SQL SERVER分区表
简介
分区表是在SQL SERVER2005之后的版本引入的特性。这个特性允许把逻辑上的一个表在物理上分为很多部分。而对于SQL SERVER2005之前版本,所谓的分区表仅仅是分布式视图,也就是多个表做union操作.
分区表在逻辑上是一个表,而物理上是多个表.这意味着从用户的角度来看,分区表和普通表是一样的。这个概念可以简单如下图所示:
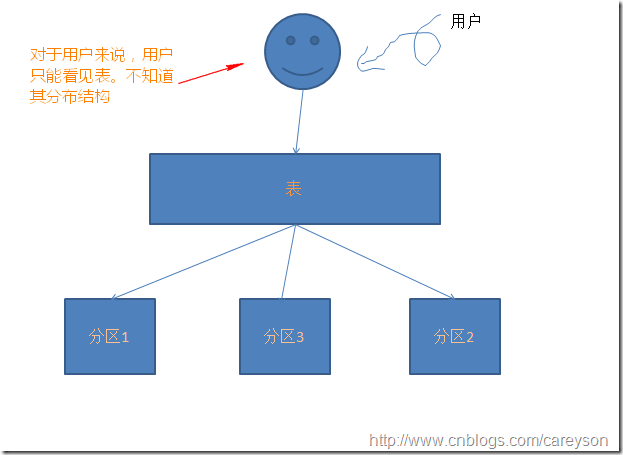
而对于SQL SERVER2005之前的版本,是没有分区这个概念的,所谓的分区仅仅是分布式视图:
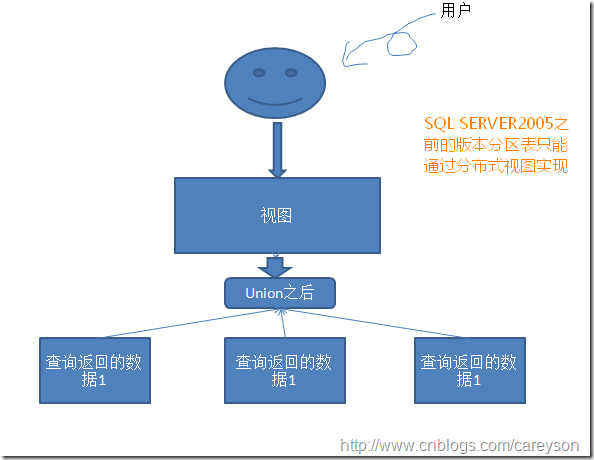
本篇文章所讲述的分区表指的是SQL SERVER2005之后引入的分区表特性.
为什么要对表进行分区
在回答标题的问题之前,需要说明的是,表分区这个特性只有在企业版或者开发版中才有,还有理解表分区的概念还需要理解SQL SERVER中文件和文件组的概念.
对表进行分区在多种场景下都需要被用到.通常来说,使用表分区最主要是用于:
- 存档,比如将销售记录中1年前的数据分到一个专门存档的服务器中
- 便于管理,比如把一个大表分成若干个小表,则备份和恢复的时候不再需要备份整个表,可以单独备份分区
- 提高可用性,当一个分区跪了以后,只有一个分区不可用,其它分区不受影响
- 提高性能,这个往往是大多数人分区的目的,把一个表分布到不同的硬盘或其他存储介质中,会大大提升查询的速度.
分区表的步骤
分区表的定义大体上分为三个步骤:
- 定义分区函数
- 定义分区构架
- 定义分区表
分区函数,分区构架和分区表的关系如下:
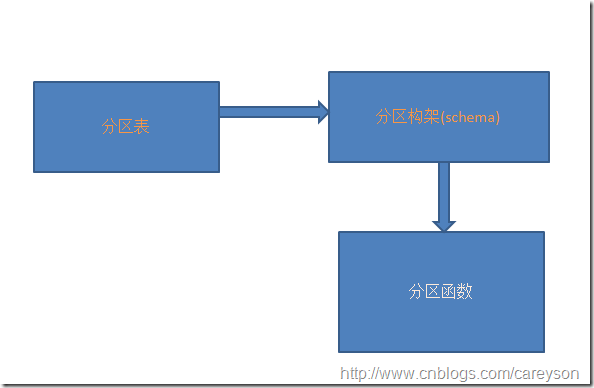
分区表依赖分区构架,而分区构架又依赖分区函数.值得注意的是,分区函数并不属于具体的分区构架和分区表,他们之间的关系仅仅是使用关系.
