HTML转为PDF,图片导出失败的终极解决方案
如题项目有需求将一个页面导出为pdf,然而页面中的图片却始终无法导出成功
文章目录
一、导出的方法
查询了许多大佬的帖子,找到了如下导出的方法
const PdfDownload = function(domId) {
var targetDom = $('#'+domId)
// 把需要导出的pdf内容clone一份,这样对它进行转换、微调等操作时才不会影响原来界面
var copyDom = targetDom.clone()
// 新的div宽高跟原来一样,高度设置成自适应,这样才能完整显示节点中的所有内容(比如说表格滚动条中的内容)
copyDom.width(targetDom.width() + 'px')
copyDom.height(targetDom.height()+200 + 'px')
$('body').append(copyDom)// ps:这里一定要先把copyDom append到body下,然后再进行后续的glyphicons2canvas处理,不然会导致图标为空
// svg2canvas(copyDom)
// loadImg(copyDom)
html2canvas(copyDom, {
onrendered: function(canvas) {
var imgData = canvas.toDataURL('image/jpeg')
var img = new Image()
img.src = imgData
// 根据图片的尺寸设置pdf的规格,要在图片加载成功时执行,之所以要*0.225是因为比例问题
img.onload = function() {
// 此处需要注意,pdf横置和竖置两个属性,需要根据宽高的比例来调整,不然会出现显示不完全的问题
if (this.width > this.height) {
var doc = new jsPDF('l', 'mm', [this.width * 0.225, this.height * 0.225])
} else {
