【Python爬虫案例】用python爬1000条哔哩哔哩搜索结果
一、爬取目标
大家好,我是 @马哥python说 ,一名10年程序猿。
今天分享一期爬虫的案例,用python爬哔哩哔哩的搜索结果,也就是这个页面:
爬取字段,包含:
页码, 视频标题, 视频作者, 视频编号, 创建时间, 视频时长, 弹幕数, 点赞数, 播放数, 收藏数, 分区类型, 标签, 视频描述
部分爬取结果: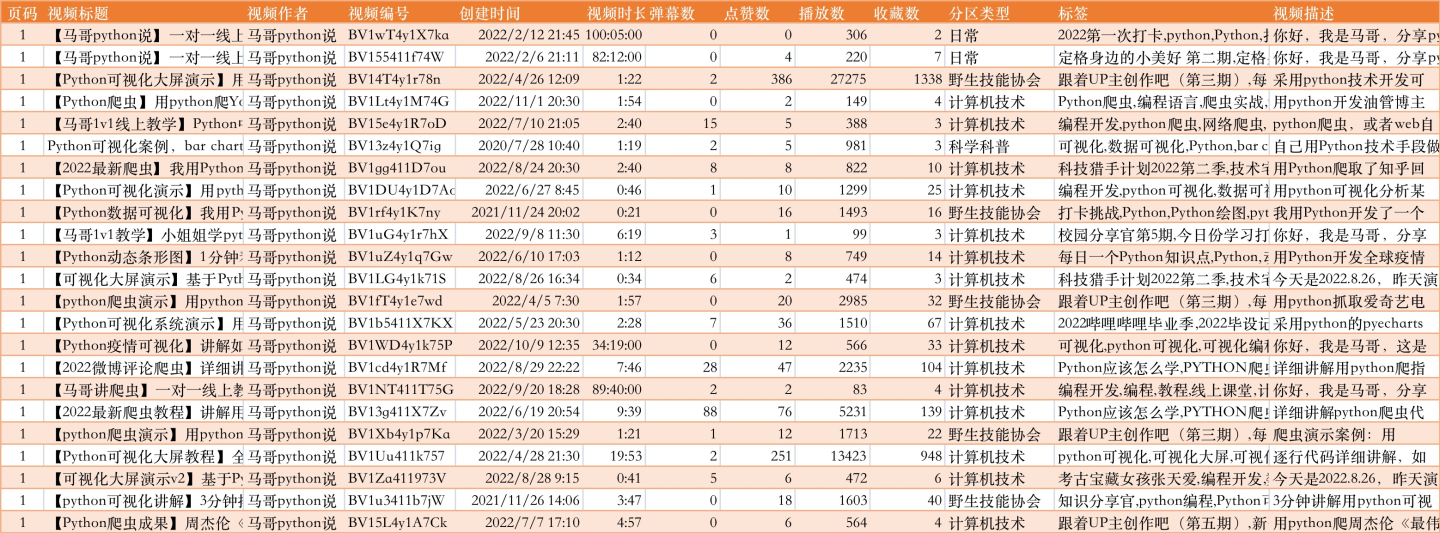
这里,我一共爬了30页,每页30条,共30*30=900条数据(当然,最大爬取页数可自定义放大)
下面,开始分析网页。
打开开发者模式,在页面搜索关键词,并进行翻页一次,如下: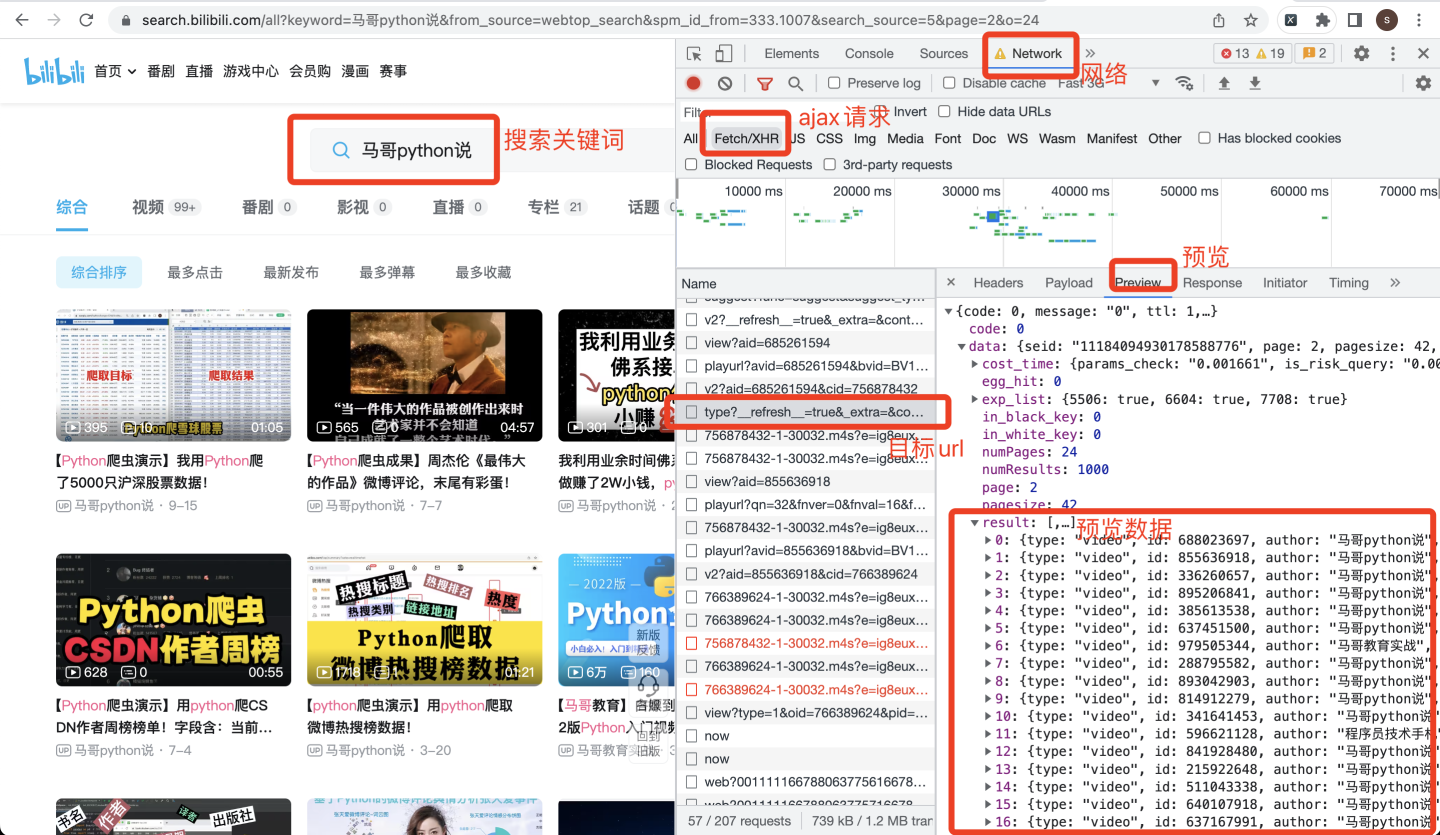
