论文翻译: FREEVC:朝着高质量、无文本、单次转换声音的目标迈进
原文:FREEVC: TOWARDS HIGH-QUALITY TEXT-FREE ONE-SHOT VOICE CONVERSION
原文地址:https://ieeexplore.ieee.org/abstract/document/10095191
个人总结:
1.提出mel谱缩放增强方法。
2.基于VITS框架进行改进,BUT在对照实验中缺没有对比VITS
3.引入WavLM模型提高VC模型对说话人内容和说话人信息的解耦能力
翻译:
摘要: 语音转换(VC)可以通过首先提取源内容信息和目标说话者信息,然后利用这些信息重构波形来实现。然而,当前的方法通常要么提取带有泄露说话者信息的不完整内容信息,要么需要大量的注释数据进行训练。此外,转换模型与声码器之间的不匹配可能会降低重构波形的质量。在本文中,我们采用了VITS的端到端框架来实现高质量的波形重构,并提出了在无需文本注释的情况下提取干净内容信息的策略。我们通过对WavLM特征施加信息瓶颈来解耦内容信息,并提出了基于频谱重缩放的数据增强方法来提高提取内容信息的纯度。实验结果表明,所提出的方法优于使用注释数据训练的最新VC模型,并具有更强的鲁棒性。
索引词— 语音转换、自监督学习、信息瓶颈、数据增强
引言
语音转换(Voice Conversion,VC)是一种技术,可以将源说话者的声音转换为目标风格,比如说话者身份[1]、韵律[2]和情感[3],同时保持语言内容不变。在本文中,我们专注于单次设置下的说话者身份转换,即仅给定目标说话者的一段话作为参考。
典型的单次语音转换方法是从源语音和目标语音中分别解耦内容信息和说话者信息,然后使用它们来重构转换后的语音[4]。因此,转换后语音的质量依赖于(1)VC模型的解耦能力,以及(2)VC模型的重构能力。
根据语音转换(VC)系统如何解耦内容信息,我们可以将当前的VC方法分为基于文本的VC和无文本的VC。一种流行的基于文本的VC方法是使用自动语音识别(ASR)模型提取音素后验图(PPG)作为内容表示[5][6]。有些研究人员还利用文本到语音(TTS)模型中的共享语言知识来解耦内容信息[7][8]。然而,这些方法需要大量的注释数据来训练ASR或TTS模型。数据注释是昂贵的,而且注释的准确性和细粒度,例如音素级别和字素级别,会影响模型的性能。为了避免基于文本方法的问题,人们开始研究无文本方法,即在没有文本注释的情况下学习提取内容信息。典型的无文本方法包括信息瓶颈[4]、向量量化[9]、实例归一化[10]等。然而,它们的性能通常落后于基于文本的方法[11]。这是因为它们提取的内容信息更容易泄露源说话者的信息。
许多VC系统采用两阶段的重构流程[6][4]。在第一阶段,转换模型将源声学特征转换为目标说话者的声音,而在第二阶段,声码器将转换后的特征转换为波形。这两个模型通常是分别训练的。然而,转换模型预测的声学特征与声码器在训练过程中使用的真实语音特征分布不同。这种特征不匹配问题,在TTS中也存在,可能会降低重构波形的质量[12]。VITS是一个一阶段模型,可以同时进行TTS和VC。通过通过条件变分自编码器(CVAE)的潜在变量将两个阶段的模型连接起来,减少了特征不匹配问题。通过采用对抗训练,进一步提高了重构波形的质量。然而,VITS是一个基于文本的模型,并且仅限于多对多的VC,即源说话者和目标说话者都是已知的说话者。