var doc = new jsPDF('p', 'mm', [this.width * 0.225, this.height * 0.225])
}
doc.addImage(imgData, 'jpeg', 0, 0, this.width * 0.225, this.height * 0.225)
// 根据下载保存成不同的文件名
doc.save('pdf_' + new Date().getTime() + '.pdf')
}
// 删除复制出来的div
copyDom.remove()
},
background: '#FFF',
// 这里给生成的图片默认背景,不然的话,如果你的html根节点没设置背景的话,会用黑色填充。
allowTaint: true // 避免一些不识别的图片干扰,默认为false,遇到不识别的图片干扰则会停止处理html2canvas
})
}
二、初步测试的结果
有了上面的方法当然迫不及待的进行测试-- 测试导出页面如下
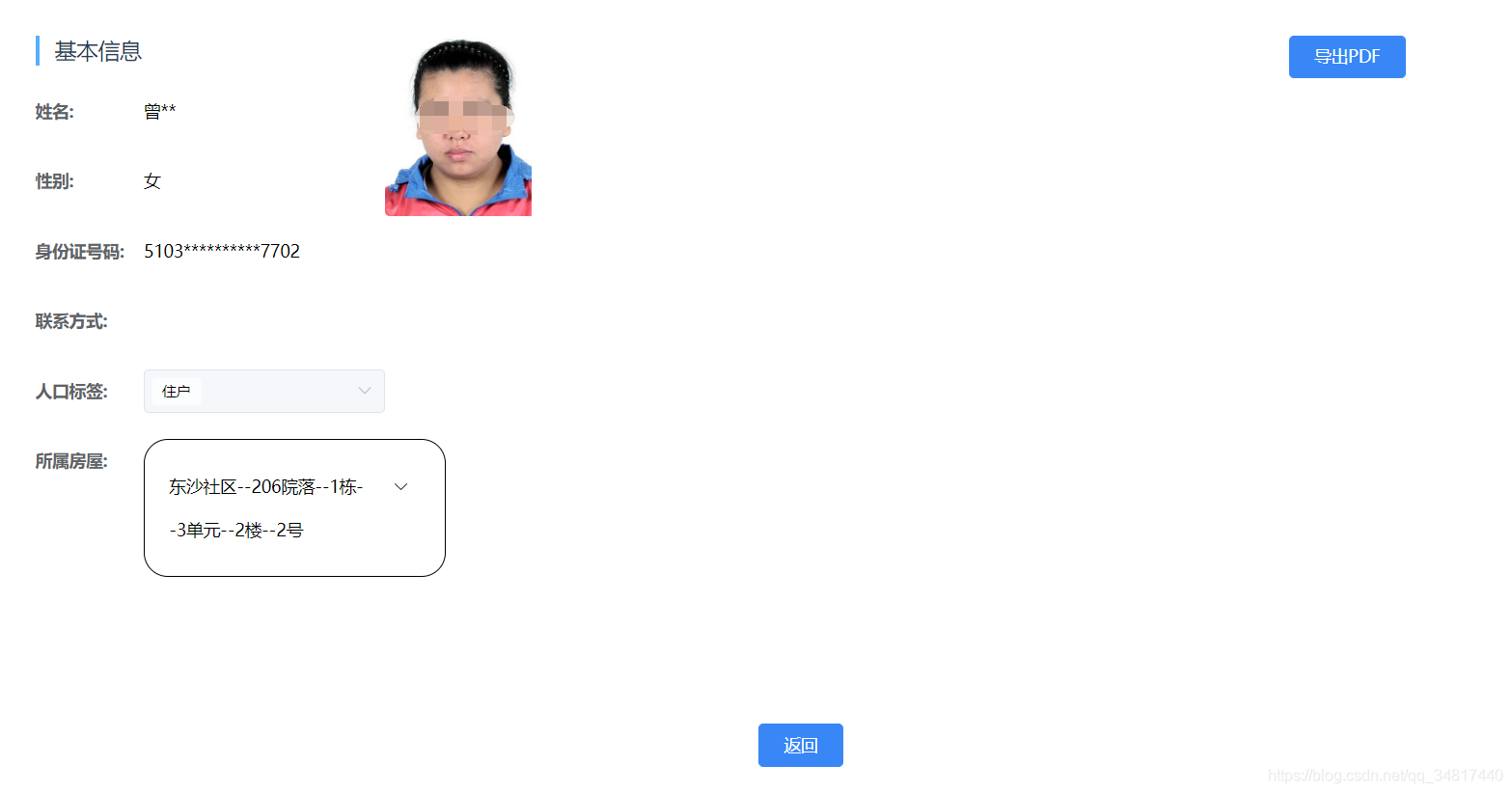
导出成功结果如下
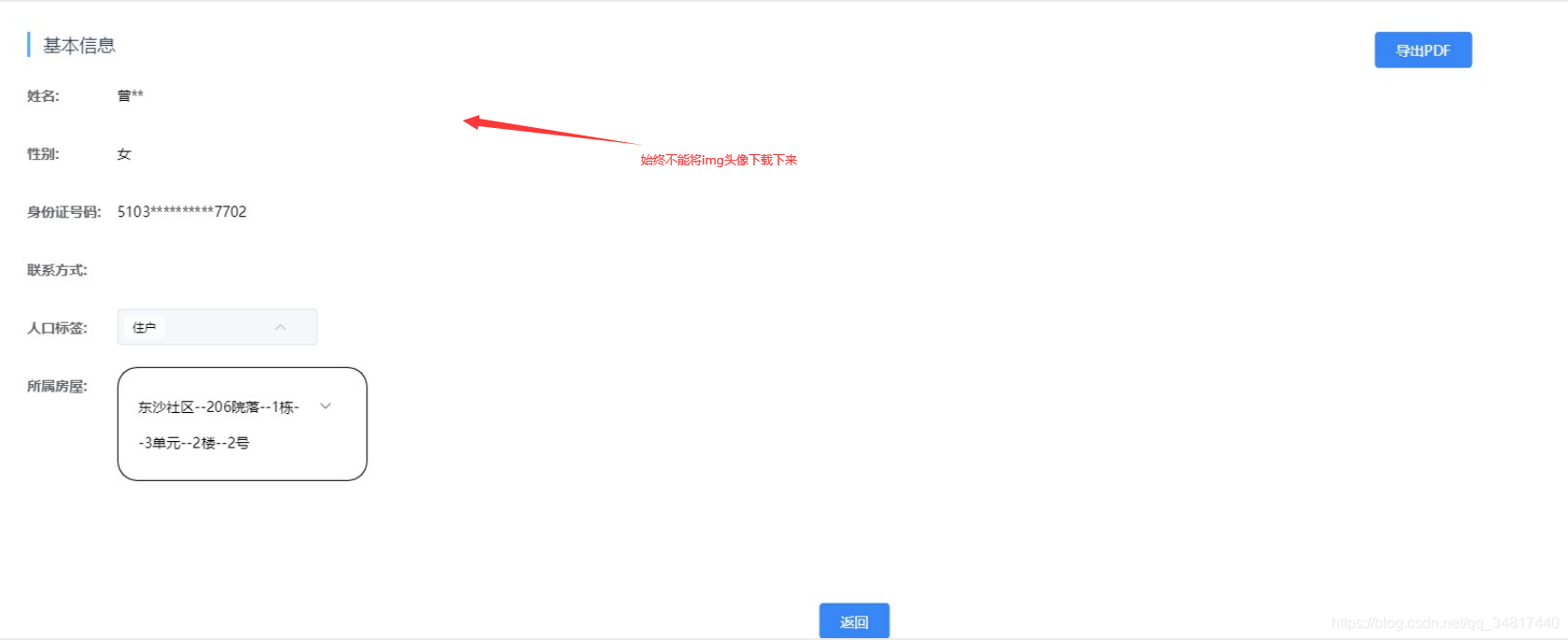
这一测试发现并没有得到自己期望的结果,页面大致导出成功了,可是页面原本的头像图片怎么就没导出来呢?
三、使用f12查找原油
打开浏览器使用另一个用户进行测试发现… 该用户没有上传头像,我默认加载了一张本地的图片作为用户默认头像
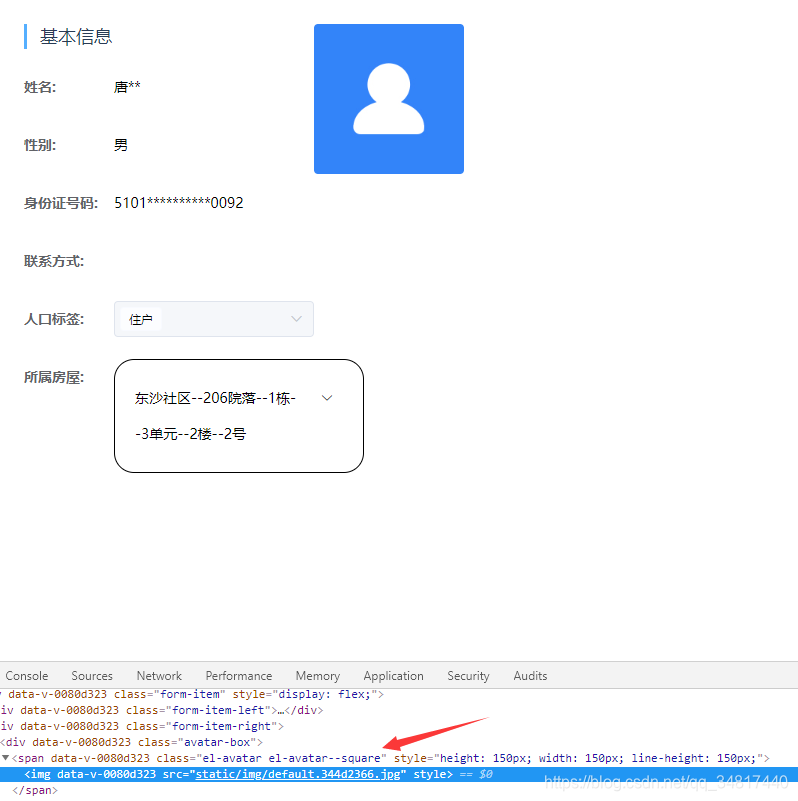
而加载为默认图片的页面使用jsPdf将其进行导出,这个头像图片就可以成功被下载下来
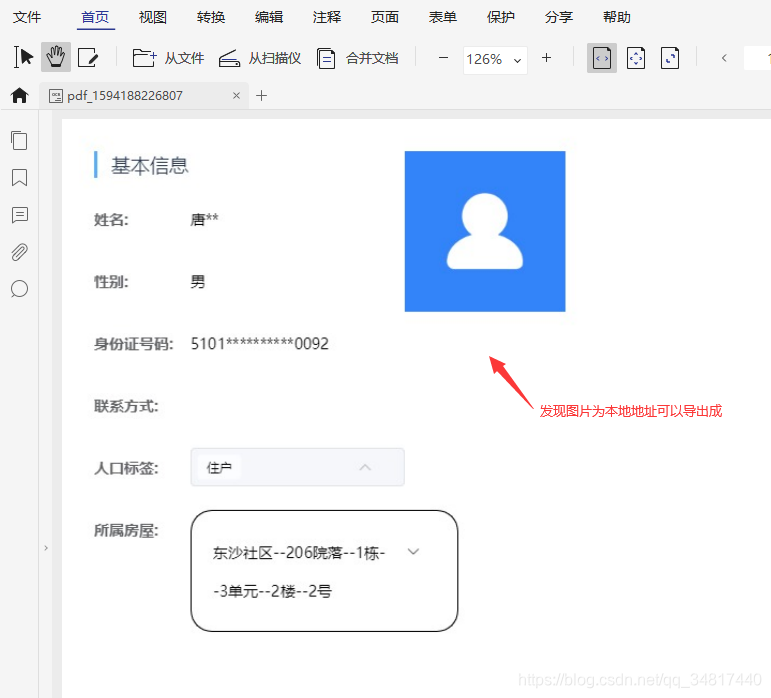
于是做出如下推测…
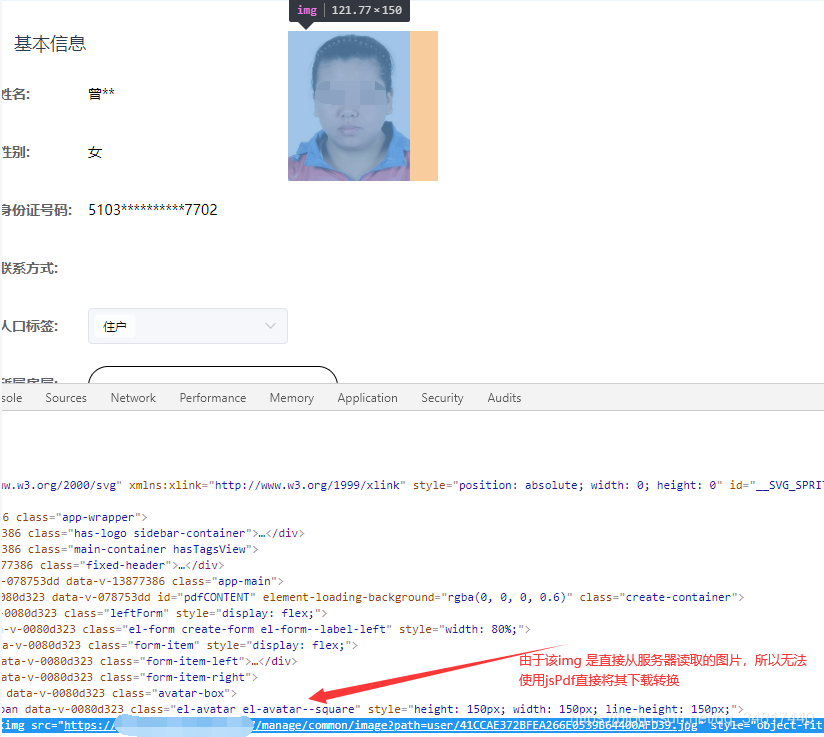
经过这一测试初步断定是js 中同源策略所引起的跨域请求图片,所导致的jsPdf读取页面中图片失败的问题
四、方案一
到目前,问题虽然初步已锁定,但是还没有切实可行的解决方案,这咋办?
