);
setMaxTaskAttempts();
init(jobid);
}
public TaskInProgress(JobID jobid, String jobFile,
int numMaps,
int partition, JobTracker jobtracker, JobConf conf,
JobInProgress job) {
this.jobFile = jobFile;
this.numMaps = numMaps;
this.partition = partition;
this.jobtracker = jobtracker;
this.job = job;
this.conf = conf;
this.maxSkipRecords = SkipBadRecords.getReducerMaxSkipGroups(conf);
setMaxTaskAttempts();
init(jobid);
}
4. TaskInProgress的init方法。初始化写map和reduce类型task都需要的初始化信息。
void init(JobID jobId) {
this.startTime = System.currentTimeMillis();
this.id = new TaskID(jobId, isMapTask(), partition);
this.skipping = startSkipping();
}
完。
为了转载内容的一致性、可追溯性和保证及时更新纠错,转载时请注明来自:http://www.cnblogs.com/douba/p/hadoop_mapreduce_job_init.html。谢谢!
【Hadoop代码笔记】Hadoop作业提交之Job初始化的更多相关文章
- 【hadoop代码笔记】hadoop作业提交之汇总
一.概述 在本篇博文中,试图通过代码了解hadoop job执行的整个流程.即用户提交的mapreduce的jar文件.输入提交到hadoop的集群,并在集群中运行.重点在代码的角度描述整个流程,有些 ...
- 【hadoop代码笔记】Mapreduce shuffle过程之Map输出过程
一.概要描述 shuffle是MapReduce的一个核心过程,因此没有在前面的MapReduce作业提交的过程中描述,而是单独拿出来比较详细的描述. 根据官方的流程图示如下: 本篇文章中只是想尝试从 ...
- 【Hadoop代码笔记】目录
整理09年时候做的Hadoop的代码笔记. 开始. [Hadoop代码笔记]Hadoop作业提交之客户端作业提交 [Hadoop代码笔记]通过JobClient对Jobtracker的调用看详细了解H ...
- 【Hadoop代码笔记】Hadoop作业提交之客户端作业提交
1. 概要描述仅仅描述向Hadoop提交作业的第一步,即调用Jobclient的submitJob方法,向Hadoop提交作业. 2. 详细描述Jobclient使用内置的JobS ...
- 【Hadoop代码笔记】Hadoop作业提交之TaskTracker获取Task
一.概要描述 在上上一篇博文和上一篇博文中分别描述了jobTracker和其服务(功能)模块初始化完成后,接收JobClient提交的作业,并进行初始化.本文着重描述,JobTracker如何选择作业 ...
- 【hadoop代码笔记】Hadoop作业提交中EagerTaskInitializationListener的作用
在整理FairScheduler实现的task调度逻辑时,注意到EagerTaskInitializationListener类.差不多应该是job提交相关的逻辑代码中最简单清楚的一个了. todo: ...
- 【Hadoop代码笔记】Hadoop作业提交之JobTracker等相关功能模块初始化
一.概要描述 本文重点描述在JobTracker一端接收作业.调度作业等几个模块的初始化工作.想过模块的介绍会在其他文章中比较详细的描述.受理作业提交在下一篇文章中会进行描述. 为了表达的尽可能清晰一 ...
- 【Hadoop代码笔记】通过JobClient对Jobtracker的调用详细了解Hadoop RPC
Hadoop的各个服务间,客户端和服务间的交互采用RPC方式.关于这种机制介绍的资源很多,也不难理解,这里不做背景介绍.只是尝试从Jobclient向JobTracker提交作业这个最简单的客户端服务 ...
- Hadoop学习笔记——Hadoop经常使用命令
Hadoop下有一些经常使用的命令,通过这些命令能够非常方便操作Hadoop上的文件. 1.查看指定文件夹下的内容 语法: hadoop fs -ls 文件文件夹 2.打开某个已存在的文件 语法: h ...
- 【Hadoop代码笔记】Hadoop作业提交之JobTracker接收作业提交
一.概要描述 在上一篇博文中主要描述了JobTracker接收作业的几个服务(或功能)模块的初始化过程.本节将介绍这些服务(或功能)是如何接收到提交的job.本来作业的初始化也可以在本节内描述,但是涉 ...
随机推荐
- Android中的sp与wp
一.相关code文件 二.code具体分析 lightrefebase: refbase: sp: wp: flag: 三.使用注意事项 不能在把目标对象赋给一个长久存在的sp对象之前赋给一个短生命周 ...
- iPhone(iOS设备) 无法更新或恢复时, 如何进入恢复模式
在更新或恢复 iPhone 时,如果遇到以下所列问题之一.可能就要将设备置于恢复模式,并尝试重新恢复设备. 设备不断地重新启动,但从未显示主屏幕. 无法完成更新或恢复,且 iTunes 不再能识别设 ...
- [原]HDU-1598-find the most comfortable road(暴力枚举+Kruskal最小生成树)
题意: 给出一个图,然后Q个询问,每次询问从一个节点到另一个节点,联通图中的“最大边和最小边之差”的最小值,但如果节点之间不连通,则输出-1. 思路:由于询问Q < 11,m < 1000 ...
- What is Entity Framework?
1.什么是EntityFramework? http://www.entityframeworktutorial.net/what-is-entityframework.aspx Writing an ...
- eclipse有生成不带参数的构造方法的快捷键吗
你打上类名的2个字母,然后”alt“ +“/” 基本上选第一个就行了
- aop郁闷错误
很郁闷的错误,终于解决了: <aop:config> <aop:aspect ref="log"> <aop:pointcut id=" ...
- System.Linq.Dynamic 和Nhibernate
var session = NHibernateSessionManager.Instance.GetSession(); "); var staffList = session.Query ...
- bzoj3668: [Noi2014]起床困难综合症
从高位到低位枚举期望的应该是ans最高位尽量取一.如果该数最高位为o的话能够取得1直接更新ans否则判断该位取1是否会爆m不会的话就加上. #include<cstdio> #includ ...
- css各浏览器的兼容性写法
各浏览器下的兼容性写法 老版Chrome -webkit-xxx FF -moz-xxx IE9 -ms-xxx opera ...
- 【转】发布的QT程序无法显示图标和图片的问题
在windows下编译好的QT程序在其他没有安装QT的机器上会出现图标和图片无法正常显示的问题. 这时我们可以通过以下方式来解决: 在release文件夹里创建plugins文件夹,并将QT安装目录下 ...