代码随想录Day9
KMP算法
主要用来进行字符串匹配
KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
所以如何记录已经匹配的文本内容,是KMP的重点,也是next数组肩负的重任。
next数组就是一个前缀表(prefix table)。
前缀表有什么作用呢?
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
此时就要问了前缀表是如何记录的呢?
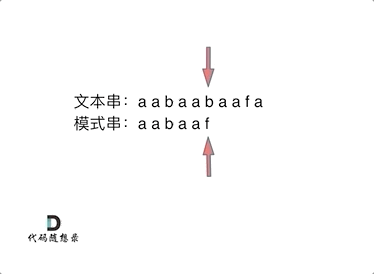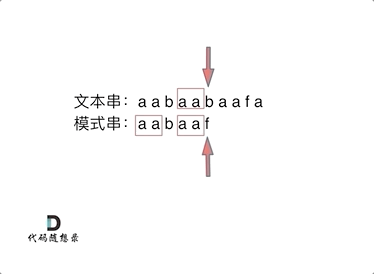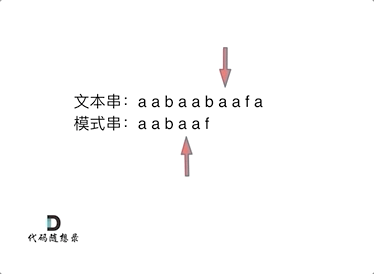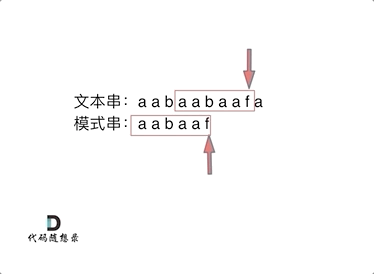
首先要知道前缀表的任务是当前位置匹配失败,找到之前已经匹配上的位置,再重新匹配,此也意味着在某个字符失配时,前缀表会告诉你下一步匹配中,模式串应该跳到哪个位置。
那么什么是前缀表:记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面重新匹配就可以了。
所以前缀表具有告诉我们当前位置匹配失败,跳到之前已经匹配过的地方的能力。
很多KMP算法的实现都是使用next数组来做回退操作,那么next数组与前缀表有什么关系呢?
next数组就可以是前缀表,但是很多实现都是把前缀表统一减一(右移一位,初始位置为-1)之后作为next数组。
其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
暴力的解法显而易见是O(n × m),所以KMP在字符串匹配中极大地提高了搜索的效率。
28.实现strStr()
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例 1:
输入:haystack = "sadbutsad", needle = "sad"
输出:0
解释:"sad" 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。
示例 2:
输入:haystack = "leetcode", needle = "leeto"
输出:-1
解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。
提示:
1 <= haystack.length, needle.length <= 104
haystack 和 needle 仅由小写英文字符组成
正解(KMP)
显然,是一道KMP模板题
上代码(●'◡'●)
class Solution {
public:
void getNext(int* next, const string& s) {
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}
int strStr(string haystack, string needle) {
if (needle.size() == 0) {
return 0;
}
vector<int> next(needle.size());
getNext(&next[0], needle);
int j = -1; // // 因为next数组里记录的起始位置为-1
for (int i = 0; i < haystack.size(); i++) { // 注意i就从0开始
while(j >= 0 && haystack[i] != needle[j + 1]) { // 不匹配
j = next[j]; // j 寻找之前匹配的位置
}
if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动
j++; // i的增加在for循环里
}
if (j == (needle.size() - 1) ) { // 文本串s里出现了模式串t
return (i - needle.size() + 1);
}
}
return -1;
}
};
459.重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
示例 1:
输入: s = "abab"
输出: true
解释: 可由子串 "ab" 重复两次构成。
示例 2:
输入: s = "aba"
输出: false
示例 3:
输入: s = "abcabcabcabc"
输出: true
解释: 可由子串 "abc" 重复四次构成。 (或子串 "abcabc" 重复两次构成。)
提示:
1 <= s.length <= 104
s 由小写英文字母组成
正解(依旧是KMP)
当一个字符串s:abcabc,内部由重复的子串组成
也就是由前后相同的子串组成。
那么既然前面有相同的子串,后面有相同的子串,用 s + s,这样组成的字符串中,后面的子串做前串,前面的子串做后串,就一定还能组成一个s;
所以判断字符串s是否由重复子串组成,只要两个s拼接在一起,里面还出现一个s的话,就说明是由重复子串组成。
当然,我们在判断 s + s 拼接的字符串里是否出现一个s的的时候,要刨除 s + s 的首字符和尾字符;
这样避免在s+s中搜索出原来的s,我们要搜索的是中间拼接出来的s。
上代码(●'◡'●)
class Solution {
public:
void getNext (int* next, const string& s){
next[0] = -1;
int j = -1;
for(int i = 1;i < s.size(); i++){
while(j >= 0 && s[i] != s[j + 1]) {
j = next[j];
}
if(s[i] == s[j + 1]) {
j++;
}
next[i] = j;
}
}
bool repeatedSubstringPattern (string s) {
if (s.size() == 0) {
return false;
}
int next[s.size()];
getNext(next, s);
int len = s.size();
if (next[len - 1] != -1 && len % (len - (next[len - 1] + 1)) == 0) {
return true;
}
return false;
}
};
写博不易,请大佬点赞支持一下8~
代码随想录Day9的更多相关文章
- 代码随想录第十三天 | 150. 逆波兰表达式求值、239. 滑动窗口最大值、347.前 K 个高频元素
第一题150. 逆波兰表达式求值 根据 逆波兰表示法,求表达式的值. 有效的算符包括 +.-.*./ .每个运算对象可以是整数,也可以是另一个逆波兰表达式. 注意 两个整数之间的除法只保留整数部分. ...
