ElasticSearch 5学习(5)——第一个例子(很实用)
想要知道ElasticSearch是如何使用的,最快的方式就是通过一个简单的例子,第一个例子将会包括基本概念如索引、搜索、和聚合等,需求是关于公司管理员工的一些业务。
员工文档索引
业务首先需要存储员工数据。这将采取一个员工文档的形式:单个文档表示单个员工。在Elasticsearch中存储数据的行为称为索引,但是在索引文档之前,我们需要决定在哪里存储它。
在Elasticsearch中,文档属于某个类型,这些类型位于索引中。可以绘制一些(粗略)与传统关系数据库的对比:
Relational DB ⇒ Databases ⇒ Tables ⇒ Rows ⇒ Columns
Elasticsearch ⇒ Indices ⇒ Types ⇒ Documents ⇒ Fields
Elasticsearch集群可以包含多个索引(数据库),这些索引又包含多个类型(表)。这些类型包含多个文档(行),每个文档都有多个字段(列)。
您可能已经注意到,在Elasticsearch的上下文中,索引被重载了几个含义。如下:
- 索引(名词):正如前面所解释的那样,索引就像传统的关系数据库中的数据库一样。它是存储相关文档的地方。index的复数形式是indices或indexes。
- 索引(动词):索引一个文档是将一个文档存储在索引(名词)中,以便它可以检索和查询。它很像插入关键词SQL。此外,如果文档已经存在,新的文档将取代旧的。
- 倒排索引:关系数据库中增加一个索引,如B-树索引,对特定列为了提高数据检索的速度。Elasticsearch和Lucene提供相同目的的索引称为倒排索引。
