【python爬虫案例】用python爬豆瓣音乐TOP250排行榜!
一、爬虫对象-豆瓣音乐TOP250
今天我们分享一期python爬虫案例讲解。爬取对象是,豆瓣音乐TOP250排行榜数据:https://music.douban.com/top250
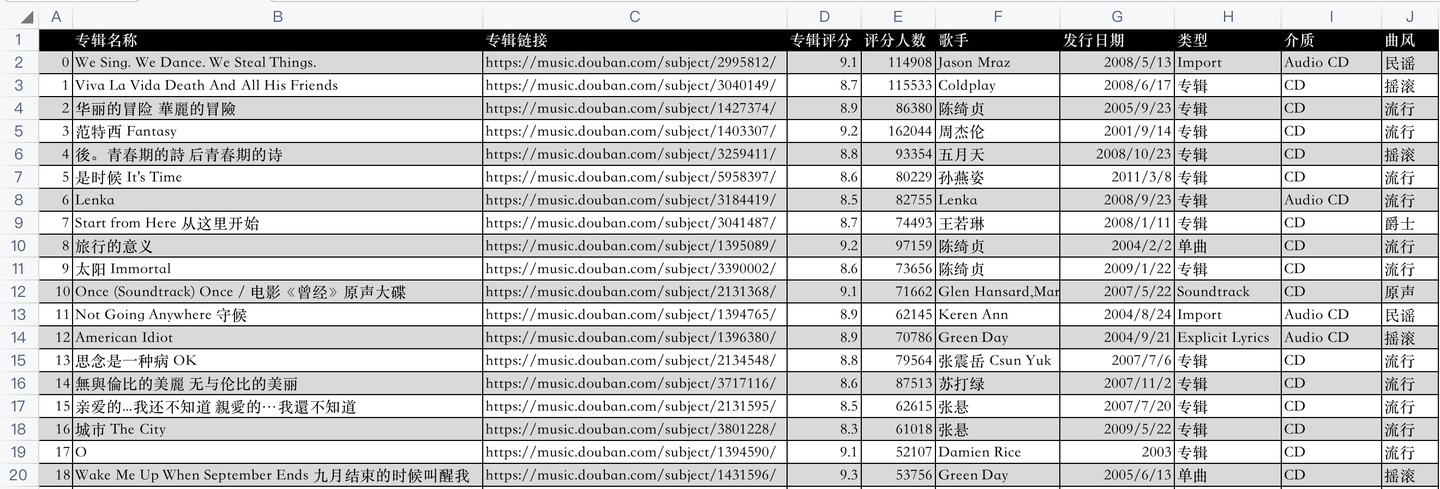
开发好python爬虫代码后,爬取成功后的csv数据,如下:
代码是怎样实现的爬取呢?下面逐一讲解python实现。
二、python爬虫代码讲解
首先,导入需要用到的库:
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
然后,向豆瓣音乐网页发送请求:
res = requests.get(url, headers=headers)
利用BeautifulSoup库解析响应页面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函数,(css解析的方法)编写代码逻辑,部分核心代码:
name = music.select('.pl2 a')[0].text.replace('\n', '').replace(' ', ' ').strip() # 专辑名称
music_name.append(name)
url = music.select('.pl2 a')[0]['href'] # 专辑链接
music_url.append(url)
star = music.select('.rating_nums')[0].text # 音乐评分
music_star.append(star)
star_people = music.select('.pl')[1].text # 评分人数
star_people = star_people.strip().replace(' ', '').replace('人评价', '').replace('(\n', '').replace('\n)',
'') # 数据清洗
music_star_people.append(star_people)
music_infos = music.select('.pl')[0].text.strip() # 歌手、发行日期、类型、介质、曲风
最后,将爬取到的数据保存到csv文件中:
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['专辑名称'] = music_name
df['专辑链接'] = music_url
df['专辑评分'] = music_star
df['评分人数'] = music_star_people
df['歌手'] = music_singer
df['发行日期'] = music_pub_date
df['类型'] = music_type
df['介质'] = music_media
df['曲风'] = music_style
df.to_csv(csv_name, encoding='utf_8_sig') # 将数据保存到csv文件
其中,把各个list赋值为DataFrame的各个列,就把list数据转换为了DataFrame数据,然后直接to_csv保存。
这样,爬取的数据就持久化保存下来了。
需要说明的是,豆瓣页面上第4、5、6页只有24首(不是25首),所以总数量是247,不是250。
不是爬虫代码有问题,是豆瓣页面上就只有247条数据。
三、同步视频
同步讲解视频:【python爬虫】利用python爬虫爬取豆瓣音乐TOP250的数据!
四、获取完整源码
附完整源码:【python爬虫案例】利用python爬虫爬取豆瓣音乐TOP250的数据!
我是 @马哥python说 ,持续分享python源码干货中!
【python爬虫案例】用python爬豆瓣音乐TOP250排行榜!的更多相关文章
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- KingbaseES V8R3 集群运维案例--kingbase_monitor.sh启动”two master“案例
案例说明: KingbaseES V8R3集群,执行kingbase_monitor.sh启动集群,出现"two master"节点的故障,启动集群失败:通过手工sys_ctl启动 ...
- Python正则表达式提取方法
- 敏捷MVP面面观
在过去的十年中,软件开发经历了许多阶段.从使流程敏捷高效到使用DevOps简化IT服务,已经有了许多突破,MVP是对软件开发过程产生了根本性影响的进步之一.本文将深入探讨MVP在软件开发中怎样起作用. ...
- #AC自动机#洛谷 2444 [POI2000]病毒
题目 给定若干01串,问是否存在无限长的01串任意子串不是给定的若干串 分析 如果在AC自动机上跳到了访问过的前缀即代表存在一个循环可以无限跳, 在AC自动机上记录哪些状态是不能访问的,在AC自动机上 ...
- #dp,模型转换,排列组合#AT1983 [AGC001E] BBQ Hard
题目 有两个长度为\(n\)的序列\(a,b\),需要求 \[\sum_{i=1}^n\sum_{j=i+1}^nC(a_i+b_i+a_j+b_j,a_i+a_j) \] 其中\(n\leq 200 ...
- 从零开始学Spring Boot系列-SpringApplication
SpringApplication类提供了一种从main()方法启动Spring应用的便捷方式.在很多情况下, 你只需委托给 SpringApplication.run这个静态方法 : @Spring ...
- C#-GroupBox包含控件,如何获取这些控件的名称
您可以使用 Enumerable.OfType在GroupBox中查找和投射您的RadioButtons: var radioButtons = groupBox1.Controls.OfType&l ...
- 踩坑指南:入门OpenTenBase之监控篇
本次监控将采用Prometheus.Grafana可视化工具以及postgres_exporter对OpenTenBase进行全面监控和优化. 安装监控 Docker安装 1.Docker要求 Cen ...
- JS解混淆
JS解混淆 最近在整理之前和一些同伴的分享资料,发现时间已经过了好久,特此整理一些有价值的分享记录. JS混淆 学习js混淆可以逆向分析混淆和加密过程,实战可用于爬虫和渗透信息获取 本文档用于初步介绍 ...
- sql 语句系列(两个日期之间)[八百章之第十七章]
前言 进入了日期章了. 年月日加减法 分别对原有的日期进行加减法. sql server select DATEADD(DAY,-5,HIREDATE) as hd_mimus_5D, DATEADD ...