- 代码随想录第八天 |344.反转字符串 、541. 反转字符串II、剑指Offer 05.替换空格 、151.翻转字符串里的单词 、剑指Offer58-II.左旋转字符串
第一题344.反转字符串 编写一个函数,其作用是将输入的字符串反转过来.输入字符串以字符数组 s 的形式给出. 不要给另外的数组分配额外的空间,你必须原地修改输入数组.使用 O(1) 的额外空间解决这 ...
- 代码随想录-day1
链表 今天主要是把链表专题刷完了,链表专题的题目不是很难,基本都是考察对链表的操作的理解. 在处理链表问题的时候,我们通常会引入一个哨兵节点(dummy),dummy节点指向原链表的头结点.这样,当我 ...
- 代码随想录 day0 博客怎么写
前言 2.25日开始记录自己的博客生涯以及代码随想录训练营的每日内容 一.题目链接怎么找?怎么设置连接? 力扣题目链接1:力扣 二.正文怎么写? 二分查找 算法思路: 二分查找需要保证数组为有序数组同 ...
- 【LeetCode动态规划#05】背包问题的理论分析(基于代码随想录的个人理解,多图)
背包问题 问题描述 背包问题是一系列问题的统称,具体包括:01背包.完全背包.多重背包.分组背包等(仅需掌握前两种,后面的为竞赛级题目) 下面来研究01背包 实际上即使是最经典的01背包,也不会直接出 ...
- 代码随想录第七天| 454.四数相加II、383. 赎金信 、15. 三数之和 、18. 四数之和
第一题454.四数相加II 给你四个整数数组 nums1.nums2.nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 <= i, ...
- 代码随想录算法训练营day22 | leetcode 235. 二叉搜索树的最近公共祖先 ● 701.二叉搜索树中的插入操作 ● 450.删除二叉搜索树中的节点
LeetCode 235. 二叉搜索树的最近公共祖先 分析1.0 二叉搜索树根节点元素值大小介于子树之间,所以只要找到第一个介于他俩之间的节点就行 class Solution { public T ...
- 代码随想录算法训练营day17 | leetcode ● 110.平衡二叉树 ● 257. 二叉树的所有路径 ● 404.左叶子之和
LeetCode 110.平衡二叉树 分析1.0 求左子树高度和右子树高度,若高度差>1,则返回false,所以我递归了两遍 class Solution { public boolean is ...
- 代码随想录算法训练营day13
基础知识 二叉树基础知识 二叉树多考察完全二叉树.满二叉树,可以分为链式存储和数组存储,父子兄弟访问方式也有所不同,遍历也分为了前中后序遍历和层次遍历 Java定义 public class Tree ...
- 代码随想录算法训练营day10 | leetcode 232.用栈实现队列 225. 用队列实现栈
基础知识 使用ArrayDeque 实现栈和队列 stack push pop peek isEmpty() size() queue offer poll peek isEmpty() size() ...
随机推荐
- HBCK2修复hbase2的常见场景
上一文章已经把HBCK2 怎么在小于hbase2.0.3版本的编译与用法介绍了,解决主要场景 查看hbase存在的问题 一.使用hbase hbck命令 hbase hbck命令是对hbase的元数据 ...
- 又跳槽!3年java经验offer收割机的面试心得
中厂->阿里->字节,成都->杭州->成都 系列文章目录和关于我 0.前言 笔者在不足两年经验的时候从成都一家金融科技中厂跳槽到杭州阿里淘天集团,又于今年5月份从杭州淘天跳槽到 ...
- WPS中导入endnote插件
WPS中导入endnote插件 1. 找到 Endnote 插件的目录: D:\Program Files (x86)\EndNote 20\Product-Support\CWYW 2. 把Cw ...
- UG二次开发 PYTHON 环境配置
NX 二次开发 PYTHON VSCODE 环境配置 我电脑上装的是WIN11 NX1988 在电脑的UG的安装文件夹内找到 python 一般在 xx\NXBIN 在所在的文件夹内,运行python ...
- MyBatis学习篇
什么是MyBatis (1)Mybatis是一个半ORM(对象关系映射)框架,它内部封装了JDBC,开发时只需要关注SQL语句本身,不需要花费精力去处理加载驱动.创建连接.创建statement等繁杂 ...
- 阿里云Centos7 安装mysql5.7 报错:./mysqld: error while loading shared libraries: libaio.so.1: cannot open shared object file: No such file or directory
在阿里云服务器Centos7中安装mysql5.7,解压数据库初始化后,报错 ./mysqld: error while loading shared libraries: libaio.so.1: ...
- Django 自定义装饰器解决MySQL server has gone away错误
Django 自定义装饰器解决MySQL server has gone away错误 by:授客 QQ:1033553122 测试环境 Win 10 Python 3.5.4 Django- ...
- ngnix简介和基础
一.Nginx简介 Nginx 是一个高性能的HTTP和反向代理服务器,同时也是一个IMAP/POP3/SMTP代理服务器 是一个模块化软件 [1].安装nginx 使用源码包编译安装 cd /opt ...
- 搭建lnmp环境-redis(第四步)
1.下载epel仓库 (前面安装过了) yum install epel-release -y 2.下载redis数据库 yum install redis -y 3.启动redis服务 system ...
- 支付宝小程序的级联选择器,对接简单操作,Cascader 级联选择器element_ui
首先,对于element_ui 的动接,由于需要数据格式是 但是支付宝提的接口返回的数据是另一种格式,并且支付宝的三级联动接口是先只有一个列表,点击列表项再发现请求,生成另外一个下拉选择, 需要这个三 ...