看到了result节点中的列表数据,就是我们要找到的视频数据,依次查看每个具体数据: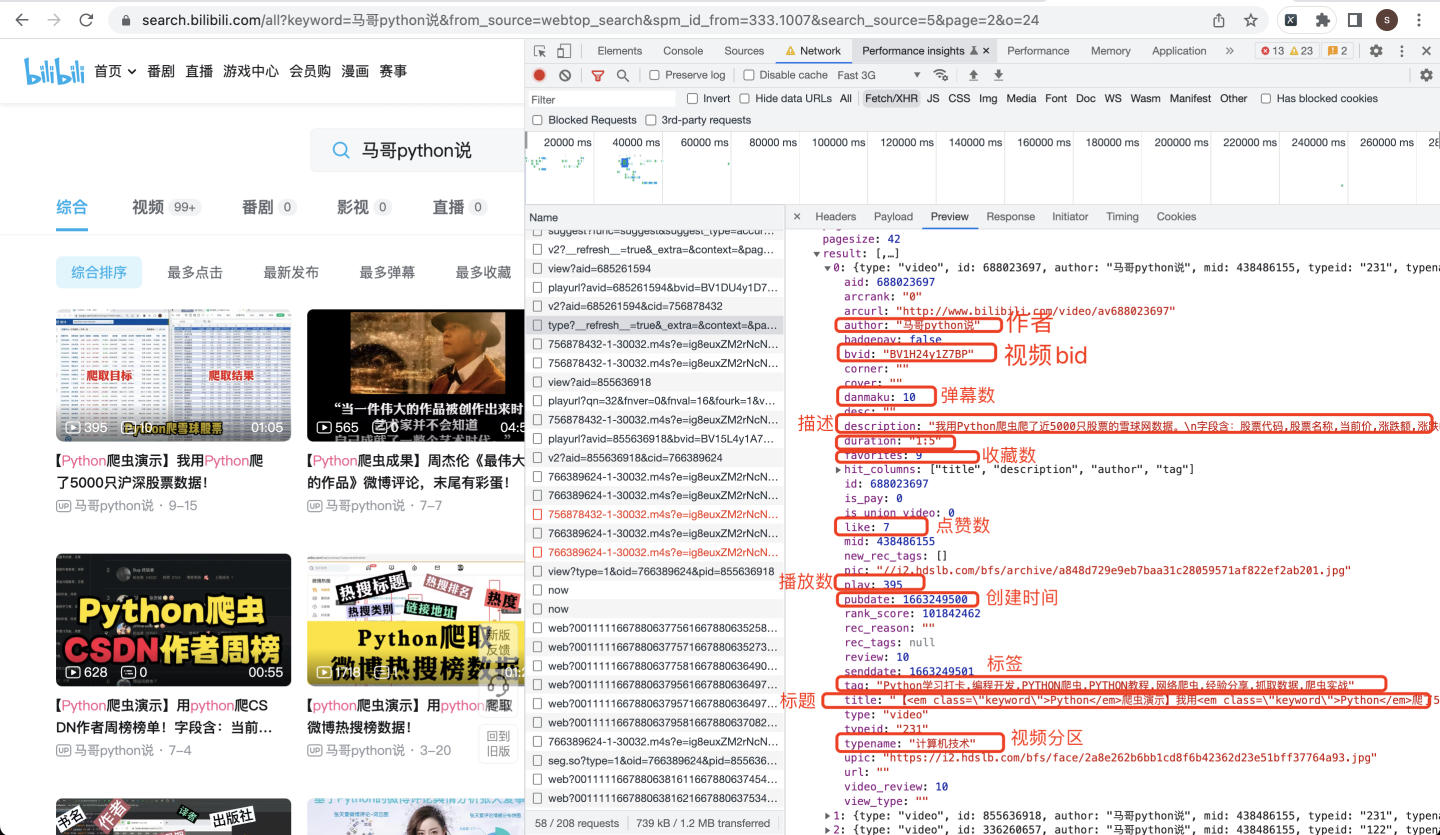
json数据
分析到这里,就可以开发爬虫了。
二、讲解代码
首先,导入用到的库:
import requests # 发送请求
import time # 获取时间
import os
import pandas as pd # 保存csv数据
import re # 数据清洗
下面,开始发送请求。
请求地址在哪获取呢?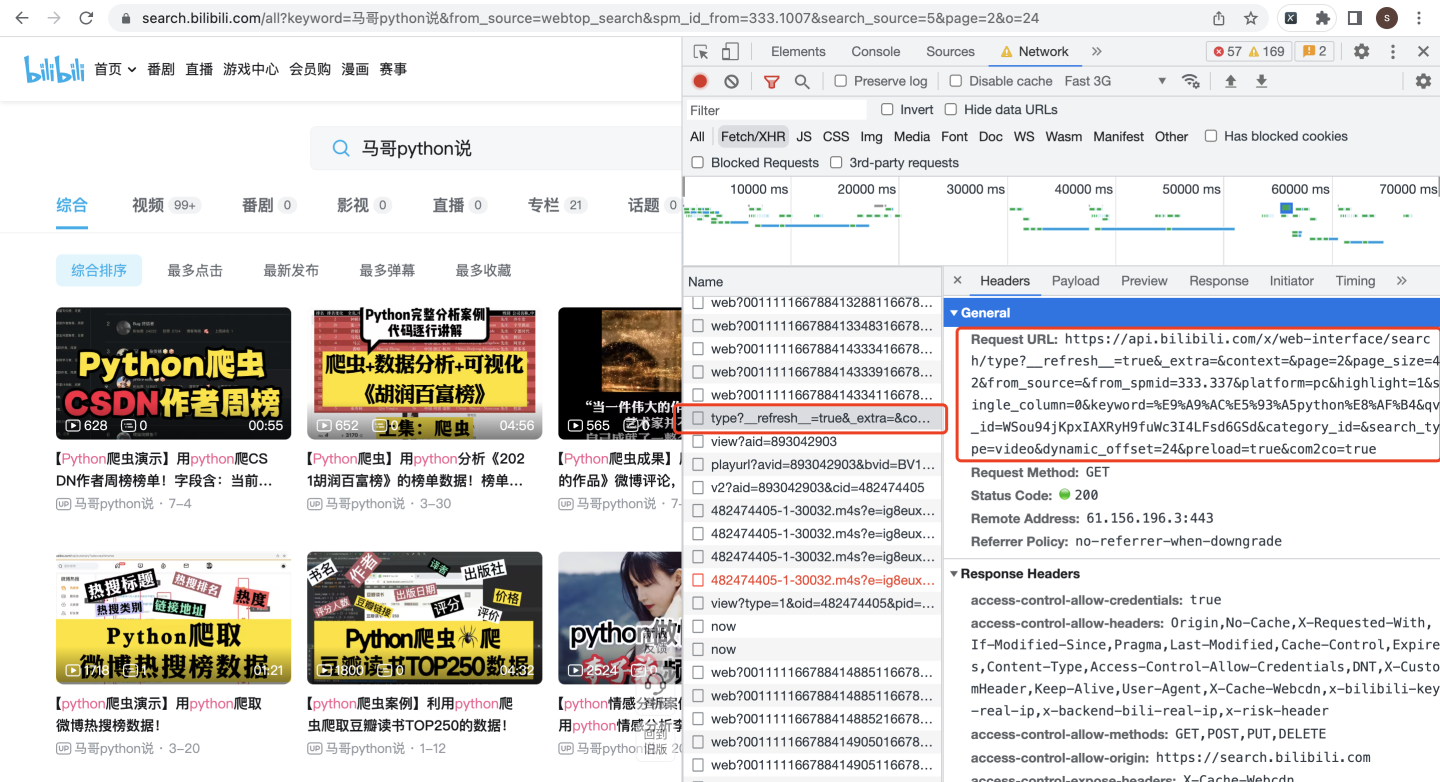
请求参数在Payload里面: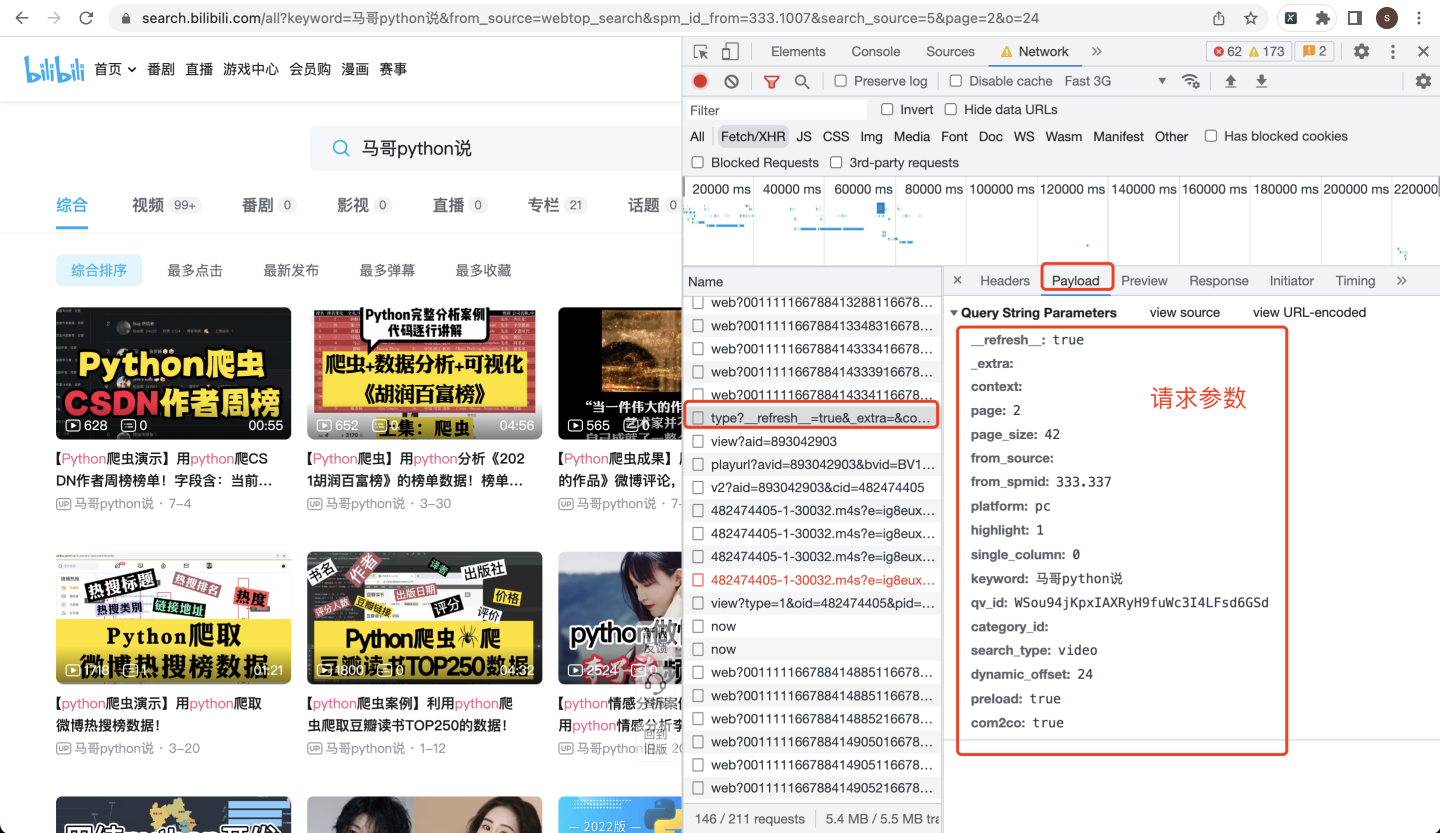
请求参数代码:
# 请求参数
params = {
'__refresh__': 'true',