首先想到:就是把图片从服务器下载到本地
于是想到了使用nodeJS http+fs 从服务器将文件下载,然后将其写入到本地文件夹中
如参考 https://www.jianshu.com/p/28e3de79fd49
var http = require(''http'),fs = require('fs');
http.get(path,function(req,res){ //path为网络图片地址
var imgData = '';
req.setEncoding('binary');
req.on('data',function(chunk){
imgData += chunk
})
req.on('end',function(){
fs.writeFile(path,imgData,'binary',function(err){ //path为本地路径例如public/logo.png
if(err){console.log('保存出错!')}else{
console.log('保存成功!')
}
})
})
})
再重新 为节点添加一个img 标签,将其url指定为刚才下载的文件地址,在pdf 下载完成后再使用
如下方法将其删除掉 参考 https://blog.csdn.net/dongmelon/article/details/102456717
var fs = require('fs')
/**
*
* @param {*} path 必传参数可以是文件夹可以是文件
* @param {*} reservePath 保存path目录 path值与reservePath值一样就保存
*/
function delFile(path, reservePath) {
if (fs.existsSync(path)) {
if (fs.statSync(path).isDirectory()) {
let files = fs.readdirSync(path);
files.forEach((file, index) => {
let currentPath = path + "/" + file;
if (fs.statSync(currentPath).isDirectory()) {
delFile(currentPath, reservePath);
} else {
fs.unlinkSync(currentPath);
}
});
if (path != reservePath) {
fs.rmdirSync(path);
}
} else {
fs.unlinkSync(path);
}
}
}
后来经测试,很显然这个想法很幼稚(浏览器如何使用nodeJS?), 最终测试这种方法是不可行的!
五、方案二
使用canvas 根据图片url重新将图片绘制然后进行下载
参考https://www.jb51.net/article/128554.htm
/**
*
* 查询目标容器中images
* 使用nodejs进行图片下载到本地
* 增加一个image 使用本地src
* @param targetElem {Element object}
*/
function loadImg(targetElem){ var svgElem = targetElem.find('img')
svgElem.each(function(index, node) {
var parentNode = node.parentNode
//通过构造函数来创建的 img 实例,在赋予 src 值后就会立刻下载图片,相比 createElement() 创建 <img> 省去了 append(),也就避免了文档冗余和污染
var Img = new Image(),
dataURL='';
Img.src=url;
Img.onload=function(){ //要先确保图片完整获取到,这是个异步事件
var canvas = document.createElement("canvas"), //创建canvas元素
width=Img.width, //确保canvas的尺寸和图片一样
height=Img.height;
canvas.width=width;
canvas.height=height;
canvas.getContext("2d").drawImage(Img,0,0,width,height); //将图片绘制到canvas中
dataURL=canvas.toDataURL('image/jpeg'); //转换图片为dataURL
}; parentNode.appendChild(canvas)
})
}
后来又遇到了Uncaught SecurityError: Failed to execute 'toDataURL' on 'HTMLCanvasElement': Tainted canvases may not be exported.