下面我们通过一个例子来看如何定义一个分区表:
假设我们需要定义的分区表结构如下:
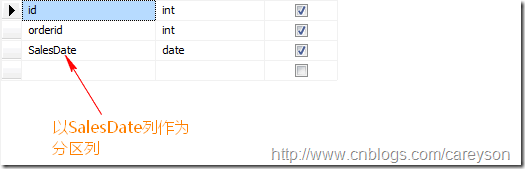
第一列为自增列,orderid为订单id列,SalesDate为订单日期列,也就是我们需要分区的依据.
下面我们按照上面所说的三个步骤来实现分区表.
定义分区函数
分区函数是用于判定数据行该属于哪个分区,通过分区函数中设置边界值来使得根据行中特定列的值来确定其分区,上面例子中,我们可以通过SalesDate的值来判定其不同的分区.假设我们想定义两个边界值(boundaryValue)进行分区,则会生成三个分区,这里我设置边界值分别为2004-01-01和2007-01-01,则前面例子中的表会根据这两个边界值分成三个区:
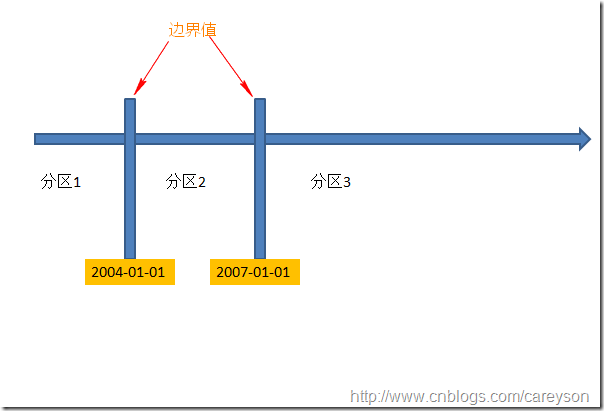
在MSDN中,定义分区函数的原型如下:
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type )
AS RANGE [ LEFT | RIGHT ]
FOR VALUES ( [ boundary_value [ ,...n ] ] )
[ ; ]
通过定义分区函数的原型,我们看出其中并没有具体涉及具体的表.因为分区函数并不和具体的表相绑定.上面原型中还可以看到Range left和right.这个参数是决定临界值本身应该归于“left”还是“right”:
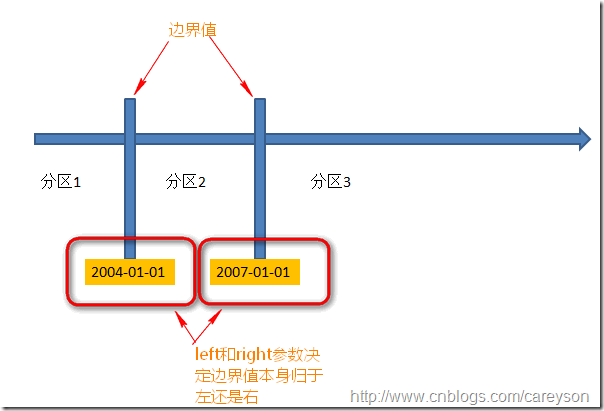
下面我们根据上面的参数定义分区函数:
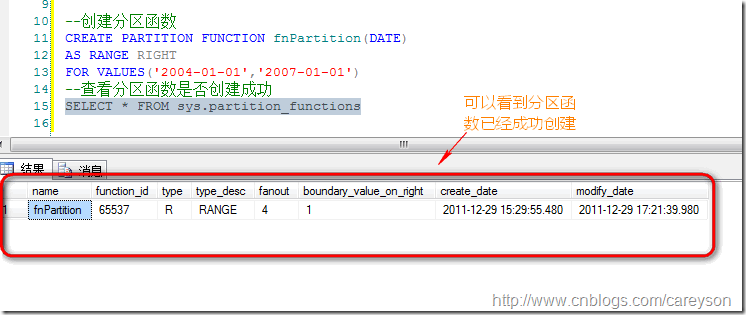
通过系统视图,可以看见这个分区函数已经创建成功
定义分区构架
定义完分区函数仅仅是知道了如何将列的值区分到了不同的分区。而每个分区的存储方式,则需要分区构架来定义.使用分区构架需要你对文件和文件组有点了解.
