MySQL 基础(二)日志
在操作系统和数据库管理系统中,为了提高数据的容灾性,一般都会通过写入相关日志的方式来记录数据的修改,使得系统受到灾难时能够从之前的数据中恢复过来。MySQL 也提供了日志的机制来提高数据的容灾性,主要包括 redo 日志和 undo 日志
redo 日志
在 Buffer Pool中修改了页,如果在将 Buffer Pool 中的内容冲洗到磁盘上的这一过程出现了问题,导致内存中的数据失效,那么这个已经提交的事务在数据库中所做的修改就丢失了,这时需要通过 redo 日志来重新提交本次的事务。
redo 简单日志类型
通用日志类型
具体的结构如下图所示:

固定长度日志类型
主要有以下几种:
MLOG_1BYTE(type = 1)、MLOG_2BYTE(type = 2)、MLOG_4BYTE(type = 4)、MLOG_8BYTE(type = 8)
具体的结构如下图所示:

不限定长度日志类型
对应的类型为 MLOG_WRITE_STRING(type = 30),具体的结构如下图所示:

redo 复杂日志类型
复杂日志的结构如下所示:
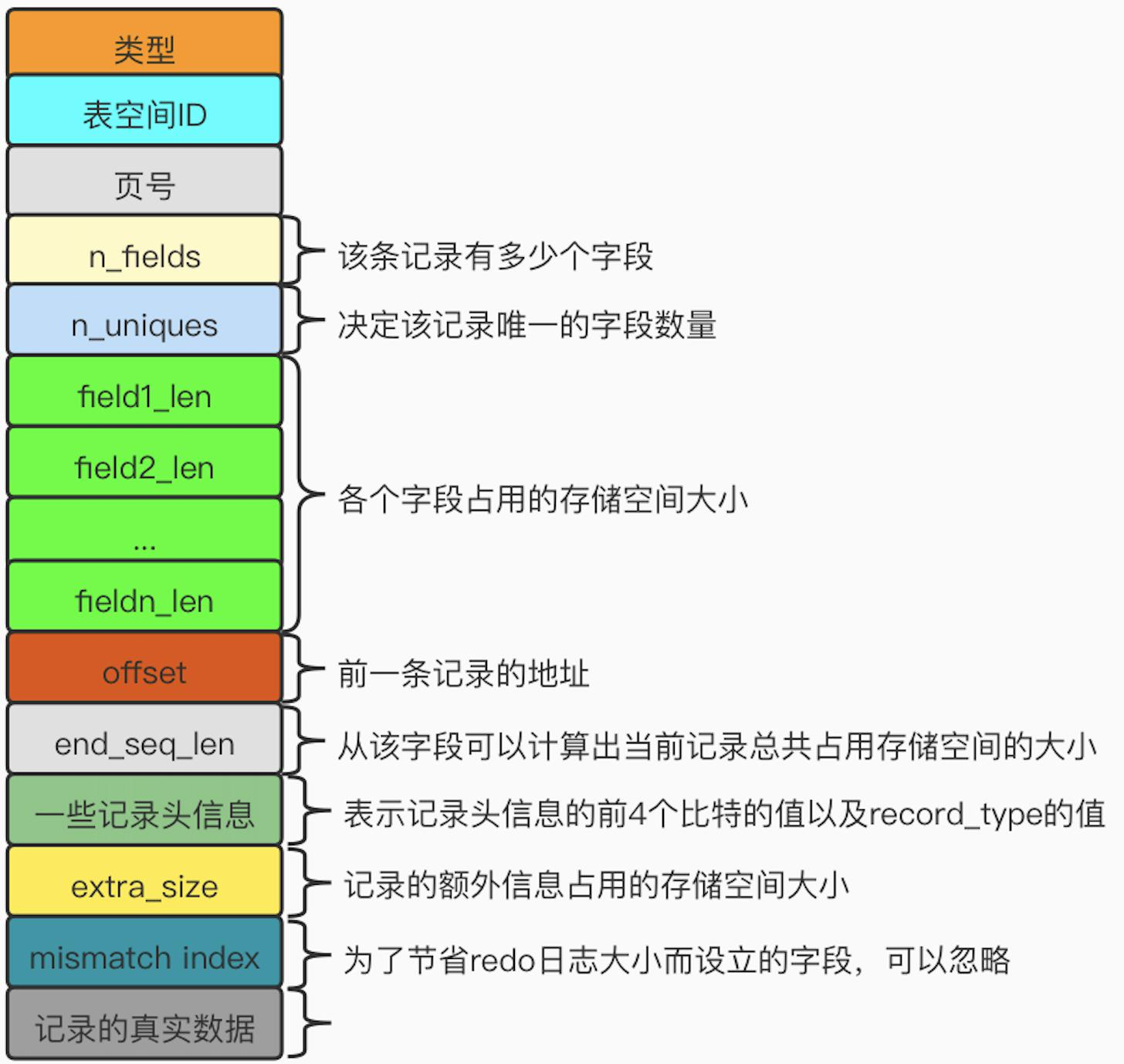
存在以下几种类型:
- MLOG_REC_INSERT(type = 9)(插入记录,非紧凑型)