根据资料https://blog.csdn.net/u013040887/article/details/78986598 在方法中新增node.setAttribute('crossOrigin', 'anonymous'); 遗憾的是最后并未成功解决问题,依然需要重新寻找新的解决方案…
六、方案三
然后想到了使用XMLHttpRequest先把图片下载回来再重新为img 赋值
于是 增加如下方法使用 xmlHttpRequest进行图片下载
function downloadByXmlhttprequest(imgDom,cb){
var xhr = new XMLHttpRequest()
xhr.onreadystatechange = function () {
var blob
if(xhr.readyState === 4){
// 使用URL.createObjectURL将Blob对象转换为可访问的url地址
var src = URL.createObjectURL(xhr.response)
console.log(src)
imgDom.src = src
cb(src)
}
}
xhr.open('GET',imgDom.src, true)
// 设置响应数据格式为Blob对象
xhr.responseType = 'blob'
// 设置请求头
xhr.setRequestHeader('X-Requested-With', 'OpenAPIRequest')
xhr.send()
}
参考https://blog.csdn.net/weixin_34384915/article/details/91756646
但是其中又遇到了请求未携带cookie而失败问题
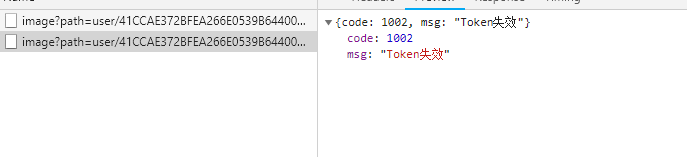
后来参照 https://blog.csdn.net/u011674895/article/details/83932461解决token失效问题

在方法中添加如下代码
xhr.withCredentials = true;
最终经过如下多次测试,终于成功了
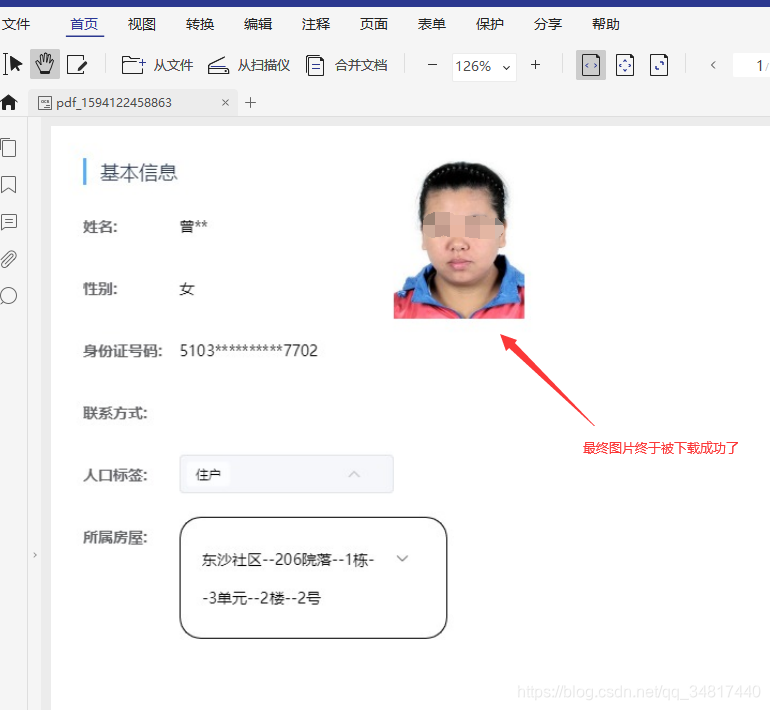
七、完整代码
最后完成这些操作的完整代码(这里我是写了一个外部js)如下
1、使用XMLHttpRequest进行图片二次下载
/**
* 使用XMLHttpRequest进行图片二次下载
* @param imgDom {Objec} target object
* @param cb{Object}success callback
*/
function downloadByXmlhttprequest(imgDom,cb){ var xhr = new XMLHttpRequest() xhr.onreadystatechange = function () {
if(xhr.readyState === 4){ // 使用URL.createObjectURL将Blob对象转换为可访问的url地址
var src = URL.createObjectURL(xhr.response)
imgDom.src = src
cb(src)
}
} xhr.open('GET',imgDom.src, true)
xhr.withCredentials = true;
// 设置响应数据格式为Blob对象
xhr.responseType = 'blob' // 设置请求头
xhr.setRequestHeader('X-Requested-With', 'OpenAPIRequest') xhr.send()
}
2、转换页面的图片
function imgConvert(targetElem,cb){
var svgElem = targetElem.find('img')
svgElem.each(function(index, node) {
var parentNode = node.parentNode
downloadByXmlhttprequest(node,cb)
})
}
3、html2canvas执行下载
function executeDown(copyDom){
html2canvas(copyDom, {
onrendered: function(canvas) {
var imgData = canvas.toDataURL('image/jpeg')
var img = new Image()
img.src = imgData