我们先来看MSDN的分区构架的原型:
CREATE PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )
[ ; ]
从原型来看,分区构架仅仅是依赖分区函数.分区构架中负责分配每个区属于哪个文件组,而分区函数是决定如何在逻辑上分区:
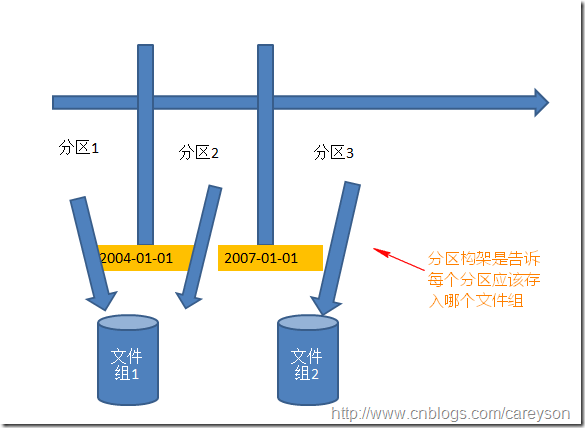
基于之前创建的分区函数,创建分区构架:
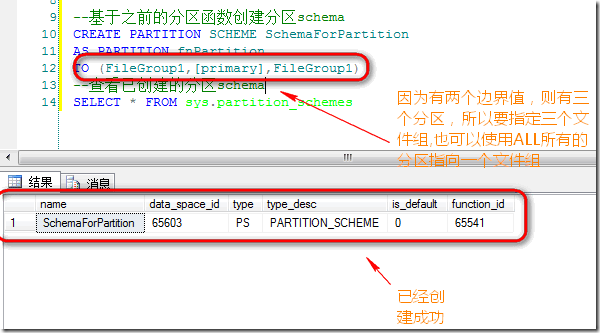
定义分区表
接下来就该创建分区表了.表在创建的时候就已经决定是否是分区表了。虽然在很多情况下都是你在发现已经表已经足够大的时候才想到要把表分区,但是分区表只能够在创建的时候指定为分区表。
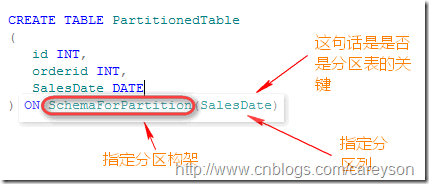
为刚建立的分区表PartitionedTable加入5万条测试数据,其中SalesDate随机生成,从2001年到2010年随机分布.加入数据后,我们通过如下语句来看结果:
select convert(varchar(50), ps.name) as partition_scheme,
p.partition_number,
convert(varchar(10), ds2.name) as filegroup,
convert(varchar(19), isnull(v.value, ''), 120) as range_boundary,
str(p.rows, 9) as rows
from sys.indexes i
join sys.partition_schemes ps on i.data_space_id = ps.data_space_id
join sys.destination_data_spaces dds
on ps.data_space_id = dds.partition_scheme_id
join sys.data_spaces ds2 on dds.data_space_id = ds2.data_space_id
join sys.partitions p on dds.destination_id = p.partition_number