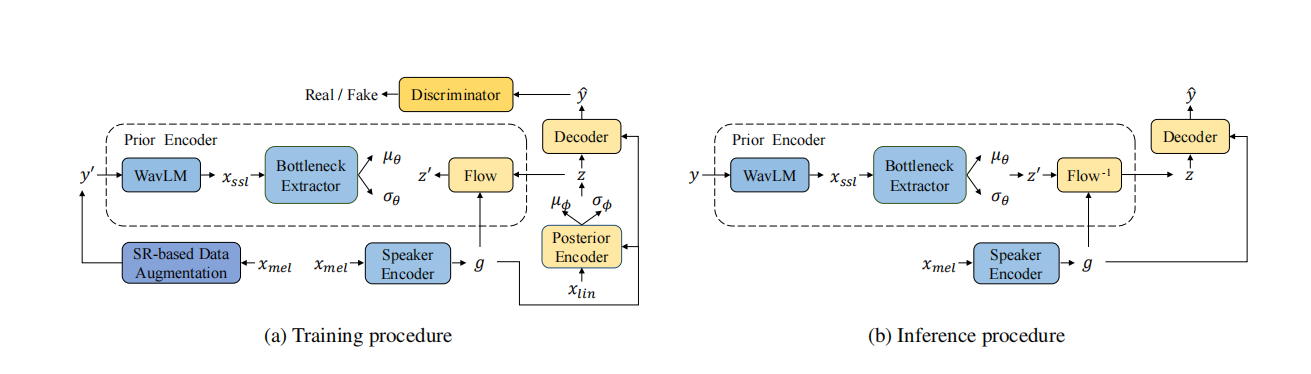
图1:FreeVC的训练和推理过程。其中,y表示源波形,y0表示增强后的波形,yˆ表示转换后的波形,xmel表示梅尔频谱图,xlin表示线性谱图,xssl表示SSL特征,g表示说话者嵌入。
在本文中,我们提出了一个名为FreeVC的无文本单次语音转换系统。该系统采用了VITS的框架,以其出色的重构能力为基础,但是在不需要文本注释的情况下学习解耦内容信息。近期,语音自监督学习(Speech Self-Supervised Learning,SSL)在语音识别[14]、说话者验证[15]和语音转换[16]等下游任务中取得了成功,证明了SSL特征相比传统声学特征(如梅尔频谱图)的潜在优势。我们使用WavLM[17]从波形中提取SSL特征,并引入一个信息瓶颈提取器来从SSL特征中提取内容信息。我们还提出了基于频谱重缩放(SR)的数据增强方法,该方法扭曲说话者信息而不改变内容信息,以增强模型的解耦能力。为了实现单次语音转换,我们使用说话者编码器来提取说话者信息。我们的代码和演示页面是公开可用的。
方法
如图1所示,FreeVC的主干结构来自于VITS,它是一个使用GAN训练增强的条件变分自编码器(CVAE)。与VITS不同,FreeVC的先验编码器采用原始波形作为输入,而不是文本注释,并且具有不同的结构。说话者嵌入是由说话者编码器提取的,用于进行单次语音转换。此外,FreeVC采用不同的训练策略和推理过程。接下来,我们将在以下小节中详细介绍细节。
2.1. 模型架构
FreeVC包含先验编码器、后验编码器、解码器、判别器和说话者编码器,其中后验编码器、解码器和判别器的架构遵循VITS。我们将重点描述先验编码器和说话者编码器。
2.1.1. 先验编码器
先验编码器包含一个WavLM模型、一个信息瓶颈提取器和一个正则化流(normalizing flow)。WavLM模型和信息瓶颈提取器负责提取内容信息,并将其建模为分布N(z0; µθ, σθ^2)。WavLM模型以原始波形作为输入,并生成包含内容信息和说话者信息的1024维SSL特征xssl。为了去除xssl中包含的不必要的说话者信息,将1024维xssl输入到信息瓶颈提取器,并转换为d维表示,其中d远小于1024。这种巨大的维度差会施加信息瓶颈,强制使得结果低维表示丢弃与内容无关的信息,例如噪声或说话者信息。接下来,将d维隐藏表示投影到2d维隐藏表示,然后将其分为d维µθ和d维σθ。正则化流在条件说话者嵌入g的情况下被采用,以提高先验分布的复杂性。遵循VITS的做法,它由多个仿射耦合层[18]组成,并被设计为体积保持,其雅可比行列式|det ∂z0/∂z|为1。
2.1.2. 说话者编码器
