SQL Server 批量完整备份
一.本文所涉及的内容(Contents)
二.背景(Contexts)
在公司的内网有台数据库的测试服务器,这台服务器是提供给开发人员使用的,在上面有很多的数据库,有些是临时系统用到的数据库,这些数据库有一个共同点:数据库表结构比较重要,数据库只有一些测试数据,也就是说这些数据库都很小,而整台服务器的数据库又非常多;
现在有这样一个需求,希望间隔一段时间就备份所有数据库,所以这里写了这篇文章,这也是另外一篇文章SQL Server 批量主分区备份(One Job)的基础;
三.实现代码(SQL Codes)
下面是实现批量备份数据库的3种方式,大家可以细细体会其中的差别:
1) 实现方式1:使用游标
2) 实现方式2:使用拼凑SQL的方式
3) 实现方式3:使用存储过程sp_MSforeachdb_Filter(以sp_MSforeachdb为基础)
(一)实现方式1:使用游标
执行下面的SQL脚本就可以备份当前数据库实例的所有数据库(除了系统数据库);
-- =============================================
-- Author: <听风吹雨>
-- Blog: <http://gaizai.cnblogs.com/>
-- Create date: <2011/12/03>
-- Description: <批量备份数据库>
-- =============================================
DECLARE
@FileName VARCHAR(200),
@CurrentTime VARCHAR(50),
@DBName VARCHAR(100),
@SQL VARCHAR(1000) SET @CurrentTime = CONVERT(CHAR(8),GETDATE(),112) + CAST(DATEPART(hh, GETDATE()) AS VARCHAR) + CAST(DATEPART(mi, GETDATE()) AS VARCHAR) DECLARE CurDBName CURSOR FOR
SELECT NAME FROM Master..SysDatabases where dbid>4 OPEN CurDBName
FETCH NEXT FROM CurDBName INTO @DBName
WHILE @@FETCH_STATUS = 0
BEGIN
--Execute Backup
SET @FileName = 'E:\DBBackup\' + @DBName + '_' + @CurrentTime
SET @SQL = 'BACKUP DATABASE ['+ @DBName +'] TO DISK = ''' + @FileName + '.bak' +
''' WITH NOINIT, NOUNLOAD, NAME = N''' + @DBName + '_backup'', NOSKIP, STATS = 10, NOFORMAT'
EXEC(@SQL) --Get Next DataBase
FETCH NEXT FROM CurDBName INTO @DBName
END CLOSE CurDBName
DEALLOCATE CurDBName
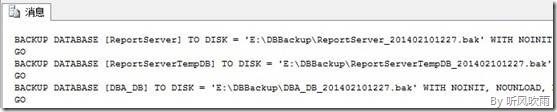
执行完上面的SQL脚本,会在E:\DBBackup的目录下生成类似下图的备份文件:

(Figure1:数据库备份文件)
(二)实现方式2:使用拼凑SQL的方式
--使用拼凑SQL的方式
DECLARE @SQL VARCHAR(MAX) SELECT @SQL = COALESCE(@SQL,'') + '
BACKUP DATABASE '+ QUOTENAME(name,'[]')
+ ' TO DISK = ''E:\DBBackup\'+ name + '_' + CONVERT(CHAR(8),GETDATE(),112) + CAST(DATEPART(hh, GETDATE()) AS VARCHAR) + CAST(DATEPART(mi, GETDATE()) AS VARCHAR) + '.bak'
+ ''' WITH NOINIT, NOUNLOAD, NAME = N''' + name + '_backup'', NOSKIP, STATS = 10, NOFORMAT'
FROM sys.databases WHERE database_id >4 AND name like '%%' AND state =0 PRINT(@SQL)
EXECUTE(@SQL)
生成的脚本如Figure2所示,如果想脚本更加美观,可以加上GO语句,如Figure3所示:

(Figure2:生成的T-SQL脚本)
(Figure3:生成的T-SQL脚本)
(三)实现方式3:使用存储过程sp_MSforeachdb_Filter(以sp_MSforeachdb为基础)
通过查看系统存储过程sp_MSforeachdb的T-SQL源代码可以发现是没有提供@whereand参数可以过滤数据库的,参考系统存储过程sp_MSforeachtable后,在sp_MSforeachdb的基础上创建带@whereand参数的存储过程sp_MSforeachdb_Filter,这样你就可以让SQL在指定的数据库上执行;
-- =============================================
-- Author: <听风吹雨>
-- Blog: <http://gaizai.cnblogs.com/>
-- Create date: <2013.05.06>
-- Description: <扩展sp_MSforeachdb,增加@whereand参数>
-- =============================================
USE [master]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER OFF
GO create proc [dbo].[sp_MSforeachdb_Filter]
@command1 nvarchar(2000), @replacechar nchar(1) = N'?', @command2 nvarchar(2000) = null, @command3 nvarchar(2000) = null,
@whereand nvarchar(2000) = null,@precommand nvarchar(2000) = null, @postcommand nvarchar(2000) = null
as
set deadlock_priority low /* This proc returns one or more rows for each accessible db, with each db defaulting to its own result set */