默认情况下,文档中的每个字段索引(有一个倒排索引)这样的搜索。一个没有倒排索引字段不可搜索。
因此我们的员工目录,我们需要处理如下事情:
- 索引的每个文档,包含每个员工的所有细节。
- 每个文档都属于
employee类型。 - 类型都包含在
megacop索引中。 - 该索引将驻留我们Elasticsearch集群内。
下面通过命令去索引第一个员工:
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
注意/megacorp/employee/1包含的信息。
megacorp:索引的名称
emplogee:类型的名称
1:员工的id
成功执行返回的是一个JSON文本,包含所有关于该员工的信息。
注意:
- 如果执行过程中失败了,可能存在的原因是elasticsearch默认配置中不允许自动创建索引,所以我们可以先简单在elasticsearch.yml配置文件添加
action.auto_create_index:true,允许自动创建索引。 - 没有必要首先执行任何管理任务,如创建一个索引或指定每个字段所包含的数据类型。我们可以直接索引一个文档。Elasticsearch附带默认的一切,因此所有必要的管理任务都会使用默认值在后台处理。
在目录中添加更多的员工:
PUT /megacorp/employee/2
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
PUT /megacorp/employee/3
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}
检索文档
现在我们有一些数据存储在Elasticsearch中,我们可以开始处理这个应用程序的业务需求。第一个要求是检索单个员工数据的能力。
这在Elasticsearch中很容易。我们只需执行HTTP GET请求并指定文档的地址——索引,类型和ID。使用这三个信息,我们可以返回原始的JSON文档,并且响应包含有关文档的一些元数据,以及Douglas Fir的原始JSON文档作为_source字段:
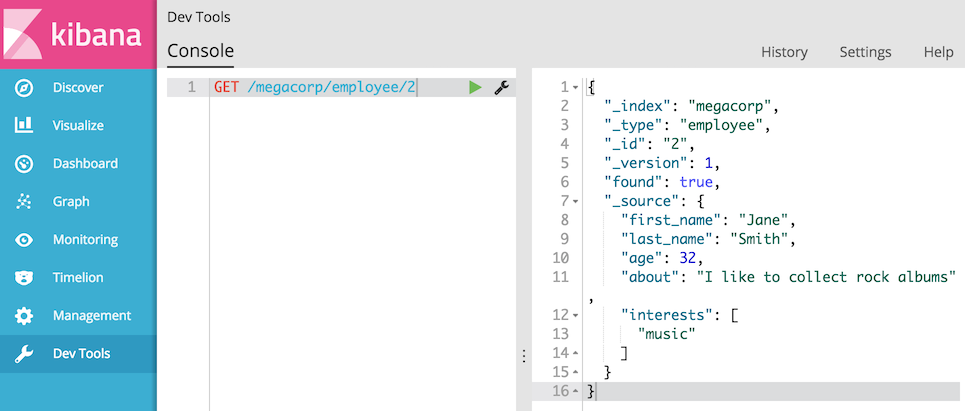
可以查看:ElasticSearch 5学习(4)——简单搜索笔记
以同样的方式,我们将HTTP动词从PUT更改为GET以便检索文档,我们可以使用DELETE动词删除文档,并使用HEAD动词检查文档是否存在。要用更新的版本替换现有文档,我们只需再次PUT。
GET很简单,可以得到要求的文件。尝试一些更高级的东西,我们可以搜索所有员工,请求:
GET /megacorp/employee/_search
您可以看到我们仍在使用索引megacorp和类型employee,但是我们现在使用_search端点,而不是指定文档ID。响应包括我们在hits数组中的所有三个文档。默认情况下,搜索将返回前10个结果。
响应不仅告诉我们哪些文档匹配,而且还包括整个文档本身,以便向用户显示搜索结果的所有信息。
接下来,让我们尝试搜索在其姓氏中有“Smith”的员工。为此,我们将使用一个轻松的搜索方法,它很容易从命令行使用。此方法通常称为查询字符串搜索,因为我们将搜索作为URL查询字符串参数传递:
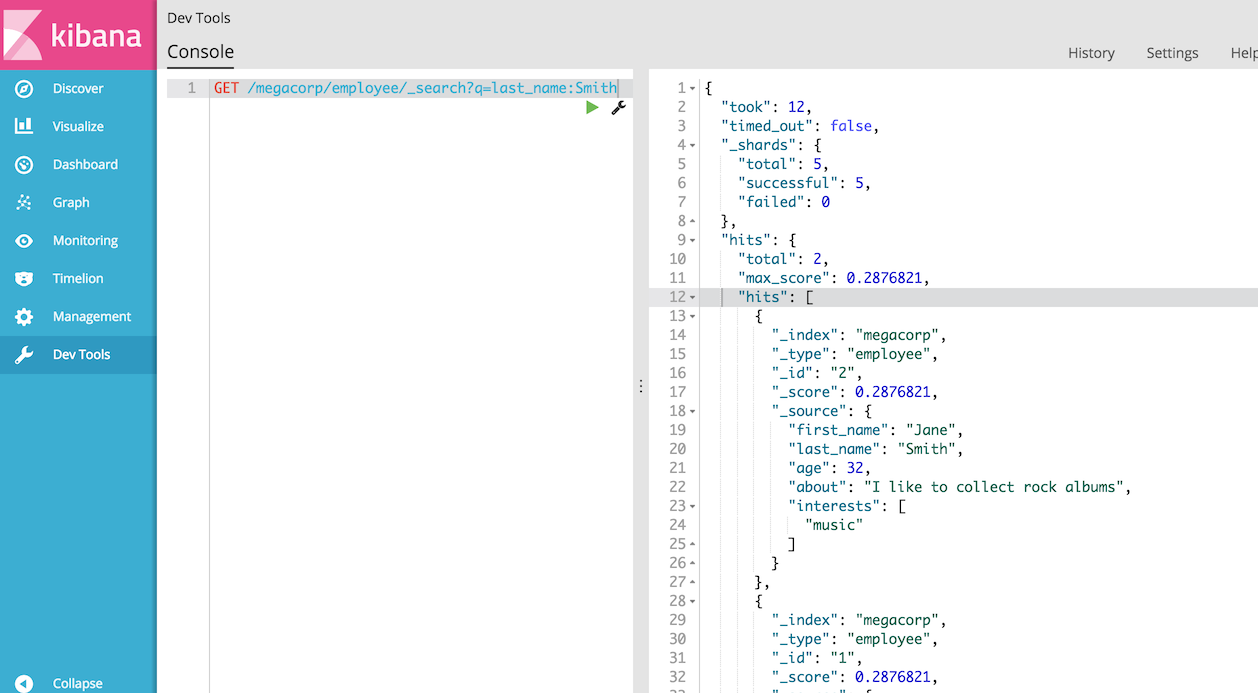
DSL查询
查询字符串搜索对于从命令行进行搜索非常方便,但它有其局限性。Elasticsearch提供了一种丰富,灵活的查询语言,称为查询DSL,它允许我们构建更复杂,更健壮的查询。
使用JSON请求正文指定域特定语言(DSL)。我们可以代表所有以前的搜索,像这样:
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}
这将返回与上一个查询相同的结果。可以看到一些事情已经改变。例如,我们不再使用查询字符串参数,而是使用请求正文。此请求体是使用JSON构建的,并使用匹配查询。
让我们让搜索更复杂一点。我们仍然希望找到所有名字为Smith的员工,但我们只想要30岁以上的员工。我们的查询将稍微改变一点,以容纳一个过滤器,这使我们能够有效地执行结构化搜索:
GET /megacorp/employee/_search
{
"query" : {
"bool" : {
"must" : {
"match" : {
"last_name" : "smith"
}
},
"filter" : {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}
我们添加了一个过滤器,执行范围搜索,并重复使用与以前相同的匹配查询。
现在我们的结果显示只有一个员工刚好是32并被命名为smith:
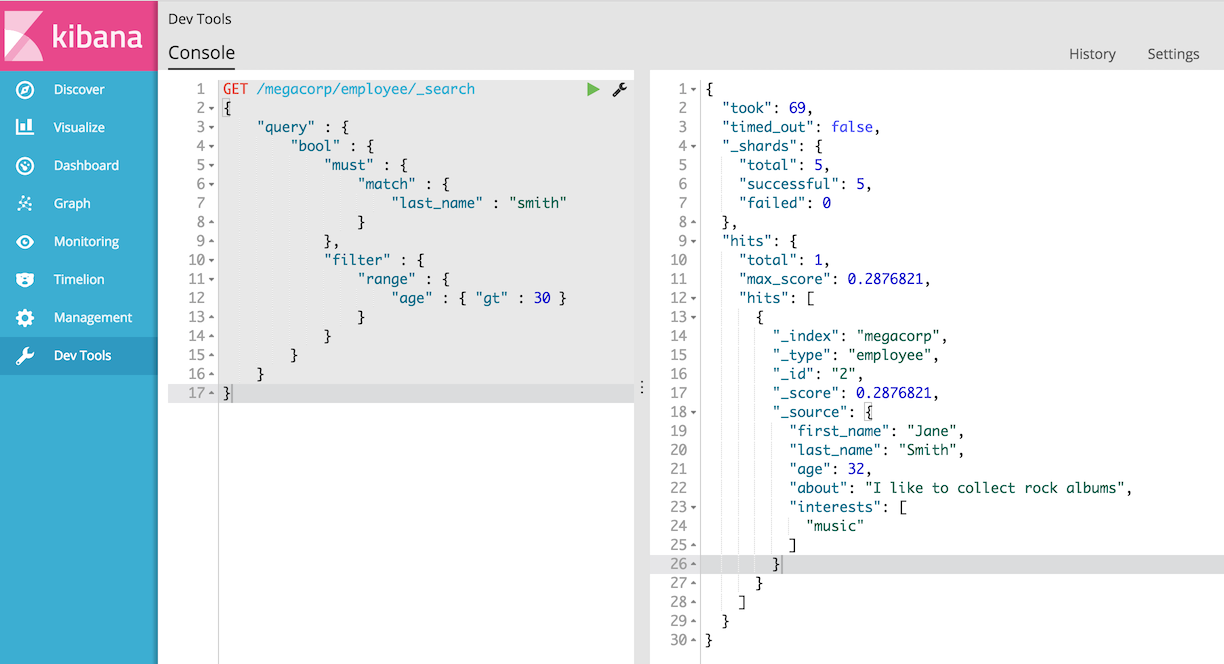