and p.object_id = i.object_id and p.index_id = i.index_id
join sys.partition_functions pf on ps.function_id = pf.function_id
LEFT JOIN sys.Partition_Range_values v on pf.function_id = v.function_id
and v.boundary_id = p.partition_number - pf.boundary_value_on_right
WHERE i.object_id = object_id('PartitionedTable')
and i.index_id in (0, 1)
order by p.partition_number
可以看到我们分区的数据分布:
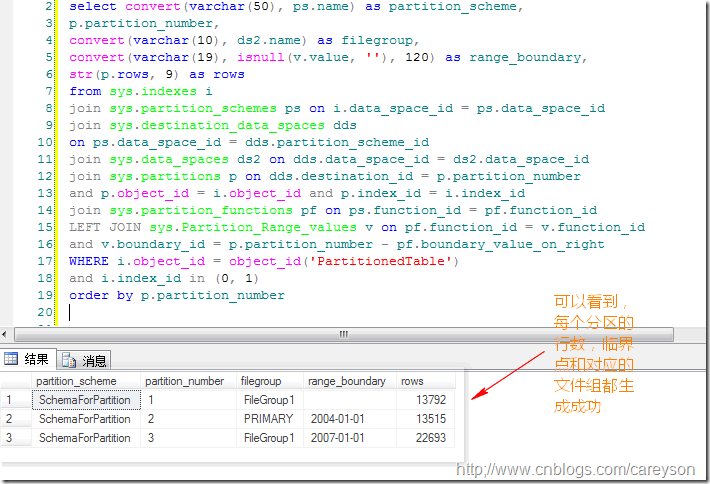
分区表的分割
分区表的分割。相当于新建一个分区,将原有的分区需要分割的内容插入新的分区,然后删除老的分区的内容,概念如下图:
假设我新加入一个分割点:2009-01-01,则概念如下:
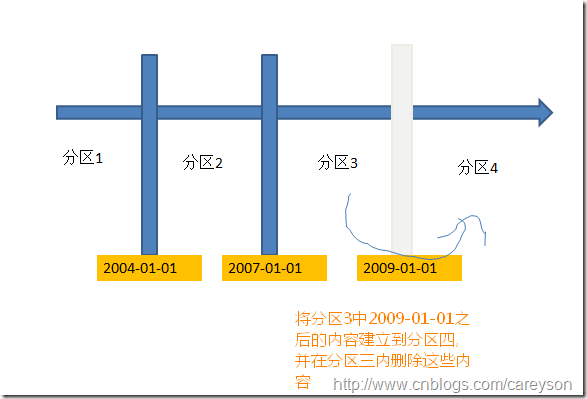
通过上图我们可以看出,如果分割时,被分割的分区3内有内容需要分割到分区4,则这些数据需要被复制到分区4,并删除分区3上对应数据。
这种操作非常非常消耗IO,并且在分割的过程中锁定分区三内的内容,造成分区三的内容不可用。不仅仅如此,这个操作生成的日志内容会是被转移数据的4倍!
所以我们如果不想因为这种操作给客户带来麻烦而被老板爆菊的话…最好还是把分割点建立在未来(也就是预先建立分割点),比如2012-01-01。则分区3内的内容不受任何影响。在以后2012的数据加入时,自动插入到分区4.
分割现有的分区需要两个步骤:
1.首先告诉SQL SERVER新建立的分区放到哪个文件组
2.建立新的分割点
可以通过如下语句来完成:
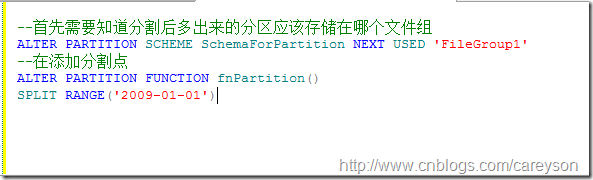
如果我们的分割构架在定义的时候已经指定了NEXT USED,则直接添加分割点即可。
通过文中前面查看分区的长语句..再来看:
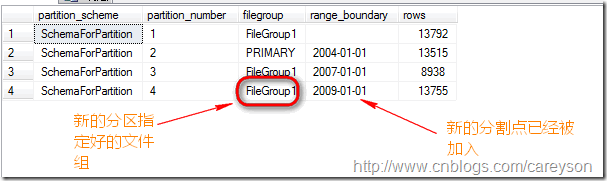
新的分区已经加入!