我们使用两种类型的说话者编码器:预训练的说话者编码器和非预训练的说话者编码器。预训练的说话者编码器是在大量说话者数据集上训练的说话者验证模型。它在VC中被广泛使用,并被认为优于非预训练的说话者编码器。我们采用了[6]中使用的预训练说话者编码器。非预训练的说话者编码器是与模型的其余部分一起从头开始进行联合训练。我们使用一个简单的基于LSTM的架构,并相信如果提取的内容表示足够干净,说话者编码器将学习对缺失的说话者信息进行建模。
2.2. 训练策略
2.2.1. 基于频谱重缩放的数据增强
一个过于窄的信息瓶颈将会丢失一些内容信息,而一个过于宽的信息瓶颈则会包含一些说话者信息[4]。我们不打算精细调整信息瓶颈的大小,而是采用基于频谱重缩放的数据增强来帮助模型学习提取干净的内容信息,通过扭曲源波形中的说话者信息。与使用各种信号处理技术来破坏说话者信息的工作[19][20]不同,我们的方法更容易实现,并且不需要复杂的信号处理知识。

我们提出的基于频谱重缩放的数据增强包括三个步骤:(1) 从波形y获取梅尔频谱图xmel;(2) 对xmel进行垂直频谱重缩放操作,得到修改后的梅尔频谱图x0mel;(3) 使用神经声码器从x0mel中重构波形y0。垂直频谱重缩放操作如图2所示。梅尔频谱图可以看作是一个具有水平时间轴和垂直频率频带轴的图像。垂直频谱重缩放操作首先使用双线性插值将梅尔频谱图在垂直方向上按一定比例r进行调整,然后将调整后的梅尔频谱图填充或剪切为原始形状。如果比例r小于1,我们在上方用最高频率频带值和高斯噪声填充压缩的梅尔频谱图,从而产生音调较低且共振峰距较近的语音;反之,如果比例r大于1,我们剪切拉伸的梅尔频谱图的顶部多余频率频带,从而产生音调较高且共振峰距较远的语音。通过使用增强的语音进行训练,模型将更好地学习提取在每个比例r下共享的不变内容信息。除了垂直频谱重缩放外,我们还可以使用水平频谱重缩放来产生时间尺度修改的波形。
2.2.2. 训练损失
训练损失分为CVAE相关的损失和GAN相关的损失。CVAE相关的损失包括重构损失Lrec,即目标梅尔频谱图与预测梅尔频谱图之间的L1距离,以及KL损失Lkl,即先验分布pθ(z|c)和后验分布qφ(z|xlin)之间的KL散度,其中:
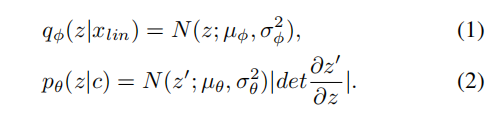
在这里,条件c是包含在波形y/y’中的内容信息。通过最小化Lkl,可以减少特征不匹配问题。GAN相关的损失包括鉴别器D和生成器G的对抗损失Ladv(D)和Ladv(G),以及生成器G的特征匹配损失Lfm(G)。最后,FreeVC的训练损失可以表示为:
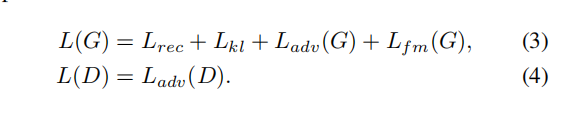
2.3. 推理过程
与VITS不同,VITS在语音转换推理过程中通过后验编码器和先验编码器中的正则化流提取内容信息,而FreeVC在推理过程中通过先验编码器中的WavLM和信息瓶颈提取器提取内容信息,与训练过程中一样。这样,提取的内容表示不会受到源说话者嵌入质量的影响。
实验
3.1. 实验设置
