【python爬虫案例】用python爬豆瓣音乐TOP250排行榜!
一、爬虫对象-豆瓣音乐TOP250
今天我们分享一期python爬虫案例讲解。爬取对象是,豆瓣音乐TOP250排行榜数据:https://music.douban.com/top250
开发好python爬虫代码后,爬取成功后的csv数据,如下:
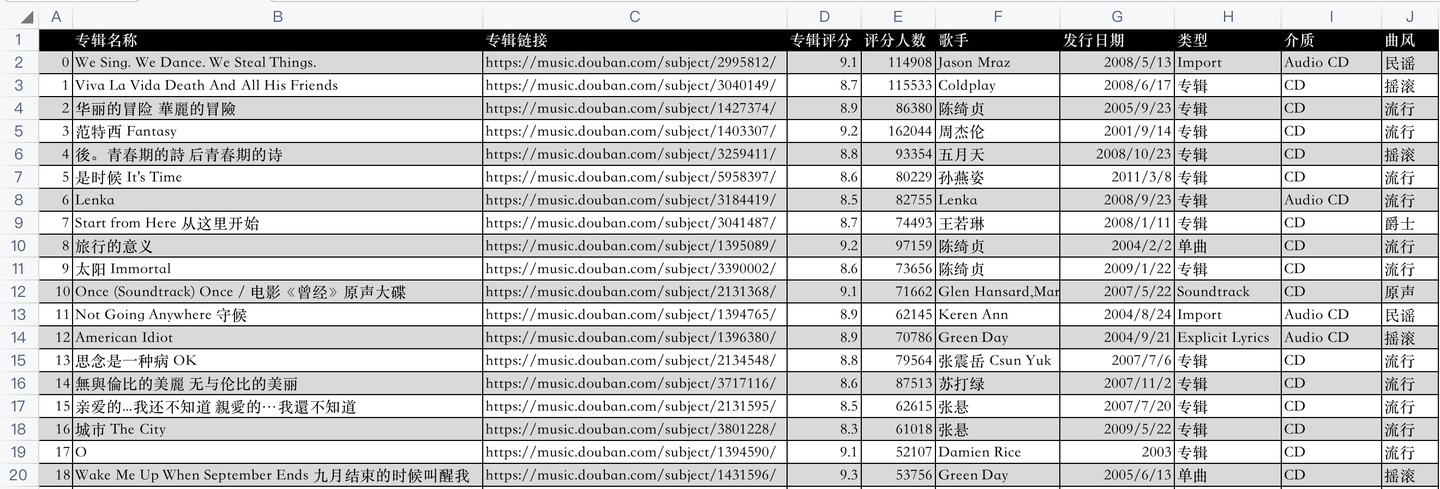
代码是怎样实现的爬取呢?下面逐一讲解python实现。
二、python爬虫代码讲解
首先,导入需要用到的库:
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
然后,向豆瓣音乐网页发送请求:
res = requests.get(url, headers=headers)
利用BeautifulSoup库解析响应页面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函数,(css解析的方法)编写代码逻辑,部分核心代码:
name = music.select('.pl2 a')[0].text.replace('\n', '').replace(' ', ' ').strip() # 专辑名称
music_name.append(name)
url = music.select('.pl2 a')[0]['href'] # 专辑链接
music_url.append(url)
star = music.select('.rating_nums')[0].text # 音乐评分
music_star.append(star)
star_people = music.select('.pl')[1].text # 评分人数
star_people = star_people.strip().replace(' ', '').replace('人评价', '').replace('(\n', '').replace('\n)',
'') # 数据清洗
music_star_people.append(star_people)
music_infos = music.select('.pl')[0].text.strip() # 歌手、发行日期、类型、介质、曲风
最后,将爬取到的数据保存到csv文件中:
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['专辑名称'] = music_name
df['专辑链接'] = music_url
df['专辑评分'] = music_star
df['评分人数'] = music_star_people
df['歌手'] = music_singer
df['发行日期'] = music_pub_date
df['类型'] = music_type
df['介质'] = music_media
df['曲风'] = music_style
df.to_csv(csv_name, encoding='utf_8_sig') # 将数据保存到csv文件
其中,把各个list赋值为DataFrame的各个列,就把list数据转换为了DataFrame数据,然后直接to_csv保存。
这样,爬取的数据就持久化保存下来了。
需要说明的是,豆瓣页面上第4、5、6页只有24首(不是25首),所以总数量是247,不是250。
不是爬虫代码有问题,是豆瓣页面上就只有247条数据。
三、同步视频
同步讲解视频:【python爬虫】利用python爬虫爬取豆瓣音乐TOP250的数据!
