R包pheatmap:用参数一步步详细绘制热图
经常会想到用热图来展示某个基因或某些基因的表达量问题,今天用R中pheatmap包一步步绘制热图。
第一步:公众路径设置,调用包pheatmap,读取目的文件,查看文件。
1 rm(list=ls())
2 setwd("D:/VIP/ARSTUDYLOCATION/heatmap/heatmap/")
3 getwd()
4
5 library(pheatmap)
6 library(ggplot2)
7
8 data <- read.table("test.FPKM.txt",header=T,row.names=1,sep="\t")
9 dim(data)
10 head(data)
第二步:逐步深入绘制热图(图1-图15)
一建热图(图1)
p<-pheatmap(data)
设置标准化方向scale,对其横向标准化
p<-pheatmap(data,scale="row")
设置边框为白色,横向纵向聚类为无;border="white;cluster_cols = F;cluster_rows = F
p<-pheatmap(data,scale="row",border="white",cluster_cols = F,cluster_rows = F)
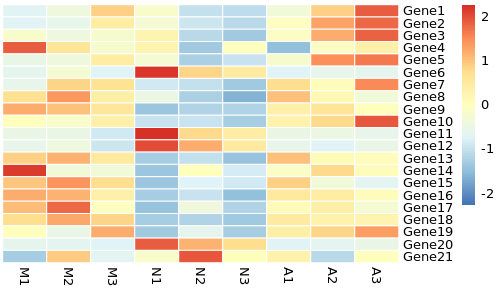
图1
去掉横纵坐标中的id;show_rownames = F,show_colnames = F(图2)
p<-pheatmap(data,scale="row",show_rownames = F,show_colnames = F,border="white",cluster_cols = F,cluster_rows = F)
图2 去掉横轴和纵轴的名称
去掉右上角图例;legend = F(图3)
p<-pheatmap(data,scale="row",show_rownames = F,show_colnames = F,legend = F,border="white",cluster_cols = F,cluster_rows = F)
图3 将右上角的图例去掉
设置右上角图例的范围;legend_breaks=c(-1,1)(图4)
p<-pheatmap(data,scale="row",legend_breaks=c(-1,0,1),show_rownames = F,show_colnames = F,legend = T,border="white",cluster_cols = F,cluster_rows = F)
p<-pheatmap(data,scale="row",legend_breaks=c(-2,0,2),show_rownames = F,show_colnames = F,legend = T,border="white",cluster_cols = F,cluster_rows = F)
图4 更改图例范围
设置图中字的大小;fondsize(图5)
#图表字体:命令:fondsize=2/8
p<-pheatmap(data,scale="row",fontsize = 2,show_rownames = T,show_colnames = T,legend = F,border="white",cluster_cols = F,cluster_rows = F)
p2<-pheatmap(data,scale="row",fontsize = 8,show_rownames = T,show_colnames = T,legend = F,border="white",cluster_cols = F,cluster_rows = F)
图5 设置字的大小
改变横向和纵向字体大小;fontsize_row = 8,fontsize_col=12 (图6)
p<-pheatmap(data,scale="row",fontsize_row = 8,fontsize_col = 12,show_rownames = T,show_colnames = T,legend=T,border="white",cluster_cols = T,cluster_rows = T)
p<-pheatmap(data,scale="row",fontsize_row = 12,fontsize_col = 8,show_rownames = T,show_colnames = T,legend=T,border="white",cluster_cols = T,cluster_rows = T)

图6 改变横向和纵向字体的大小
设置横向纵向的树高;treeheight_col = 20,treeheight_row = 15(图7)
p<-pheatmap(data,scale="row",border="white",cluster_cols = T,treeheight_col = 20,cluster_rows = T,treeheight_row = 15)
p<-pheatmap(data,scale="row",border="white",cluster_cols = T,treeheight_col = 20,cluster_rows = T,treeheight_row = 20)
图7 设置横向和纵向聚类热图的树形高度
R包pheatmap:用参数一步步详细绘制热图的更多相关文章
- pheatmap绘制“热图”,你需要的都在这
热图可以聚合大量的数据,并可以用一种渐进色来优雅地表现,可以很直观地展现数据的疏密程度或频率高低. 本文利用R语言 pheatmap 包从头开始绘制各种漂亮的热图.参数像积木,拼凑出你最喜欢的热图即可 ...
- 用R包中heatmap画热图
一:导入R包及需要画热图的数据 library(pheatmap) data<- read.table("F:/R练习/R测试数据/heatmapdata.txt",head ...