我们在VCTK [23]和LibriTTS [24]数据集上进行实验。只有VCTK数据集用于训练。对于VCTK数据集,我们使用了107位说话者的数据,其中314个句子(每位说话者2个句子)随机选取作为验证集,10700个句子(每位说话者10个句子)用于测试,其余用于训练。对于LibriTTS数据集,我们使用了test-clean子集进行测试。所有音频样本均降采样至16 kHz。使用短时傅里叶变换计算线性谱图和80频带梅尔谱图。FFT大小、窗口大小和帧移大小分别设置为1280、1280和320。我们将信息瓶颈提取器的维度d设置为192。对于基于频谱重缩放的数据增强,调整比例r的范围从0.85到1.15。我们使用HiFi-GAN v1声码器[25]将修改后的梅尔频谱图转换为波形。我们的模型在一块NVIDIA 3090 GPU上进行训练,训练步数达到900k。批量大小设置为64,最大段长度为128帧。
我们选择了三个基线模型与所提出的方法进行比较:(1) VQMIVC [26],一个使用非预训练的说话者编码器的无文本模型;(2) BNE-PPG-VC [6],一个使用预训练的说话者编码器的基于文本的模型;(3) YourTTS [27],一个扩展VITS到单次设置的基于文本模型,引入了预训练的说话者编码器。我们测试了三个版本的所提出的方法:(1) FreeVC-s,使用非预训练的说话者编码器的所提出的模型;(2) FreeVC,使用预训练的说话者编码器的所提出的模型;(3) FreeVC (w/o SR),使用预训练的说话者编码器的所提出的模型,但没有进行基于频谱重缩放的数据增强。
3.2. 评估指标
我们进行了主观和客观的评估。 对于主观评估,我们邀请了15名参与者对语音的自然度和说话者相似度进行评估,评估采用5级均值意见分数(MOS)和相似度均值意见分数(SMOS)。我们随机选择了6位已知说话者(3男性,3女性)来自VCTK,6位未知说话者(3男性,3女性)来自LibriTTS,并分别在已知-已知、未知-已知和未知-未知场景中进行评估。 对于客观评估,我们使用了三个指标:词错误率(WER)、字符错误率(CER)和F0-PCC。源语音和转换后语音之间的词错误率和字符错误率是通过一个自动语音识别(ASR)模型得到的。F0-PCC是源语音和转换后语音之间F0的皮尔逊相关系数[28]。我们随机选择了400个句子(200个来自VCTK,200个来自LibriTTS)作为源语音,并选择了12个说话者(6个已知说话者,6个未知说话者)作为目标说话者。
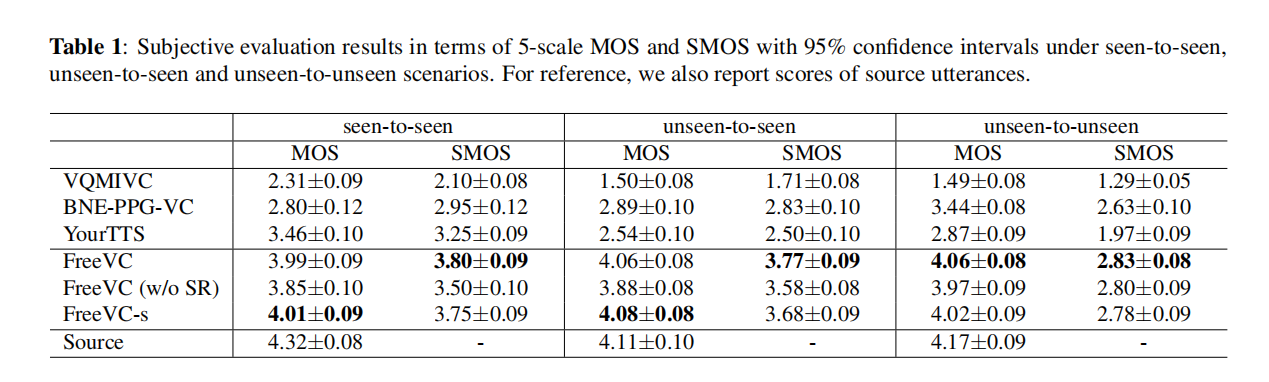
表1:在已知-已知、未知-已知和未知-未知场景下,以5级MOS和SMOS为评估指标的主观评估结果,带有95%置信区间。为了对比,我们还报告了源语音的评分。
3.3. 结果与分析
3.3.1. 语音自然度和说话者相似度
表1中的MOS和SMOS结果表明,所提出的模型在所有场景下的语音自然度和说话者相似度方面均优于所有基线模型。此外,我们观察到所有基线模型在源语音质量较低的情况下,例如录制质量低或发音不清楚时,都会出现质量降低的问题,而我们提出的模型几乎不受影响,这表明了所提出的内容提取方法的稳健性。