/* @precommand and @postcommand may be used to force a single result set via a temp table. */ /* Preprocessor won't replace within quotes so have to use str(). */
declare @inaccessible nvarchar(12), @invalidlogin nvarchar(12), @dbinaccessible nvarchar(12)
select @inaccessible = ltrim(str(convert(int, 0x03e0), 11))
select @invalidlogin = ltrim(str(convert(int, 0x40000000), 11))
select @dbinaccessible = N'0x80000000' /* SQLDMODbUserProf_InaccessibleDb; the negative number doesn't work in convert() */ if (@precommand is not null)
exec(@precommand) declare @origdb nvarchar(128)
select @origdb = db_name() /* If it's a single user db and there's an entry for it in sysprocesses who isn't us, we can't use it. */
/* Create the select */
exec(N'declare hCForEachDatabase cursor global for select name from master.dbo.sysdatabases d ' +
N' where (d.status & ' + @inaccessible + N' = 0)' +
N' and (DATABASEPROPERTY(d.name, ''issingleuser'') = 0 and (has_dbaccess(d.name) = 1))' + @whereand) declare @retval int
select @retval = @@error
if (@retval = 0)
exec @retval = sys.sp_MSforeach_worker @command1, @replacechar, @command2, @command3, 1 if (@retval = 0 and @postcommand is not null)
exec(@postcommand) declare @tempdb nvarchar(258)
SELECT @tempdb = REPLACE(@origdb, N']', N']]')
exec (N'use ' + N'[' + @tempdb + N']') return @retval
上面的存储过程sp_MSforeachdb_Filter与sp_MSforeachdb的区别有以下两点:

(Figure4:添加内容1)

(Figure5:添加内容2)
而且需要注意在创建存储过程的时候需要设置SET QUOTED_IDENTIFIER OFF,当 SET QUOTED_IDENTIFIER 为 ON 时,标识符可以由双引号分隔,而文字必须由单引号分隔;当 SET QUOTED_IDENTIFIER 为 OFF 时,标识符不可加引号,且必须符合所有 Transact-SQL 标识符规则。具体可以参考:SET QUOTED_IDENTIFIER (Transact-SQL)
调用sp_MSforeachdb_Filter实现批量备份数据库的T-SQL如下所示:
--使用更新的存储过程sp_MSforeachdb_Filter(以sp_MSforeachdb为基础)
USE [master]
GO DECLARE @SQL NVARCHAR(MAX)
SELECT @SQL = COALESCE(@SQL,'') + '
BACKUP DATABASE [?]
TO DISK = ''E:\DBBackup\?_' + CONVERT(CHAR(8),GETDATE(),112) + CAST(DATEPART(hh, GETDATE()) AS VARCHAR) + CAST(DATEPART(mi, GETDATE()) AS VARCHAR) + '.bak''
WITH NOINIT, NOUNLOAD, NAME = N''?_backup'', NOSKIP, STATS = 10, NOFORMAT' PRINT @SQL --过滤数据库
EXEC [sp_MSforeachdb_Filter] @command1=@SQL,
@whereand=" and [name] not in('tempdb','master','model','msdb') "
执行上面的存储过程就可以备份所有数据库(系统数据库除外,想要过滤数据库可以填写@whereand参数的条件),执行上面SQL的效果如下图所示:
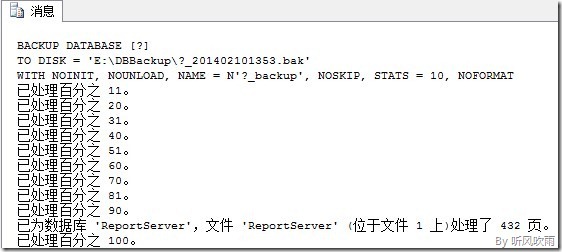
(Figure6:错误信息)
如果没有设置SET QUOTED_IDENTIFIER 这个选项为 OFF ,那么在调用存储过程sp_MSforeachdb_Filter的时候会出现下图所示的错误信息:
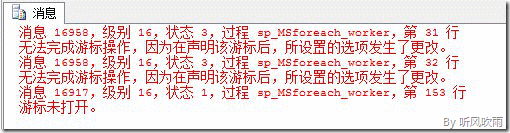
(Figure7:错误信息)
如果想查看存储过程sp_MSforeachdb的详细代码,可以在通过访问路径:数据库-可编程性-存储过程-系统存储过程-sp_MSforeachdb找到,或者通过下面的脚本查看:
--显示规则、默认值、未加密的存储过程、用户定义函数、触发器或视图的文本
EXEC sp_helptext N'sp_MSforeachdb';
更多批量备份数据库的文章可以参考:
SQL Server批量主分区备份(Multiple Jobs)
四.参考文献(References)
SET QUOTED_IDENTIFIER (Transact-SQL)(英文)
SET QUOTED_IDENTIFIER (Transact-SQL)(中文)
SQL Server 批量完整备份的更多相关文章
- [转]SQL Server 批量完整备份
最近我们的服务器需要迁移,服务器上有很多数据库,有很多都不知道干什么的了,但是为了保险起见,我决定都备份下,起初我是右键一个一个备份的,备份三四个还好,可是数据库太多了,而且手动一步一步操作,还得修改 ...