- R语言学习 - 热图简化
绘制热图除了使用ggplot2,还可以有其它的包或函数,比如pheatmap::pheatmap (pheatmap包中的pheatmap函数).gplots::heatmap.2等. 相比于gg ...
- [R] 如何绘制各样本的pathway丰度热图?
前言 一般而言,我们做完pathway富集分析,就做下气泡图或bar图来进行展示,但它们实际上只考虑了富集因子和Pvalue.如果我们不关注这两个因素,而是在乎样本本身的pathway丰度呢? 对于K ...
- 在 R 中估计 GARCH 参数存在的问题(基于 rugarch 包)
目录 在 R 中估计 GARCH 参数存在的问题(基于 rugarch 包) 导论 rugarch 简介 指定一个 \(\text{GARCH}(1, 1)\) 模型 模拟一个 GARCH 过程 拟合 ...
- 如何创建R包并将其发布在 CRAN / GitHub 上--转载
转载--https://www.analyticsvidhya.com/blog/2017/03/create-packages-r-cran-github/ 什么是 R 包?我开始创建 R 包的原因 ...
- Linux 安装R包
https://www.cnblogs.com/jessepeng/p/10984983.html Linux 的R环境,可以通过anaconda jupyter notbook很容易的配置,见我之前 ...
- Linux环境下R和R包安装及其管理
前言 R对windows使用很友好,对Linux来说充满了敌意.小数据可以在windows下交互操作,效果很好很棒.可是当我们要处理大数据,或者要在集群上搭建pipeline时,不得不面对在Linux ...
- R包介绍
R语言的使用,很大程度上是借助各种各样的R包的辅助,从某种程度上讲,R包就是针对于R的插件,不同的插件满足不同的需求,截至2013年3月6日,CRAN已经收录了各类包4338个. 一. R语言包的安装 ...
- R(三): R包原理及安装
包(package)是多个函数的集合,常作为分享代码的基本单元,代码封装成包可以方便其他用户使用.越来越多的R包正在由世界上不同的人所创建并分发,这些分发的R包,可以从CRAN 或 github 上获 ...
随机推荐
- Ajax分析方法
Ajax 分析方法 以前面的微博为例,拖动刷新的内容由 Ajax 加载,而且页面的 URL 没有变化,那么应该到哪里去查看这些 Ajax 请求呢? 查看请求 需要借助浏览器的开发者工具,下面以 Chr ...
- linux下安装oracle 11g(静默安装)
关闭selinux 关闭防火墙 检查安装依赖包 yum -y install binutils compat-libcap1 vsftpd gcc gcc-c++ glibc-devel glibc ...
- Java面试知识点(五)hashmap、hashtable和hashset
1. 关于 HashMap 的一些说法: a) HashMap 实际上是一个 "链表散列" 的数据结构,即数组和链表的结合体.HashMap 的底层结构是一个数组,数组中的每一项是 ...
- Redis常见的16个使用场景
1.缓存 String类型 例如:热点数据缓存(例如报表.明星出轨),对象缓存.全页缓存.可以提升热点数据的访问数据. 2.数据共享分布式 String 类型,因为 Redis 是分布式的独立服务,可 ...
- mac svn管理工具
App Store中搜索snailsvn 分付费(98元)和免费试用
- tp5.1--数据库事务操作
https://blog.csdn.net/qq_42176520/article/details/88708395 使用事务处理的话,需要数据库引擎支持事务处理.比如 MySQL 的 MyISAM ...
- [oeasy]python0135_python_语义分析_ast_抽象语法树_abstract_syntax_tree
语义分析_抽象语法树_反汇编 回忆 上次回顾了一下历史 python 是如何从无到有的 看到 Guido 长期的坚持和努力 添加图片注释,不超过 140 字(可选) python究竟是 ...
- 阅读翻译Mathematics for Machine Learning之2.8 Affine Subspaces
阅读翻译Mathematics for Machine Learning之2.8 Affine Subspaces 关于: 首次发表日期:2024-07-24 Mathematics for Mach ...
- 在英特尔 Gaudi 2 上加速蛋白质语言模型 ProtST
引言 蛋白质语言模型 (Protein Language Models, PLM) 已成为蛋白质结构与功能预测及设计的有力工具.在 2023 年国际机器学习会议 (ICML) 上,MILA 和英特尔实 ...
- python selenium元素定位
1.ID元素定位基于元素属性中的id的值来进行定位,id是一个标签的唯一属性值可以通过id属性来唯一定位一个元素,是首选的元素定位方式,动态ID不做考虑.driver .find_element_by ...