在所提出的方法的三个版本中,FreeVC (w/o SR) 的语音自然度和说话者相似度低于 FreeVC。这表明,在没有基于频谱重缩放的数据增强的情况下训练的模型泄漏了一些源说话者信息,导致难以重构令人满意的波形。FreeVC-s的表现与FreeVC相似,表明预训练的说话者编码器并不是我们方法性能的主要因素,一个简单的非预训练说话者编码器能够与预训练的说话者编码器相匹配的性能。FreeVC在未知-未知场景中表现优于FreeVC-s,这表明在大量说话者数据上预训练的说话者编码器可以提高对未知目标的性能。
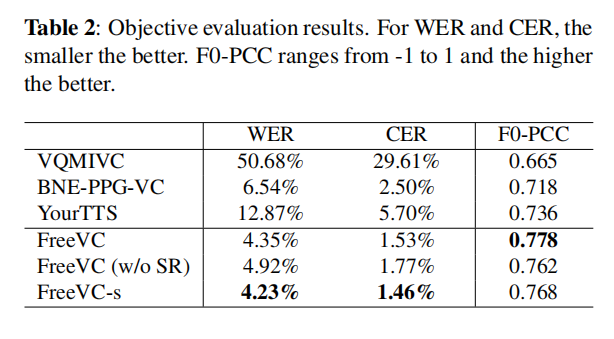
表2:客观评估结果。对于WER和CER,数值越小越好。F0-PCC的范围在-1到1之间,数值越高越好。
3.3.2. 语音智能和F0变化一致性
从表2中可以看出,我们提出的模型的WER和CER都比所有基线模型(甚至是基于文本的模型)都要低。这表明所提出的方法能够很好地保留源语音的语言内容。F0-PCC的结果显示,我们提出的方法与源语音具有更高的F0变化一致性,这表明所提出的方法能够有效地保持源语音的语调。此外,我们观察到使用基于频谱重缩放的数据增强进行训练略微提高了语音智能和F0变化一致性。
结论
本文提出了FreeVC,一个无文本的单次语音转换系统。我们采用VITS的框架进行高质量的波形重建。内容信息是从WavLM特征的瓶颈中提取的。我们还提出了基于频谱重缩放的数据增强方法来改善模型的解缠能力。实验结果证明了所提出方法的优越性。未来,我们将研究说话者自适应方法,以提高对未知目标说话者的相似性,尤其是在数据较少的情况下。
论文翻译: FREEVC:朝着高质量、无文本、单次转换声音的目标迈进的更多相关文章
- 如何写好一篇高质量的IEEE/ACM Transaction级别的计算机科学论文?
转自<知乎>如何写好一篇高质量的IEEE/ACM Transaction级别的计算机科学论文? 问题: 作为一个博士生,一直为写论文头疼,读过很多高质量论文,觉得写的真好,但是轮到自己写总 ...
- 语音合成论文翻译:2019_MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
论文地址:MelGAN:条件波形合成的生成对抗网络 代码地址:https://github.com/descriptinc/melgan-neurips 音频实例:https://melgan-neu ...
- 高质量的内容是SEO的关键
内容是最有效的SEO策略,但也是最难执行的 正确的目录对SEO(搜索引擎优化:search engine optimization)关乎重大.根据Ascend2在2014年4月对全球营销专业人士做的调 ...
- 四大高质量且实用的chrome翻译插件推荐
Google英译汉的质量怎么样?日常生活用语翻译还可以,但是一到专业性术语就歇菜了,翻译出来的东西简直就是惨不忍睹,惨绝人寰..对于酷爱英语学习又有强迫症的患者来说,一款既实用又方便,无疑就是雪中送炭 ...
- [转] 翻译-高质量JavaScript代码书写基本要点 ---张鑫旭
by zhangxinxu from http://www.zhangxinxu.com本文地址:http://www.zhangxinxu.com/wordpress/?p=1173 原文作者:St ...