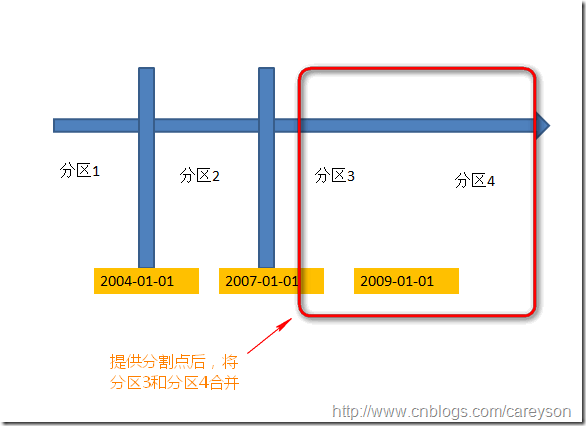
分区的合并
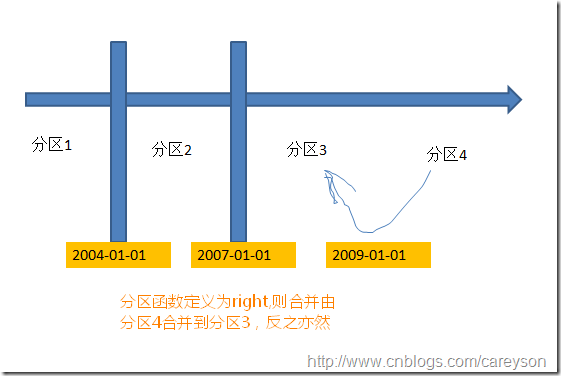
分区的合并可以看作分区分割的逆操作。分区的合并需要提供分割点,这个分割点必须在现有的分割表中已经存在,否则进行合并就会报错
假设我们需要根据2009-01-01来合并分区,概念如下:
只需要使用merge参数:
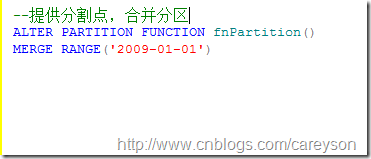
再来看分区信息:
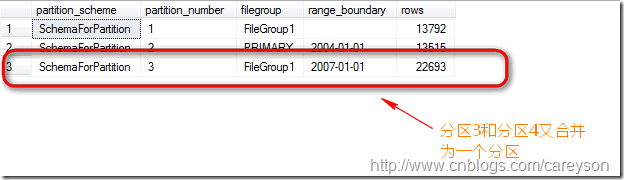
这里值得注意的是,假设分区3和分区4不再一个文件组,则合并后应该存在哪个文件组呢?换句话说,是由分区3合并到分区4还是由分区4合并到分区3?这个需要看我们的分区函数定义的是left还是right.如果定义的是left.则由左边的分区3合并到右边的分区4.反之,则由分区4合并到分区3:
总结
本文从讲解了SQL SERVER中分区表的使用方式。分区表是一个非常强大的功能。使用分区表相对传统的分区视图来说,对于减少DBA的管理工作来说,会更胜一筹!
SQL SERVER分区表的更多相关文章
- SQL Server ->> 分区表上创建唯一分区索引
今天在读<Oracle高级SQL编程>这本书的时候,在关于Oracle的全局索引的章节里面有一段讲到如果对一张分区表创建一条唯一索引,而索引本身也是分区的,那就必须把分区列也加入到索引列表 ...
- SQL Server分区表,能否按照多个列作为分区函数的分区依据(转载)
问: Hi, I have a table workcachedetail with 40 million rows which has 8 columns.We decided to partiti ...
- SQL Server 分区表
分区表可以提高查询效率 但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在不同的磁盘下由多个cpu进行处理.这样文件的大小随 ...