// 根据图片的尺寸设置pdf的规格,要在图片加载成功时执行,之所以要*0.225是因为比例问题
img.onload = function() {
// 此处需要注意,pdf横置和竖置两个属性,需要根据宽高的比例来调整,不然会出现显示不完全的问题
if (this.width > this.height) {
var doc = new jsPDF('l', 'mm', [this.width * 0.225, this.height * 0.225])
} else {
var doc = new jsPDF('p', 'mm', [this.width * 0.225, this.height * 0.225])
}
doc.addImage(imgData, 'jpeg', 0, 0, this.width * 0.225, this.height * 0.225)
// 根据下载保存成不同的文件名
doc.save('pdf_' + new Date().getTime() + '.pdf')
}
// 删除复制出来的div
copyDom.remove()
},
background: '#FFF',
// 这里给生成的图片默认背景,不然的话,如果你的html根节点没设置背景的话,会用黑色填充。
allowTaint: true // 避免一些不识别的图片干扰,默认为false,遇到不识别的图片干扰则会停止处理html2canvas
})
}
4、供外部调用的导出方法
const PdfDownload = function(domId) {
var targetDom = $('#'+domId)
// 把需要导出的pdf内容clone一份,这样对它进行转换、微调等操作时才不会影响原来界面
var copyDom = targetDom.clone()
// 新的div宽高跟原来一样,高度设置成自适应,这样才能完整显示节点中的所有内容(比如说表格滚动条中的内容)
copyDom.width(targetDom.width() + 'px')
copyDom.height(targetDom.height()+200 + 'px')
$('body').append(copyDom)// ps:这里一定要先把copyDom append到body下,然后再进行后续的glyphicons2canvas处理,不然会导致图标为空
// svg2canvas(copyDom)
// loadImg(copyDom)
imgConvert(copyDom,function(res){
executeDown(copyDom)
})
}
export { PdfDownload }
最后这里使用到的 html2canvas-0.4.1 , jquery-2.1.4.min , jspdf.min 如下
插件网盘https://pan.baidu.com/s/1MMNOjmU8H3ebmWdB5nBzqw 提取码 jg7q
HTML转为PDF,图片导出失败的终极解决方案的更多相关文章
- asp.net mvc3.0安装失败之终极解决方案
安装失败截图 原因分析 因为vs10先安装了sp1补丁,然后安装的mvc3.0,某些文件被sp1补丁更改,导致“VS10-KB2483190-x86.exe”安装不了,造成安装失败. 解决方案 方法1 ...
- 应用程序正常初始化(0xc0150002)失败的终极解决方案
转自VC错误:http://www.vcerror.com/?p=62 最近做一个项目写了一个VC6下的MFC程序,结果传到别人的机子上(WIN7)出现了应用程序正常初始化(0xc0150002)失败 ...
- 前端axios请求二进制数据流转换生成PDF文件空白问题(终极解决方案)
本文章共1570字,预计阅读时间1 - 3分钟. 问题场景: axios请求二进制数据转换生成PDF空白问题,使用axios请求后端接口,后端返回的二进制流文件,需要转换成PDF,但是在postman ...
- flying-saucer + iText + Freemarker实现pdf的导出, 支持中文、css以及图片
前言 项目中有个需求,需要将合同内容导出成pdf.上网查阅到了 iText , iText 是一个生成PDF文档的开源Java库,能够动态的从XML或者数据库生成PDF,同时还可以对文档进行加密,权限 ...
- 解决pdf打印预览中遇到特殊字符,导出失败问题
本博客是自己在学习和工作途中的积累与总结,仅供自己参考,也欢迎大家转载,转载时请注明出处. 由于近日由于pdf中存在特殊字符导致导出失败,主要原因是"&"字符与freema ...