注意:关于过滤器在Elasticsearch2.0开始有很大的更新,所以有些过滤操作可能会报错。例如:filtered query已经被废弃。
全文搜索(Full-Text Search)
到目前为止的搜索很简单:单个名字,按年龄过滤。让我们尝试更高级的全文搜索,传统数据库真正难以胜任的任务。
我们将寻找所有喜欢攀岩的员工:
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}
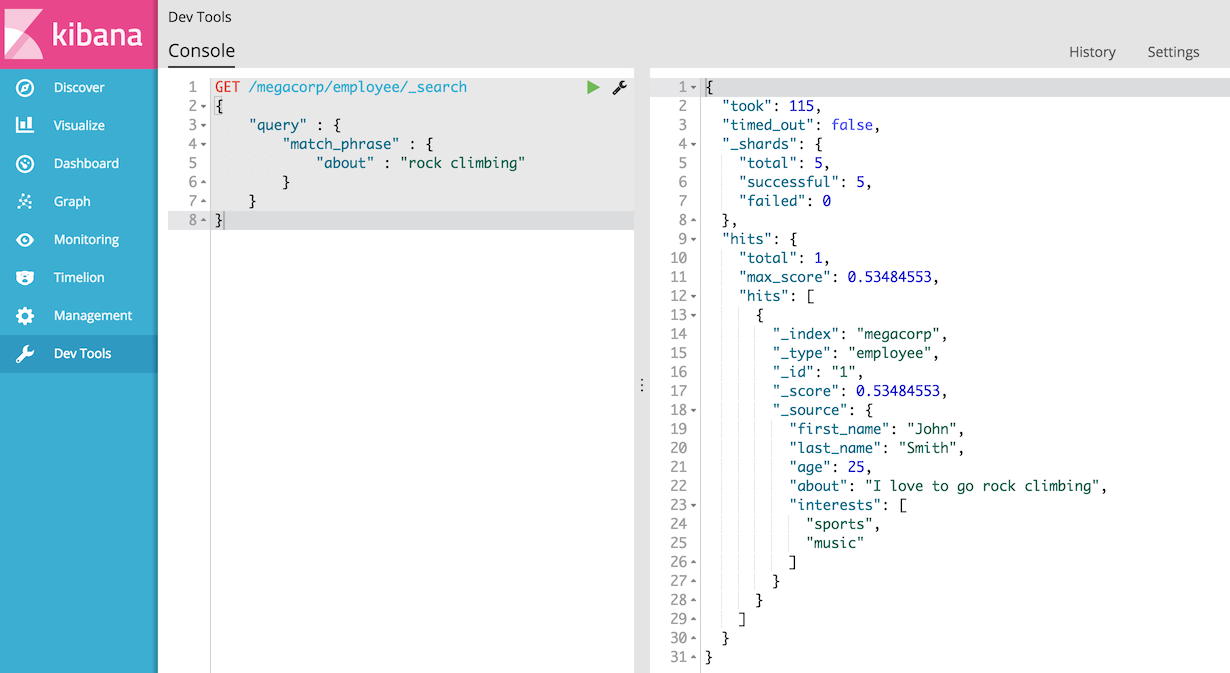
您可以看到我们使用与之前相同的匹配查询来搜索关于“攀岩”字段。我们得到两个匹配的文档:
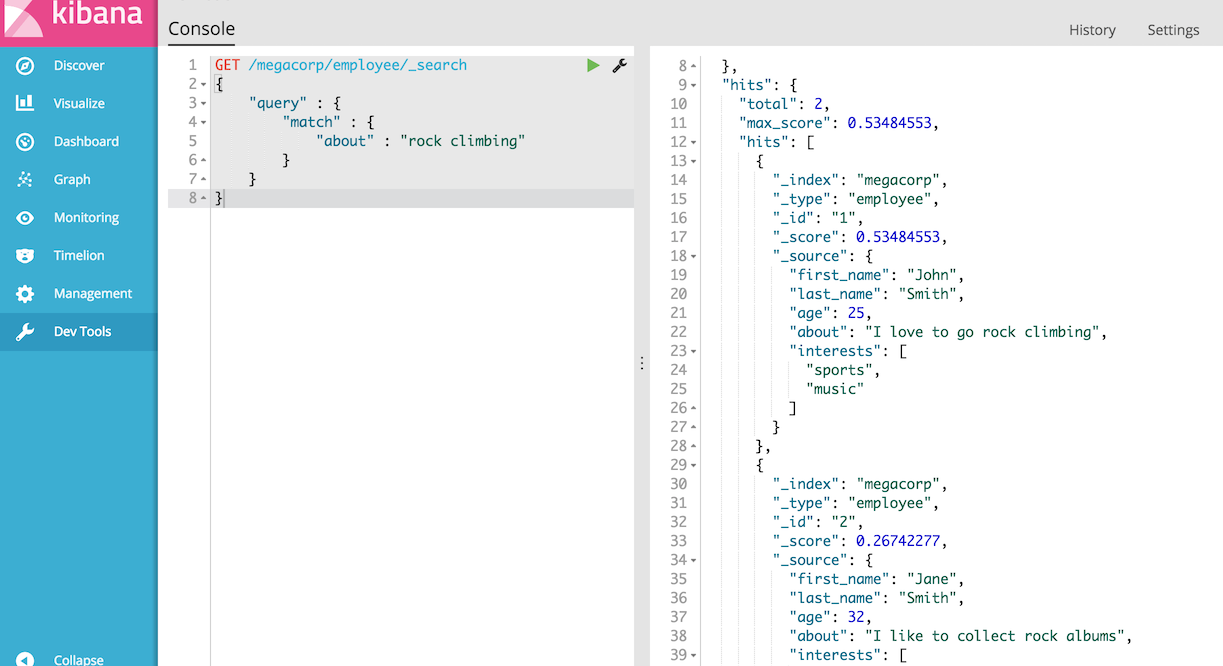
默认情况下,Elasticsearch按匹配结果的相关性分值(即每个文档与查询匹配程度)对匹配结果进行排序。第一个和最高分的结果是显而易见的:John·Smith关于字段清楚地说“攀岩”。
但为什么Jane·Smith也返回了?她的文档被返回的原因是因为在她的字段中提到了“rock”这个词。因为只有“岩石”被提及,而不是“攀登”,她的分数低于John的。
这是Elasticsearch如何在全文字段中进行搜索并返回最相关的结果的一个很好的例子。这种相关性的概念对于Elasticsearch很重要,并且是一个完全与传统关系数据库无关的概念,其中记录匹配或不匹配。
精确字段搜索
在字段中查找单个字词是很好的,但有时你想要匹配字词或短语的确切序列。例如,我们可以执行一个查询,该查询将仅匹配包含“rock”和“climbing”的员工记录,并在短语“rock climbing”中显示彼此相邻的单词。