'_extra': '',
'context': '',
'page': page,
'page_size': 30,
'from_source': '',
'from_spmid': '333.337',
'platform': 'pc',
'highlight': '1',
'single_column': '0',
'keyword': v_keyword,
'qv_id': 'dHavr2spEK3TphPa54klZ6svdhBYOlyP',
'category_id': '',
'search_type': 'video',
'dynamic_offset': 24,
'preload': 'true',
'com2co': 'true',
}
请求头,在Request Headers里面: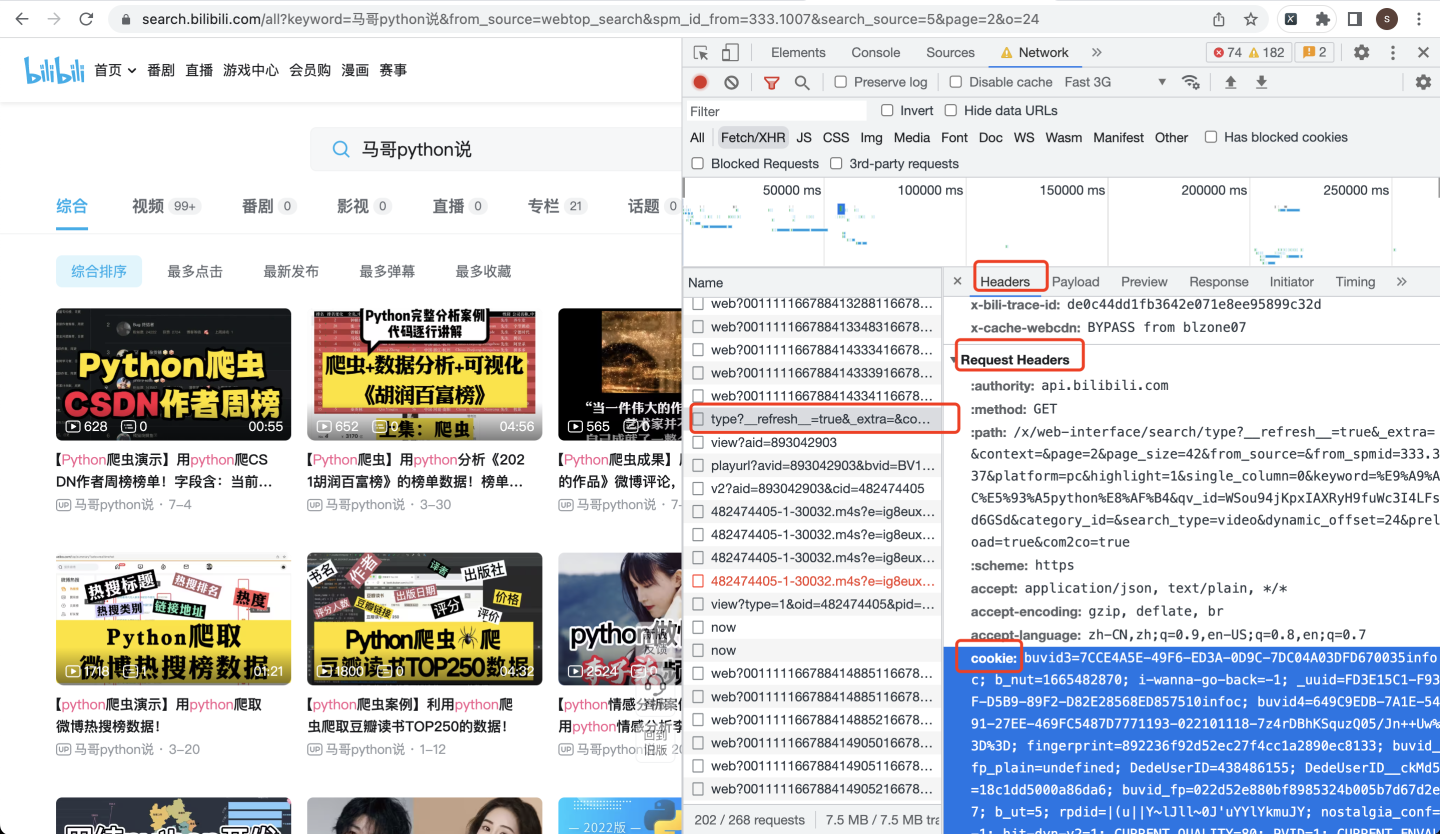