- 自动化将 word 转为 pdf,再将pdf转为图片!
参考: https://blog.csdn.net/ynyn2013/article/details/49120731 https://www.jianshu.com/p/f57cc64b9f5e 一 ...
- 个人永久性免费-Excel催化剂功能第54波-批量图片导出,调整大小等
图片作为一种数据存在,较一般的存放在Excel单元格或其他形式存在的文本数据,对其管理更为不易,特别是仅有Excel原生的简单的插入图片功能时,Excel催化剂已全面覆盖图片数据的使用场景,无论是图片 ...
- 把上传过来的多张图片拼接转为PDF的实现代码
以下是把上传过来的多张图片拼接转为PDF的实现代码,不在本地存储上传上来的图片,下面是2中做法,推荐第一种,把pdf直接存储到DB中比较安全. 如果需要在服务器上存储客户端上传的文件时,切记存储文件时 ...
- 使用OpenOffice.org将各类文档转为PDF
http://blog.zhaojie.me/2010/05/convert-document-to-pdf-via-openoffice.html ————————————————————————— ...
- Echarts导出为pdf echarts导出图表(包含背景)
Echarts好像是只支持png和jpg的导出,不支持pdf导出.我就想着只能够将png在后台转为pdf了. 首先介绍一下jsp界面的代码. var thisChart = echarts.init( ...
随机推荐
- 机器学习(二):感知机+svm习题 感知机手工推导参数更新 svm手推求解二维坐标超平面直线方程
作业1: 输入: 训练数据集 \(T = {(x1; y1); (x2; y2),..., (xN; yN)}\) 其中,\(x \in R^n\), \(y \in Y = \{+1, -1\}\) ...
- Mysql 事务隔离级别和锁的关系
我们都知道事务的几种性质,数据库为了维护这些性质,尤其是一致性和隔离性,一般使用加锁这种方式.同时数据库又是个高并发的应用,同一时间会有大量的并发访问,如果加锁过度,会极大的降低并发处理能力.所以对于 ...
- win10计划任务程序库实现定时任务的自动执行程序及问题解决。
win10计划任务程序库可以实现按照规则频率执行脚本的功能.现在将设置方法记录如下: 创建任务步骤 1.右键点击我的电脑,选择管理,依次点击:系统工具->任务计划程序->任务计划程序库. ...
- LeeCode 319周赛复盘
T1: 温度转换 思路:模拟 public double[] convertTemperature(double celsius) { return new double[]{celsius + 27 ...
- Git提交代码仓库的两种方式
目录 一: 两种本地与远程仓库同步 1 git 远程仓库 提交本地版本库操作 提交到远程版本库操作 1.Git 全局设置: 2.增加一个远程仓库地址 3.查询当前存在的远程仓库 5.本地版本库内容提交 ...
- mysql 清空数据表id 重1开始 帝国cms清空数据表id 重1开始
alter table phome_ecms_news auto_increment=1; alter table phome_ecms_news_check auto_increment=1; al ...
- PHPCMSV9 单文件上传功能代码
后台有"多文件上传"功能,但是对于有些情况,我们只需要上传一个文件,而使用多文件上传功能上传一个文件,而调用时调用一个文件太麻烦了. 所以我就自己动手,参考其他字段类型的网站,研究 ...
- Python if 语句练习
if语句 练习 # 1.以特殊方式跟管理员打招呼 # 创建一个至少包含 5 个用户名的列表,且其中一个用户名为 'admin' .想象你要编写代码,在每位用户登录网站后都打印一条问 # 候消息.遍历用 ...
- 【性能】JDK和Jmeter的安装与配置
一.JDK环境配置 1. 下载JDK 官网下载地址:http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downl ...
- abp(net core)+easyui+efcore实现仓储管理系统——供应商管理升级之上(六十三)
abp(net core)+easyui+efcore实现仓储管理系统目录 abp(net core)+easyui+efcore实现仓储管理系统--ABP总体介绍(一) abp(net core)+ ...