为此,我们使用改为match_phrase查询:
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}
仅返回John Smith的文档
高亮搜索结果
许多应用程序喜欢从每个搜索结果突出显示文本片段,以便用户可以看到文档与查询匹配的原因。在Elasticsearch中检索突出显示的片段很容易。
让我们重新运行我们以前的查询,但添加一个新的highlight参数:
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}
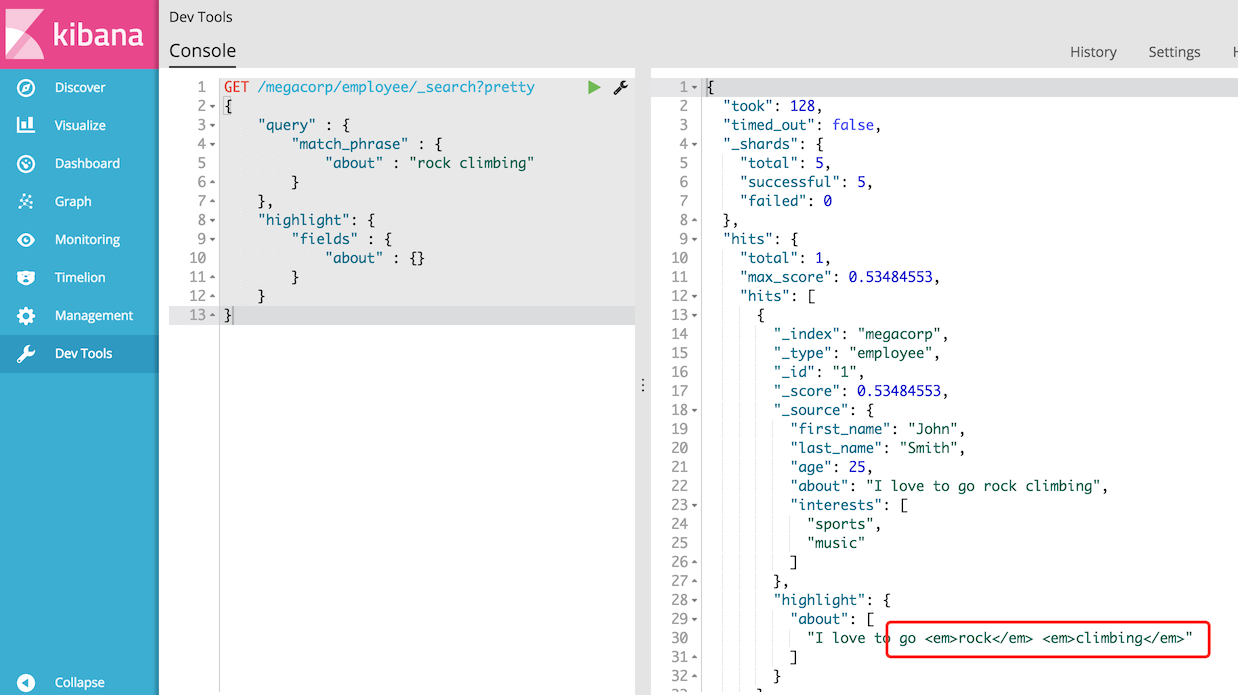
当我们运行此查询时,将返回与之前相同的返回,但现在我们在响应中得到一个新的部分,称为突出显示。
这包含来自about字段的文字片段,其中包含在 HTML标记中包含的匹配单词:
分析
最后,我们来到我们的最后一个业务需求:允许管理员在员工目录上运行分析。Elasticsearch具有称为聚合的功能,允许您对数据生成复杂的分析。它类似于GROUP BY中的SQL,但功能更强大。
例如,让我们找到我们的员工最喜欢的兴趣:
GET /megacorp/employee/_search
{
"aggs": {
"all_interests": {
"terms": { "field": "interests" }
}
}
}
如果Elasticsearch 5版本以前,将会返回:
{
...