注意!cookie很重要,如果不传入cookie这个参数,会返回412错误码!
请求头代码:
# 请求头
headers = {'accept': 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
# cookie必需,否则返回412
'cookie': "换成自己的cookie",
'origin': 'https://search.bilibili.com',
'referer': 'https://search.bilibili.com/all?keyword={}&from_source=webtop_search&spm_id_from=333.1007&search_source=5&page=2&o=24'.format(
v_keyword),
'sec-ch-ua': '"Google Chrome";v="107", "Chromium";v="107", "Not=A?Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform ': '"macOS"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
发送请求:
# 向页面发送请求
r = requests.get(url, headers=headers, params=params)
print(r.status_code) # 查看响应码
解析出result列表数据:
data_list = j_data['data']['result']
print('数据长度:', len(data_list))
定义空列表,并for循环追加数据,以视频标题title为例:
for data in data_list:
title = re.compile(r'<[^>]+>', re.S).sub('', data['title']) # 正则表达式清洗文本
print('视频标题: ' + title)
title_list.append(title)
其他字段同理,不再赘述。
最后通过pandas的to_csv,保存最终数据。
# 数据保存到csv文件
df.to_csv(v_out_file, encoding='utf_8_sig', mode='a+', index=False, header=header)
to_csv的时候需加上选项(encoding='utf_8_sig'),否则存入数据会产生乱码,尤其是windows用户!
