【解决】ValueError: Memory growth cannot differ between GPU devices
在ubuntu系统下双显卡运行TensorFlow代码报错:
ValueError: Memory growth cannot differ between GPU devices
报错的代码位置为: tf.config.experimental.set_memory_growth(physical_devices[0], True)
全部代码:
import os
import tensorflow as tf
from tensorflow.keras.applications import resnet50 physical_devices = tf.config.list_physical_devices('GPU')
print(physical_devices) tf.config.experimental.set_memory_growth(physical_devices[0], True) #加载预训练模型
model = resnet50.ResNet50(weights='imagenet') #save_model方式保存模型
tf.saved_model.save(model, "resnet/1/")
报错:

===============================================
查了网上的各种说法,有的说是TensorFlow的版本问题,有的说是TensorFlow的bug问题,有的说的gpu的版本问题(只有rtx2070和rtx2080的双显卡才会报错)
于是我就换了在服务器上运行,服务器为4卡泰坦,运行结果与上面的相同。
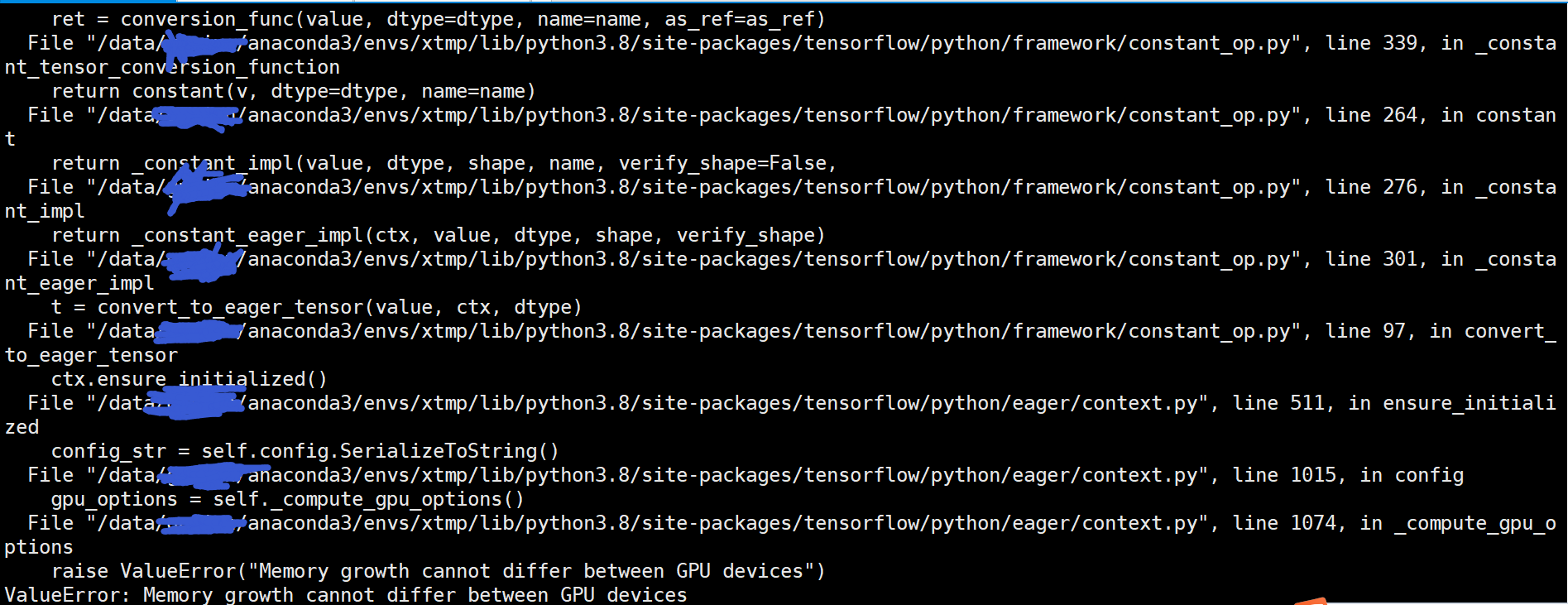
通过这样的对比实验我们可以得出结论,那就是这个并不是TensorFlow版本问题或是显卡版本问题,而是对于多显卡的运行模式下上面的写法并不是很正确,这本身就是TensorFlow的预先设定。
=====================================================
如果代码修改下就可以不报错,也就是添加内容:os.environ['CUDA_VISIBLE_DEVICES']='0'
import os
import tensorflow as tf
from tensorflow.keras.applications import resnet50 os.environ['CUDA_VISIBLE_DEVICES']='0' physical_devices = tf.config.list_physical_devices('GPU')
print(physical_devices) tf.config.experimental.set_memory_growth(physical_devices[0], True) #加载预训练模型
model = resnet50.ResNet50(weights='imagenet') #save_model方式保存模型
tf.saved_model.save(model, "resnet/1/")
运行正常不报错:

如果修改成下面这样,依然报同样的错误。
import os
import tensorflow as tf
from tensorflow.keras.applications import resnet50 #os.environ['CUDA_VISIBLE_DEVICES']='0' physical_devices = tf.config.list_physical_devices('GPU')
print(physical_devices) #os.environ['CUDA_VISIBLE_DEVICES']='0'
tf.config.experimental.set_memory_growth(physical_devices[0], True) #加载预训练模型
model = resnet50.ResNet50(weights='imagenet') #save_model方式保存模型
tf.saved_model.save(model, "resnet/1/")
回过头我们再仔细研究下报错的信息:

其实之所以报错就是因为主机有多块显卡,我们默认进行计算的时候是使用所有的显卡的,但是我们设置set_memory_growth时只为了部分显卡做设定,这样就造成了所要调用的显卡中部分显卡为set_memory_growth模式而部分不是,这样就造成了显卡与显卡之间的模式不已配的问题,因此也就报错了:
ValueError: Memory growth cannot differ between GPU devices
解决这个问题也是简单只要我们把所有用到的显卡模式设置为统一,如果设置set_memory_growth模式就为所有显卡都进行设定,也或者我们指定只使用部分显卡然后对这部分指定的显卡设置set_memory_growth模式。而设定只使用部分显卡的写法为:
os.environ['CUDA_VISIBLE_DEVICES']='0'
os.environ['CUDA_VISIBLE_DEVICES']='0,1'
而且需要知道一点,那就是os.environ['CUDA_VISIBLE_DEVICES']='0'这样的设置必须在调用TensorFlow框架之前声明否则不生效,这样同样会报错,就像上面的对比实验一样。
如下面:
为了方便我们可以直接把os.environ['CUDA_VISIBLE_DEVICES']='0'写在文件的最前面。
===============================================
如果我们想使用多块显卡进行计算,并且想使用set_memory_growth设置,那么我们就需要对这些显卡都进行set_memory_growth模式设置,具体如下代码:
import os
import tensorflow as tf
from tensorflow.keras.applications import resnet50 os.environ['CUDA_VISIBLE_DEVICES']='0,1' physical_devices = tf.config.list_physical_devices('GPU')
print(physical_devices) tf.config.experimental.set_memory_growth(physical_devices[0], True)
tf.config.experimental.set_memory_growth(physical_devices[1], True) #加载预训练模型
model = resnet50.ResNet50(weights='imagenet') #save_model方式保存模型
tf.saved_model.save(model, "resnet/1/")
关键的设置为:
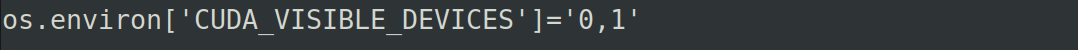

==================================================
【解决】ValueError: Memory growth cannot differ between GPU devices的更多相关文章
- Allowing GPU memory growth
By default, TensorFlow maps nearly all of the GPU memory of all GPUs (subject to CUDA_VISIBLE_DEVICE ...
- 【转】简单内存泄漏检测方法 解决 Detected memory leaks! 问题
我的环境是: XP SP2 . VS2003 最近在一个项目中,程序退出后都出现内存泄漏: Detected memory leaks! Dumping objects -> {98500} n ...
- _CrtSetBreakAlloc简单内存泄漏检测方法,解决Detected memory leaks!问题
我的环境是: XP SP2 . VS2003 最近在一个项目中,程序退出后都出现内存泄漏: Detected memory leaks! Dumping objects -> {98500} n ...
- 【Visual Studio】简单内存泄漏检测方法 解决 Detected memory leaks! 问题(转)
原文转自 http://blog.csdn.net/u011430225/article/details/47840647 我的环境是: XP SP2.VS2003 最近在一个项目中, 程序退出后都出 ...