四、获取完整源码
附完整源码:【python爬虫案例】利用python爬虫爬取豆瓣音乐TOP250的数据!
我是 @马哥python说 ,持续分享python源码干货中!
【python爬虫案例】用python爬豆瓣音乐TOP250排行榜!的更多相关文章
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- verilog之random
verilog之random 1.基本作用 random,用于产生随机数.在测试时,有时需要测试的情况太多,无法一一列举,就需要使用抽样测试的方法验证功能是否可行.random是一个有返回值的系统函数 ...
- [ROS串口通信]报错:IO Exception (13): Permission denied, file /tmp/binarydeb/ros-noetic-serial-1.2.1/src/impl/unix.cc, line 151. [ERROR] [1705845384.528602780]: Unable to open port
ROS在串口通信时,当我们插入USB后,catkin_make之后,报错: IO Exception (13): Permission denied, file /tmp/binarydeb/ros- ...
- archlinux xfce 修改用户主目录名称
操作有风险,修改用户主目录名称后一些链接了旧主目录的的链接可能仍未修改.导致链接用不了,需要手动指定链接 1.删除指定用户保存的会话,未删除应该会导致修改用户主目录名称后进不去会话 2.切换到其它用户 ...
- CSS样式中的各种居中方式
1.水平居中 将margin-left和margin-right属性设置为auto,从而达到水平居中的效果. 代码: margin:0 auto; 2.文字水平垂直居中 利用line-height设为 ...
- Android将数据导入到已有的excel表格_0
用到的jxl2.6.12 jar 包下载地址: https://mvnrepository.com/artifact/net.sourceforge.jexcelapi/jxl/2.6.12
- #笛卡尔树,构造#洛谷 7726 天体探测仪(Astral Detector)
题目传送门 分析 考虑每个数字一定会影响一定的范围, 那么可以记录每个数影响的最长区间和产生的个数, 那么通过这个可以解方程求出对于这个最长区间这个数的所在位置, 可以发现它可以满足一个树形结构,直接 ...
- 中文GPTS,字节中文扣子Coze使用全教程
字节出自己的GPTS了,名字英文名叫coze,中文名叫"扣子".和OpenAI的GPTS类似.具有可定制性和完成特定任务的强大功能,它提供了一种新的GPT方式,可以让用户根据自己的 ...
- 深入理解 Java 变量类型、声明及应用
Java 变量 变量是用于存储数据值的容器.在 Java 中,有不同类型的变量,例如: String - 存储文本,例如 "你好".字符串值用双引号引起来. int - 存储整数( ...
- docker 应用篇————具名挂载和匿名挂载[十三]
前言 简单整理一下具名挂载和匿名挂载. 正文 来看一下匿名挂载. 这里-v指定了容器内部的路径,但是没有指定容器外部的路径,那么挂载到了什么地方. 用inspect 查看一下. 挂载到这个位置了. 然 ...
- Pytorch风格迁移代码
最近研究了一下风格迁移,主要是想应用于某些主题节日时动态融合背景,生成一些抽象的艺术图片,这里给大家分享一个现成的代码,我本地把环境搭建好后跑了试试,有兴趣的可以直接拿去运行: 1 import to ...