三、同步讲解视频
讲解视频:https://www.bilibili.com/video/BV1MG4y1f7Sx
四、完整源码
附完整源码:公众号"老男孩的平凡之路"后台回复"爬B站搜索"即可获取。
原创作者: 马哥python说 持续分享python干货中!
【Python爬虫案例】用python爬1000条哔哩哔哩搜索结果的更多相关文章
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- python爬虫27 | 当Python遇到MongoDB的时候,存储av女优的数据变得如此顺滑爽~
上次 我们知道了怎么操作 MySQL 数据库 python爬虫26 | 把数据爬取下来之后就存储到你的MySQL数据库. MySQL 有些年头了 开源又成熟又牛逼 所以现在很多企业都在使用 MySQL ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
随机推荐
- 操作推荐-git工作流
操作推荐-git工作流 sourcetree环境 sourcetree是一款可视化的版本管理软件 可以实现版本的管理和发布 同样,也支持git工作流的使用 创建git工作流 在main或者master ...
- 【已解决】linux安装mysql依赖包(mysql-community-common-5.7.35-1.el7.x86_64)冲突
错误信息: 软件包 mysql-community-common-5.7.35-1.el7.x86_64 (比 mysql-community-common-5.7.28-1.el7.x86_64 还 ...
- 详解SSL证书系列(9)SSL客户端认证
上一篇介绍了HTTPS和HTTP协议的区别,理解了HTTP加上加密处理和认证以及完整性保护后即是HTTPS,同时HTTPS也是身披SSL外壳的HTTP,那么SSL客户端认证是怎么回事呢?这篇文章我将带 ...
- #期望dp#51nod 2015 诺德街
题目传送门 分析 禁不住 QuantAsk 的诱惑(bushi) 考虑一条路线可以由若干段 \(1-2-\dots-n-\dots-2\) 以及 最后一段 \(1-\dots-x\) 组成. 对于最后 ...
- #分治NTT#CF1218E Product Tuples
Codeforces 用 OGF 表示 \(F(B,x)\) 就是 \[\prod_{i=1}^n(1+(q-a_i)x) \] 直接分治 NTT 把 \([x^k]\) 也就是这一位的系数求出来就可 ...
- HTTP协议安全头部的笔记
本文于2016年3月完成,发布在个人博客网站上. 考虑个人博客因某种原因无法修复,于是在博客园安家,之前发布的文章逐步搬迁过来. 近日项目组对当前开发.维护的Web系统做了AppScan扫描,扫描的结 ...
- 开发板如何适配OpenHarmony 3.2
简介 OpenAtom OpenHarmony(以下简称"OpenHarmony") 3.2 Beta5版本在OpenHarmony 3.1 Release版本的基础上,有以下 ...
- SQL HAVING 子句详解:在 GROUP BY 中更灵活的条件筛选
SQL HAVING子句 HAVING子句被添加到SQL中,因为WHERE关键字不能与聚合函数一起使用. HAVING语法 SELECT column_name(s) FROM table_name ...
- Go 语言之 Maps 详解:创建、遍历、操作和注意事项
Maps 用于以键值对的形式存储数据值.Maps中的每个元素都是一个键值对.Maps是一个无序且可更改的集合,不允许重复.Maps的长度是其元素的数量.您可以使用 len() 函数来查找长度.Maps ...
- Python操作临时文件---tempfile
# 使用标准库中 tempfile 下的 TemporaryFile,NamedTemporaryFile # TemporaryFile(mode='w+b', bufsize=1, suffix= ...