- [已解决]ValueError: row index was 65536, not allowed by .xls format
报错: ValueError: row index was 65536, not allowed by .xls format 解决方案: xlrd和xlwt处理的是xls文件,单个sheet最大行数 ...
- 吴裕雄--天生自然TensorFlow高层封装:解决ValueError: Invalid backend. Missing required entry : placeholder
找到对应的keras配置文件keras.json 将里面的内容修改为以下就可以了
- cmd 【已解决】windows连接手机,运行adb devices提示“unauthorized”
报错截图如下: 问题原因:电脑连接手机.手机未授权 解决方式: 设置----开发者选项-----打开USB调试,出现如下弹框,点击"确定"即可解决问题.
- Tensorflow2对GPU内存的分配策略
一.问题源起 从以下的异常堆栈可以看到是BLAS程序集初始化失败,可以看到是执行MatMul的时候发生的异常,基本可以断定可能数据集太大导致memory不够用了. 2021-08-10 16:38:0 ...
- 解决TensorFlow程序无限制占用GPU
今天遇到一个奇怪的现象,使用tensorflow-gpu的时候,出现内存超额~~如果我训练什么大型数据也就算了,关键我就写了一个y=W*x.......显示如下图所示: 程序如下: import te ...
- 【Udacity并行计算课程笔记】- Lesson 3 Fundamental GPU Algorithms (Reduce, Scan, Histogram)
本周主要内容如下: 如何分析GPU算法的速度和效率 3个新的基本算法:归约.扫描和直方图(Reduce.Scan.Histogram) 一.评估标准 首先介绍用于评估GPU计算的两个标准: ste ...
随机推荐
- C#.NET与JAVA互通之MD5哈希V2024
C#.NET与JAVA互通之MD5哈希V2024 配套视频: 要点: 1.计算MD5时,SDK自带的计算哈希(ComputeHash)方法,输入输出参数都是byte数组.就涉及到字符串转byte数组转 ...
- Centos7部署FytSoa项目至Docker——第二步:安装Mysql、Redis
FytSoa项目地址:https://gitee.com/feiyit/FytSoaCms 部署完成地址:http://82.156.127.60:8001/ 先到腾讯云申请一年的云服务器,我买的是一 ...
- java8 Lambda 测试示例
import com.google.gson.Gson; import org.junit.Test; import java.util.Arrays; import java.util.IntSum ...
- FreeRTOS简单内核实现6 优先级
0.思考与回答 0.1.思考一 如何实现 RTOS 内核支持多优先级? 因为不支持优先级,所以所有的任务都插入了一个名为 pxReadyTasksLists 的就绪链表中,相当于所有任务的优先级都是一 ...
- Spring之webMvc异常处理
异常处理可以前端处理,也可以后端处理. 从稳妥的角度出发,两边都应该进行处理. 本文专门阐述如何在服务端进行http请求异常处理. 一.常见的异常类型 当我们做http请求的时候,会有各种各样的可能错 ...
- BST-Treap名次树数组&指针实现板子 Ver1.0
这里只有板子没有原理QWQ 可实现 1.插入 x 数 2.删除 x 数(若有多个相同的数,只删除一个) 3.查询 x 数的排名(排名定义为比当前数小的数的个数 +1) 4.查询排名为 x 的数 5.求 ...
- mysql语句大全-工作中常用整理(欢迎大家在评论区继续补充)
1.NOT EXISTS 和 NOT IN SELECT COUNT(ca.aaa) FROM xx ca WHERE NOT EXISTS( SELECT label.* FROM xxx labe ...
- python3 安装pymssql失败 pip3 install pymssql
python3 安装pymssql失败 报错信息: AttributeError: module 'platform' has no attribute 'linux_distribution' 解决 ...
- ComfyUI进阶篇:ComfyUI核心节点(一)
ComfyUI进阶篇:ComfyUI核心节点(一) 前言: 学习ComfyUI是一场持久战.当你掌握了ComfyUI的安装和运行之后,会发现大量五花八门的节点.面对各种各样的工作流和复杂的节点种类,可 ...
- Pluto 轻松构建云应用:开发指南
开发者只需在代码中定义一些变量,Pluto 就能基于这些变量自动创建与管理必要的云资源组件,达到简化部署和管理云基础设施的目的,让开发者更容易使用云. 这里的云资源并非指 IaaS,而是指 BaaS. ...