- 编写高质量JavaScript代码绳之以法(The Essentials of Writing High Quality JavaScript)翻译
原文:The Essentials of Writing High Quality JavaScript 才华横溢的Stoyan Stefanov,在他写的由O'Reilly初版的新书<Java ...
- [转]综述论文翻译:A Review on Deep Learning Techniques Applied to Semantic Segmentation
近期主要在学习语义分割相关方法,计划将arXiv上的这篇综述好好翻译下,目前已完成了一部分,但仅仅是尊重原文的直译,后续将继续完成剩余的部分,并对文中提及的多个方法给出自己的理解. _论文地址:htt ...
- 综述论文翻译:A Review on Deep Learning Techniques Applied to Semantic Segmentation
近期主要在学习语义分割相关方法,计划将arXiv上的这篇综述好好翻译下,目前已完成了一部分,但仅仅是尊重原文的直译,后续将继续完成剩余的部分,并对文中提及的多个方法给出自己的理解. 论文地址:http ...
- SSD: Single Shot MultiBoxDetector英文论文翻译
SSD英文论文翻译 SSD: Single Shot MultiBoxDetector 2017.12.08 摘要:我们提出了一种使用单个深层神经网络检测图像中对象的方法.我们的方法,名为SSD ...
- 深度学习论文翻译解析(三):Detecting Text in Natural Image with Connectionist Text Proposal Network
论文标题:Detecting Text in Natural Image with Connectionist Text Proposal Network 论文作者:Zhi Tian , Weilin ...
随机推荐
- 带你用三种不同的工具体验AI作诗
摘要:本实验基于华为云API Arts和API Explorer,向用户介绍诗歌生成API,指导用户使用华为云工具,体验AI作诗的过程. 本文分享自华为云社区<AI语言能力体验:通过三种不同的工 ...
- Karmada v1.5发布:多调度组助力成本优化
摘要:在最新发布的1.5版本中,Karmada 提供了多调度组的能力,利用该能力,用户可以实现将业务优先调度到成本更低的集群,或者在主集群故障时,优先迁移业务到指定的备份集群. 本文分享自华为云社区& ...
- 【Python毕业设计】基于Python+Flask+MySQL的学生信息管理系统(附完整源码)
1.项目说明基于python+Flask+mysql的学生信息管理系统项目实战 项目需要安装pycharm专业版,mysql数据库以及项目所需的所有模块创建数据库名称db_online_notes,然 ...
- Comparator之用最少数量的箭引爆气球
文章目录 前言 关于Comparator 原题 前言 今天刷个题,遇到一个很有趣的问题,关于Comparator的使用,感觉也是一个关于写代码的一些小细节的问题 关于Comparator Compar ...
- vue全家桶进阶之路3:Node.js
Node.js发布于2009年5月,由Ryan Dahl开发,是一个基于Chrome V8引擎的JavaScript运行环境,使用了一个事件驱动.非阻塞式I/O模型, 让JavaScript 运行在服 ...
- k8s资源对象(二)
Configmap和Secret资源介绍 secret和configmap资源都是通过挂载的方式将对应数据挂载到容器内部环境中去使用,两者的使用没有太多的不同 ,configmap资源通常用于为pod ...
- Cesium中监听MOUSE_MOVE事件获取经纬度和高度
有时候在这个圆球上获取精确的经度纬度还不容易,特别是高度 还好在cesium提供了接口,看 let selft = this; const scene = this.viewer.scene; var ...
- 使用Cordova插件实现两个app之间的相互调用和通讯
几年前使用Cordova 进行两个app之间的相互调用和通讯:当时也是几经折腾,今天把它整理出来,理一下思路,也方便有同样需求的朋友参考 一.require引入 plugin require(&quo ...
- JS逆向实战15——猿人学第五题 动态cookie乱码增强
声明 本文章中所有内容仅供学习交流,抓包内容.敏感网址.数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! 网站 https://ma ...
- sqlmap工具学习
tryhackme:sqlmap github:https://github.com/sqlmapproject/sqlmap kali集成 参数介绍 sqlmap -h ___ __H__ ___ ...