"hits": { ... },
"aggregations": {
"all_interests": {
"buckets": [
{
"key": "music",
"doc_count": 2
},
{
"key": "forestry",
"doc_count": 1
},
{
"key": "sports",
"doc_count": 1
}
]
}
}
}
我们可以看到,两个员工对音乐感兴趣,一个在林业,一个在体育。这些聚合不是预先计算的,它们是从与当前查询匹配的文档即时生成的。
然而如果我们使用的是Elasticsearch 5版本以上的话,将会出现如下异常:
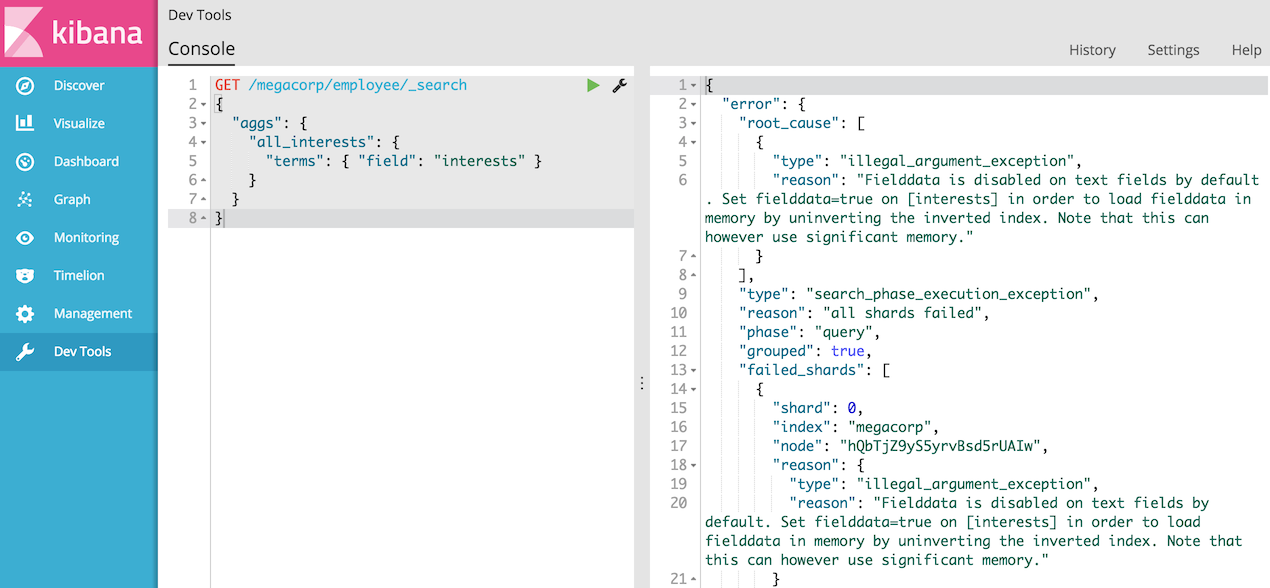
我们可以查看Elasticsearch 5.0文档——Fielddata is disabled on text fields by default
大概的意思是:Fielddata可以消耗大量的堆空间,特别是在加载高基数文本字段时。一旦fielddata已经加载到堆中,它在该段的生存期内保持。此外,加载fielddata是一个昂贵的过程,可以导致用户体验延迟命中。
所以fielddata默认禁用。如果尝试对文本字段上的脚本进行排序,聚合或访问值,就会看到这个异常,具体使用可以参考手册。
总结
这个小例子是一个很好的演示了什么是Elasticsearch。它只是很肤浅的介绍了简单的使用,许多功能被省略,以保持简短。但是这也突出了开始构建高级搜索功能是多么容易。
转载请注明出处。
作者:wuxiwei
出处:http://www.cnblogs.com/wxw16/p/6185378.html
ElasticSearch 5学习(5)——第一个例子(很实用)的更多相关文章
- ElasticSearch 5学习(5)——第一个例子
想要知道ElasticSearch是如何使用的,最快的方式就是通过一个简单的例子,第一个例子将会包括基本概念如索引.搜索.和聚合等,需求是关于公司管理员工的一些业务. 员工文档索引 业务首先需要存储员 ...
- 疯狂delphi - 朱建强 (一些小例子很实用,也是我所关心的几个问题)
疯狂delphi - 朱建强 (一些小例子很实用,也是我所关心的几个问题) Android实例-获取安卓手机WIFI信息(XE8+小米2)http://www.cnblogs.com/FKdelphi ...
- MXNet学习~第一个例子~跑MNIST
反正基本上是给自己看的,直接贴写过注释后的代码,可能有的地方理解不对,你多担待,看到了也提出来(基本上对未来的自己说的),三层跑到了97%,毕竟是第一个例子,主要就是用来理解MXNet怎么使用. #导 ...