- SQL Server 分区表补充说明
分区教程参阅:http://database.9sssd.com/mssql/art/951 切换分区(归档):http://technet.microsoft.com/zh-cn/library/m ...
- SQL Server 分区表的创建方法与管理
背景知识: 分区表.可以把表中的数据按范围保存到不同的文件组中. 举个例子吧: 2014年以前的数据保存到文件组A 2014~2015的数据保存到文件组B 2015年以后的数据保存到文件组C 好处: ...
- SQL Server 分区表上建立ColumnStore Index 如何添加新分区方法与步骤
在生产环境中会遇到这样的场景,一个表随着时间的推移,越来越大,这个时候我们开始动手为这个表建立分区来改进查询性能. 但是表过大上百个G的时候,在数据仓库中,为了改进查询性能,我们可以添加在分区表的基础 ...
- Sql Server系列:分区表操作
1. 分区表简介 分区表在逻辑上是一个表,而物理上是多个表.从用户角度来看,分区表和普通表是一样的.使用分区表的主要目的是为改善大型表以及具有多个访问模式的表的可伸缩性和可管理性. 分区表是把数据按设 ...
- 玩转SQL Server复制回路の变更数据类型、未分区表转为分区表
玩转SQL Server复制回路の变更数据类型.未分区表转为分区表 复制的应用: 初级应用:读写分离.数据库备份 高级应用:搬迁大型数据库(跨机房).变更数据类型.未分区表转为分区表 京东的复制专家 ...
- sql server 小记——分区表(上)
我们知道很多事情都存在一个分治的思想,同样的道理我们也可以用到数据表上,当一个表很大很大的时候,我们就会想到将表拆 分成很多小表,查询的时候就到各个小表去查,最后进行汇总返回给调用方来加速我们的查询速 ...
随机推荐
- dojo/dom dojo/domConstruct dojo/query
dom.byId require(["dojo/dom", "dojo/domReady!"], function(dom) { var one = dom.b ...
- jquery plugins
jQuery官网插件 jQuery自定义滚动条样式插件 jQuery custom content scroller examples Twitter typeahead typeahead.js t ...
- 如何查看Python的内置函数
经常调用的时候不知道python当前版本的内置函数是哪些,可以用下面的指令查看: C:\Users\Administrator>python Python 2.7.11 (v2.7.11:6d1 ...
- shell脚本中变量$$、$0等的含义
$0 这个程式的执行名字$n 这个程式的第n个参数值,n=1..9$* 这个程式的所有参数,此选项参数可超过9个.$# 这个程式的参数个数$$ 这个程式的PID(脚本运行的当前进程ID号)$! 执行上 ...
- linux进程调度方法(SCHED_OTHER,SCHED_FIFO,SCHED_RR)
转于:http://blog.csdn.net/maray/article/details/2900689 Linux内核的三种调度方法: 1,SCHED_OTHER 分时调度策略, 2,SCHED_ ...
- [BIM]案例
以下是中建三局BIM小组的项目,用以参考: BIM协同设计与质量控制 现实建筑物实体都是以三维空间状态存在,若用三维设计表达更具有优势.如复杂管综设计,一般情况下,二维AutoCAD设计是在建筑.结构 ...
- hack是什么
不同浏览器对css的解析是不同是,因此需要css hack来解决浏览器局部的兼容性问题.针对不同浏览器写不同的CSS代码的过程叫CSS Hack. 常见的hack有三种形式,分别是CSS属性hack ...
- day3 python 函数
常犯的错误: IndentationError:expected an indented block说明此处需要缩进,你只要在出现错误的那一行,按空格或Tab(但不能混用)键缩进就行... 函数是指一 ...
- Android关机闹钟实现
Android关机闹钟实现 时间转换网站:http://tool.chinaz.com/Tools/unixtime.aspx 1.apk层 这个还是比较简单的,百度一下就可以看到apk的代码,我之前 ...
- HDU 4707:Pet
Pet Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submis ...