- MLOG_COMP_REC_INSERT(type = 38)(插入记录,紧凑型)
- MLOG_COMP_PAGE_CREATE(type = 58)(创建页)
- MLOG_COMP_REC_DELETE(type = 42)(删除记录)
- MLOG_COMP_LIST_START_DELETE(type = 44)(指定开始位置删除)
- MLOG_COMP_LIST_END_DELETE(type = 43)(指定结束位置删除)
- MLOG_ZIP_PAGE_COMPRESS(type = 51)(压缩页)
redo 日志组
通过日志组来保证事务的一致性,具体的日志组结构如下图所示:
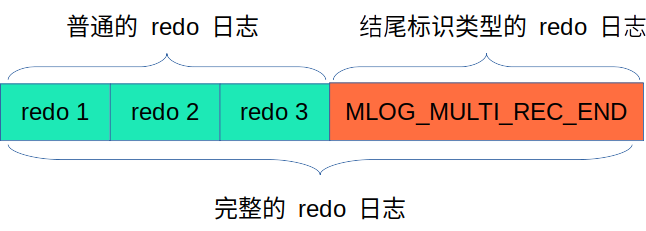
通过 MLOG_MULTI_REC_CORD 判断 redo 日志的组别,在 redo 时会将该字段前的所有 redo 日志视为一个事务中的操作(即再执行事务)。由于一个事务可能会存在多个对数据修改的操作,因此会有多条日志记录,简单的一条 redo 日志无法保证整个事务的原子性,必须使用日志组的方式才能实现
针对单条 redo 日志,单独放在一个日志组中可能过于浪费空间,为此,对于单条的 redo 日志,将会从 redo 日志的 “type” 字段中剥离一个位来表示该条日志是否是单条原子性操作,具体地,日志组中的 redo 日志的 ”type“ 字段的结构如下所示:
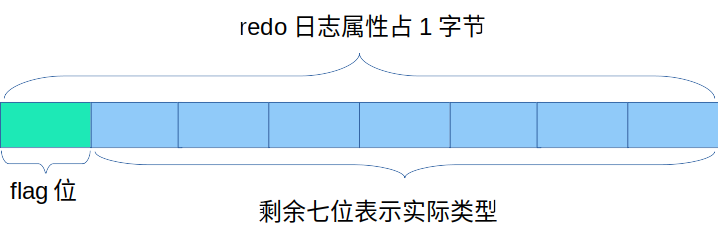
flag 位为 1,表示该 redo 日志是一个单条原子性的操作,为 0 则表示一般日志;通过该 flag 位,同样可以保证事务的一致性,因此当该 flag 位为 1 时,它将不属于一个 redo 日志组
redo 日志缓冲区
MTR
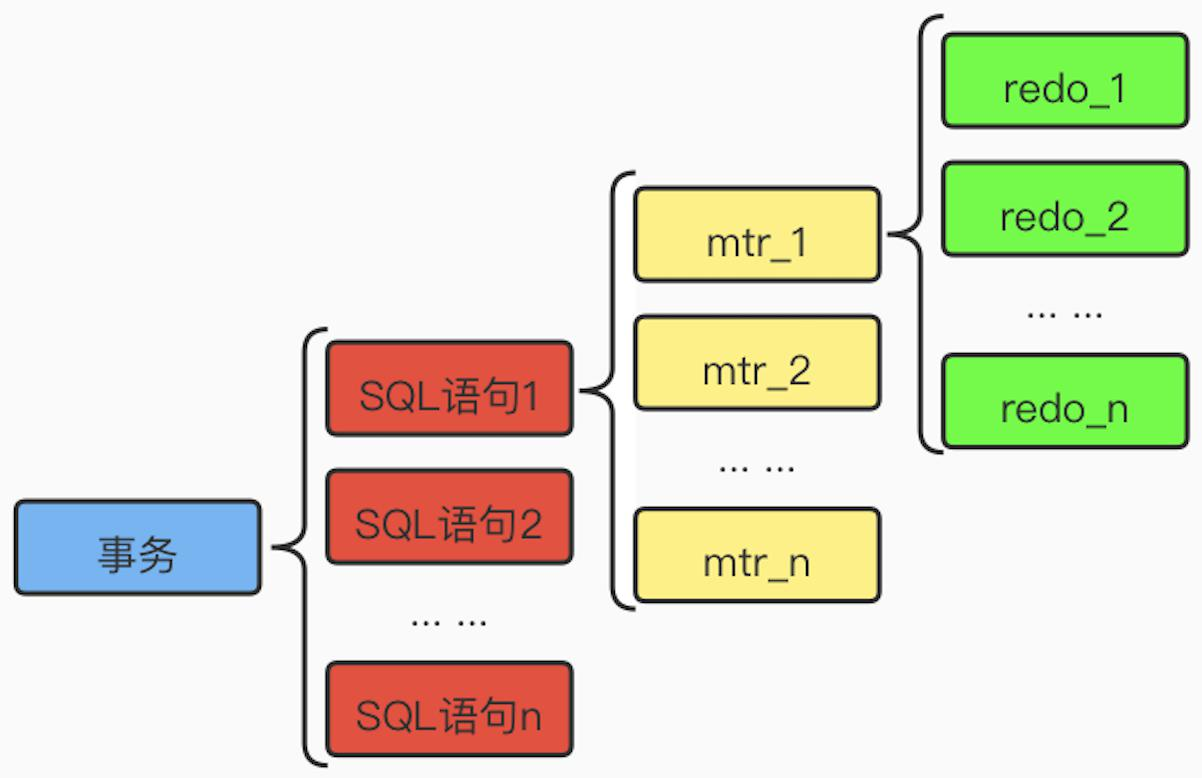
MTR(Mini—Transaction):对于底层 Page 的一次原子访问的过程被称为一个 Mini—Transaction
由于一个事务可以执行多个 SQL 语句,因此一个事务可以包含多个 MTR; MTR 可以包含多条 redo 日志,具体的对应关系如下图所示:
redo 日志块结构
redo 日志的块结构如下图所示:
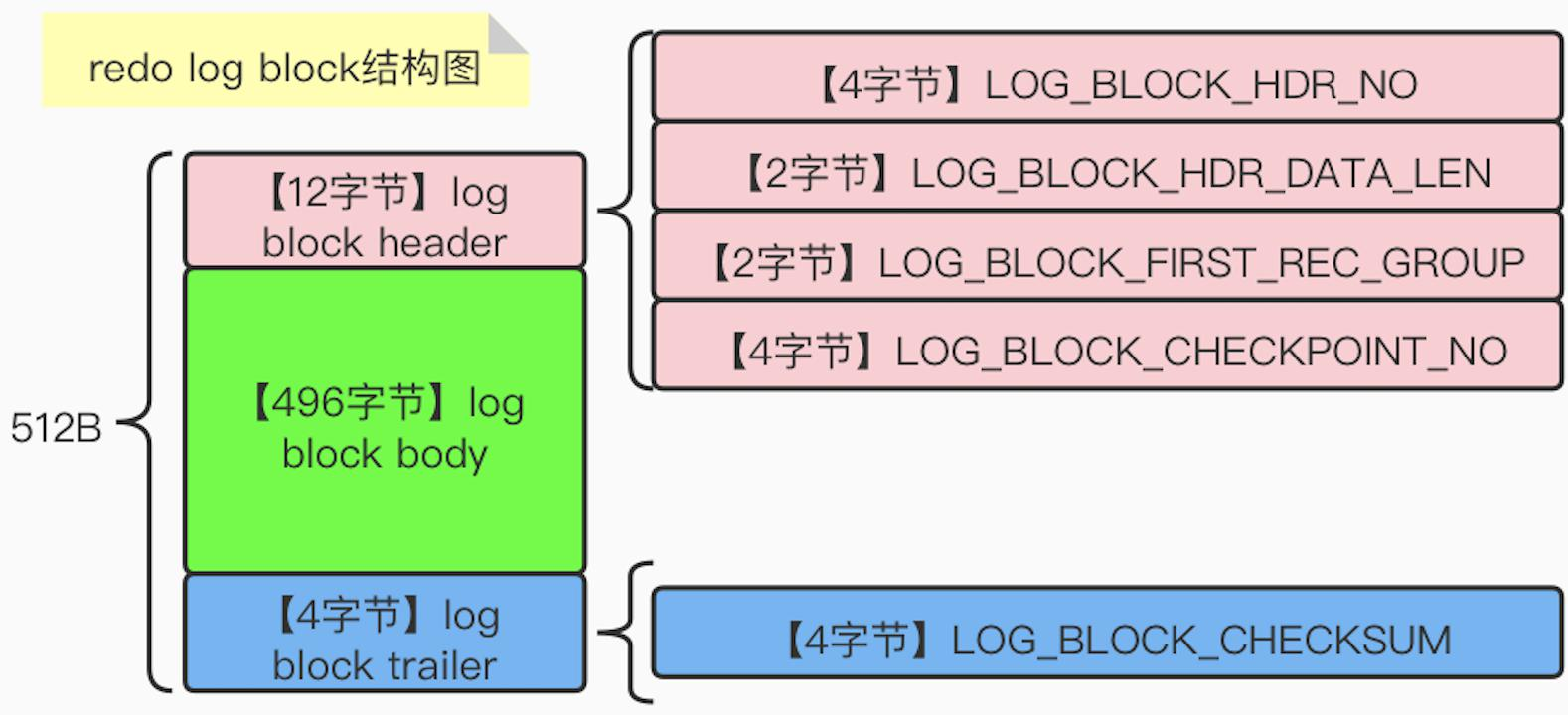
具体的关于 log block header 中的相关字段的介绍如下:
LOG_BLOCK_HDR_NO:块编号LOG_BLOCK_HDR_DATA_LEN:在 log block body 中实际存储的数据体的长度LOG_BLOCK_FIRST_REC_GROUP:对应的 MTR(参见 MTR 中 redo log 的对应关系)LOG_BLOCK_CHECKPOINT_NO:。。。。