- 菜鸟学习Spring——第一个例子
一.概述 原来我们利用工厂来实现灵活的配置.现在利用Spring以后把这个交给了IoC容器管理.我们只要在XML文件上配上就可以了这样的话就节省了很多开发时间我们不需要知道后面的有多少只要动态的配上类 ...
- 初探 Elasticsearch,学习笔记第一讲
1. ES 基础 1.1 ES定义 ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储.检索数据:本身扩展 ...
- Keras学习~第一个例子~跑MNIST
import numpy as npimport gzip import struct import keras as ks import logging from keras.layers impo ...
- emberjs学习一(环境和第一个例子)
code { margin: 0; padding: 0; white-space: pre; border: none; background: transparent; } code, pre t ...
- GLSL着色语言学习。橙皮书第一个例子GLSL+OpenTK+F#的实现。
Opengl红皮书有选择的看了一些,最后的讲着色语言GLSL的部分看的甚为不理解,然后找到Opengl橙皮书,然后就容易理解多了. 在前面,我们或多或少接触到Opengl的处理过程,只说前面一些处理, ...
- MXNet学习-第一个例子:训练MNIST数据集
一个门外汉写的MXNET跑MNIST的例子,三层全连接层最后验证率是97%左右,毕竟是第一个例子,主要就是用来理解MXNet怎么使用. #导入需要的模块 import numpy as np #num ...
随机推荐
- .Net Core MVC 网站开发(Ninesky) 2.4、添加栏目与异步方法
在2.3中完成依赖注入后,这次主要实现栏目的添加功能.按照前面思路栏目有三种类型,常规栏目即可以添加子栏目也可以选择是否添加内容,内容又可以分文章或其他类型,所以还要添加一个模块功能.这次主要实现栏目 ...
- GreenDao 数据库:使用Raw文件夹下的数据库文件以及数据库升级
一.使用Raw文件夹下的数据库文件 在使用GreenDao框架时,数据库和数据表都是根据生成的框架代码来自动创建的,从生成的DaoMaster中的OpenHelper类可以看出: public sta ...
- iOS开发系列--打造自己的“美图秀秀”
--绘图与滤镜全面解析 概述 在iOS中可以很容易的开发出绚丽的界面效果,一方面得益于成功系统的设计,另一方面得益于它强大的开发框架.今天我们将围绕iOS中两大图形.图像绘图框架进行介绍:Quartz ...
- ABP文档 - 目录
ABP框架 概览 介绍 多层结构 模块系统 启动配置 多租户 集成OWIN 共同结构 依赖注入 会话 缓存 日志 设置管理 时间 领域层 实体 值对象(新) 仓储 领域服务 工作单元 领域事件(Eve ...
- OpenCASCADE AIS Manipulator
OpenCASCADE AIS Manipulator eryar@163.com Abstract. OpenCASCADE7.1.0 introduces new built-in interac ...
- 微软Azure 经典模式下创建内部负载均衡(ILB)
微软Azure 经典模式下创建内部负载均衡(ILB) 使用之前一定要注意自己的Azure的模式,老版的为cloud service模式,新版为ARM模式(资源组模式) 本文适用于cloud servi ...
- JAVA问题集锦Ⅰ
1.Java的日期添加: import java.util.Date ; date=new date();//取时间 Calendar calendar = new GregorianCalendar ...
- Nexus(一)环境搭建
昨天,成功搭建了自己的 Maven 环境(详见:Maven(一)环境搭建),今天就来研究和探讨下 Nexus 的搭建! 使用背景: 安装环境:Windows 10 -64位 JDK版本:1.7 Mav ...
- 游走 bzoj 3143
游走(2s 128MB)walk [问题描述] [输入格式] [输出格式] [样例输入] 3 3 2 3 1 2 1 3 [样例输出] 3.333 [样例说明] 题解: 主要算法:贪心:高斯消元: 题 ...
- [转载]SQL语句中的日期计算
1. 本月的第一天SELECT DATEADD(mm, DATEDIFF(mm,0,getdate()), 0) 2. 本月的最后一天SELECT dateadd(ms,-3,DATEADD( ...