- SQL Server 批量主分区备份(Multiple Jobs)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 案例分析(Case) 方案一(Solution One) 方案二(Solution Two) ...
- SQL Server 批量主分区备份(One Job)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 案例分析(Case) 实现代码(SQL Codes) 主分区完整.差异还原(Primary B ...
- SQL Server 批量创建作业(备份主分区)
一. 需求背景 在我的数据库实例中,有很多类似下图所示的数据库,这些数据库的名称是有规律的,每个数据库包含的表都是相同的,其中2个表是类似流水记录的表,表的数据量会比较大,占用的空间有几十G到上百G不 ...
- 对 sql server 数据库的备份进行加密
原文:对 sql server 数据库的备份进行加密 嗯,最近在研究数据库备份相关的东西,考虑到应该为数据库备份加个密,就准备从网上搜索一下看看有什么好办法,没想到还挺乱... 首先,我从网上搜到的, ...
- SQL Server 2005数据库定期备份(非常详细)与 SQL Server 2005数据库备份定期清理
SQL Server 2005数据库定期备份 分类: SQL Server 20052011-01-06 16:25 3320人阅读 评论(1) 收藏 举报 sql server数据库sqlserv ...
- SQL Server 数据库使用备份还原造成的孤立用户和对象名‘xxx’无效的错误的解决办法
SQL Server 数据库使用备份还原造成的孤立用户和对象名‘xxx’无效的错误的解决办法 在使用数据库的过程中,经常会遇到数据库迁移或者数据迁移的问题,或者有突然的数据库损坏,这时需要从数据库的备 ...
- SQL Server系统数据库备份最佳实践
原文:SQL Server系统数据库备份最佳实践 首先了解主要的系统数据库: 系统数据库 master 包含登录信息和其他数据库的核心信息 msdb 存储作业.操作员.警报.备份还原历史.数据库邮件信 ...
- 用分离、附加的方式实现sql server数据库的备份和还原
一.数据库分离.附加的说明 SQL Server提供了"分离/附加"数据库."备份/还原"数据库.复制数据库等多种数据库的备份和恢复方法.这里介绍一种学习中常用 ...
随机推荐
- Akka.net路径里的user
因为经常买双色球,嫌每次对彩票号麻烦,于是休息的时候做了个双色球兑奖的小程序,做完了发现业务还挺复杂的,于是改DDD重做设计,拆分服务,各种折腾...,不过这和本随笔没多大关系,等差不多了再总结一下, ...
- 在传统.NET Framework 上运行ASP.NET Core项目
新的项目我们想用ASP.NET Core来开发,但是苦于我们历史的遗产很多,比如<使用 JavaScriptService 在.NET Core 里实现DES加密算法>,我们要估计等到.N ...
- MVC Core 网站开发(Ninesky) 1、创建项目
又要开一个新项目了!说来惭愧,以前的东西每次都没写完,不是不想写完,主要是我每次看到新技术出来我都想尝试一下,看到.Net Core 手又痒了,开始学MVC Core. MVC Core最吸引我的有三 ...
- DDD 领域驱动设计-商品建模之路
最近在做电商业务中,有关商品业务改版的一些东西,后端的架构设计采用现在很流行的微服务,有关微服务的简单概念: 微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成.系统中的各个微服务可被独 ...
- java中if和switch哪个效率快
首先要看一个问题,if 语句适用范围比较广,只要是 boolean 表达式都可以用 if 判断:而 switch 只能对基本类型进行数值比较.两者的可比性就仅限在两个基本类型比较的范围内.说到基本类型 ...
- CSS margin详解
以下的分享是本人最近几天学习了margin知识后,大有启发,感觉以前对margin的了解简直太浅薄.所以写成以下文章,一是供自己整理思路:二是把知识分享出来,避免各位对margin属性的误解.内容可能 ...
- Android中使用ExpandableListView实现微信通讯录界面(完善仿微信APP)
之前的博文<Android中使用ExpandableListView实现好友分组>我简单介绍了使用ExpandableListView实现简单的好友分组功能,今天我们针对之前的所做的仿微信 ...
- iOS开发--ChildViewController实现订单页的切换
先不说废话, 上效果图, 代码量也不大, 也不上传github骗星星了, 你们复制粘贴下代码, 就可以轻而易举的弄出一个小demo. 这个代码的实现并不复杂, 甚至于说非常简单, 就是逻辑有点小绕, ...
- 如何区别exists与not exists?
1.exists:sql返回结果集为真:not exists:sql不返回结果集为真.详解过程如图: exists not exists
- sqlyog导出json数据格式支持mysql数据转存mongodb
<!-------------知识的力量是无限的(当然肯定还有更简单的方法)-----------!> 当我考虑将省市区三级联动数据从mysql转入mongodb时遇到了网上无直接插入mo ...