这是组成 redo log buffer 的基本单位
redo log buffer
和 Page 类似,在将 redo log 写入到磁盘中时,不会直接与磁盘交互,而是首先将 redo log 写入到内存中的 buffer 区,再合适的时间通过后台线程再冲洗到磁盘上
redo log buffer 的组成如下图所示:
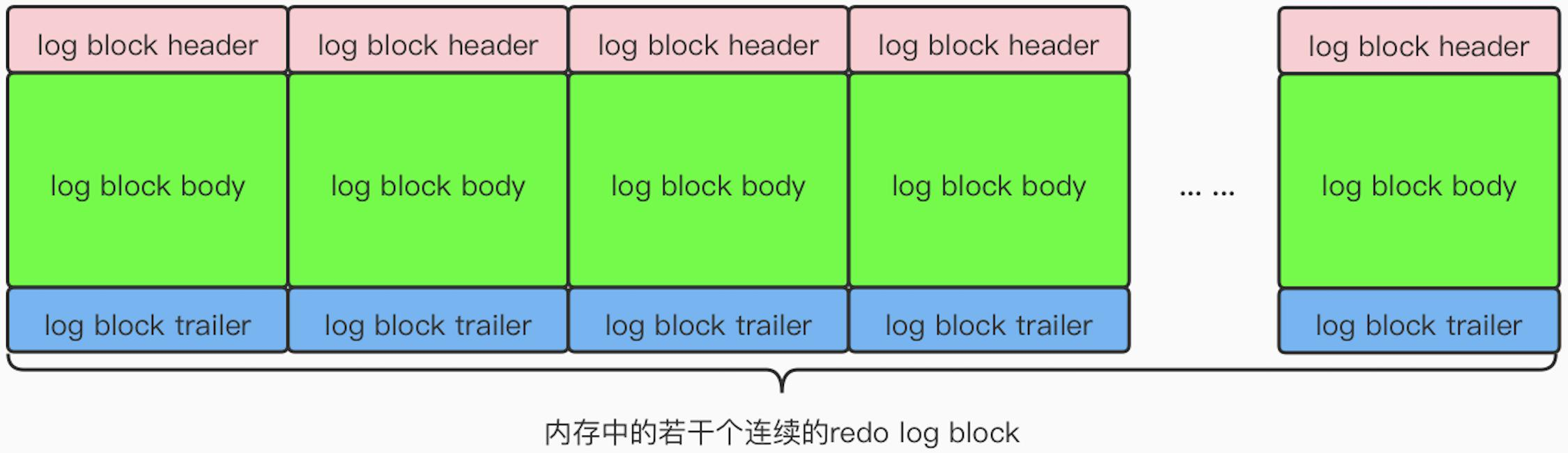
日志的写入过程:当提交事务时,会将事务的 MTR 分解写入,当有多个事务并发地提交时,MTR 的写入顺序将是不确定的
以下图为例,假设现在有两个事务 T1 和 T2,这两个事务分别存在两个 MTR :mtr_t1_1、mtr_t1_2 和 mtr_t2_1、mtr_t2_2,实际写入情况可能如下图所示:
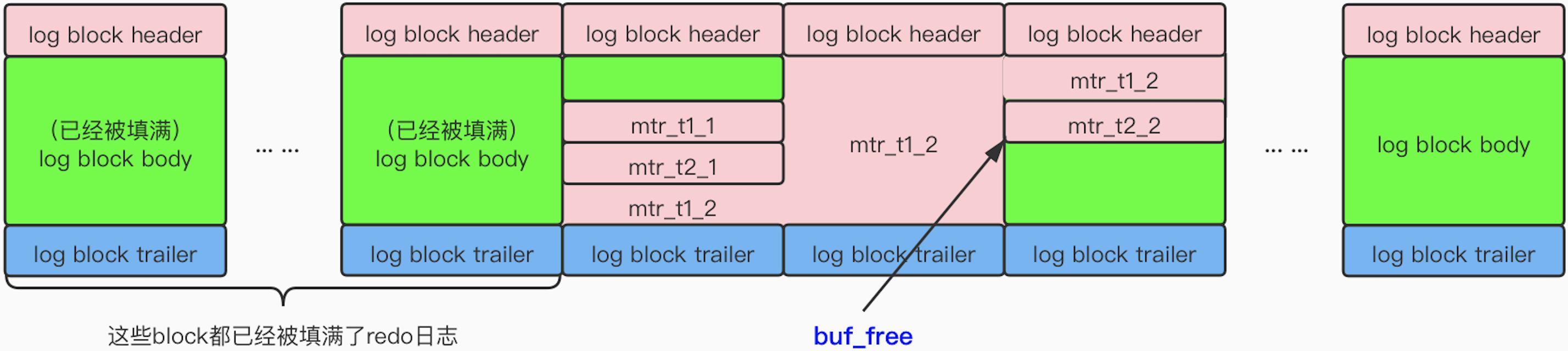
值得注意的是,为了保证内存的连续性,写入操作将是顺序的,可以看到,mtr_t1_2 由于内容较多,为了保证内存的顺序性,这会使得mtr_t1_2 会横跨多个 block 进行写入,尽管 mtr_t2_2 有机会在这个过程中写入,但是依旧需要等待来维持顺序写
具体地,一个事务提交时,写入 redo log 的步骤如下:开始事务——> 执行 SQL ——> 产生 redo log ——> redo log 聚集到 MTR 中 ——> 写入到 block ——> 写入到 log buffer
数据冲刷
在满足以下几种条件时,将会执行将 log buffer 中的内容冲刷到磁盘上的操作:
- log buffer 的可用空间不足 50% 的时候
- 事务提交
- 由于后台线程的存在,大约会以每秒一次的频率将 log buffer 中的内容写入到磁盘中
- 正常关闭服务器时
- 做 checkpoint 时
MySQL 会将 log buffer 中的内容写入到名称为 ib_logfile* 的文件中,默认情况下,MySQL 会使用使用到两个文件,当第一个文件写满时再写入下一个文件,当最后一个文件写满时,在写回到第一个日志文件,具体的情况如下图所示:
![]()
# 设置 redo log 文件的最大大小为 10 MB,设置的值应当在 4MB ~ 512GB 这个范围内
innodb_log_file_size = 10MB
# 设置 redo log 存储的文件的数量,范围为 2 ~ 100
innodb_log_files_in_group=4
redo log 文件格式
lsn (log sequence number):用于记录当前总共已经写入到 log buffer 的 redo 日志量,初始值为 8704
redo log 的文件格式如下图所示:
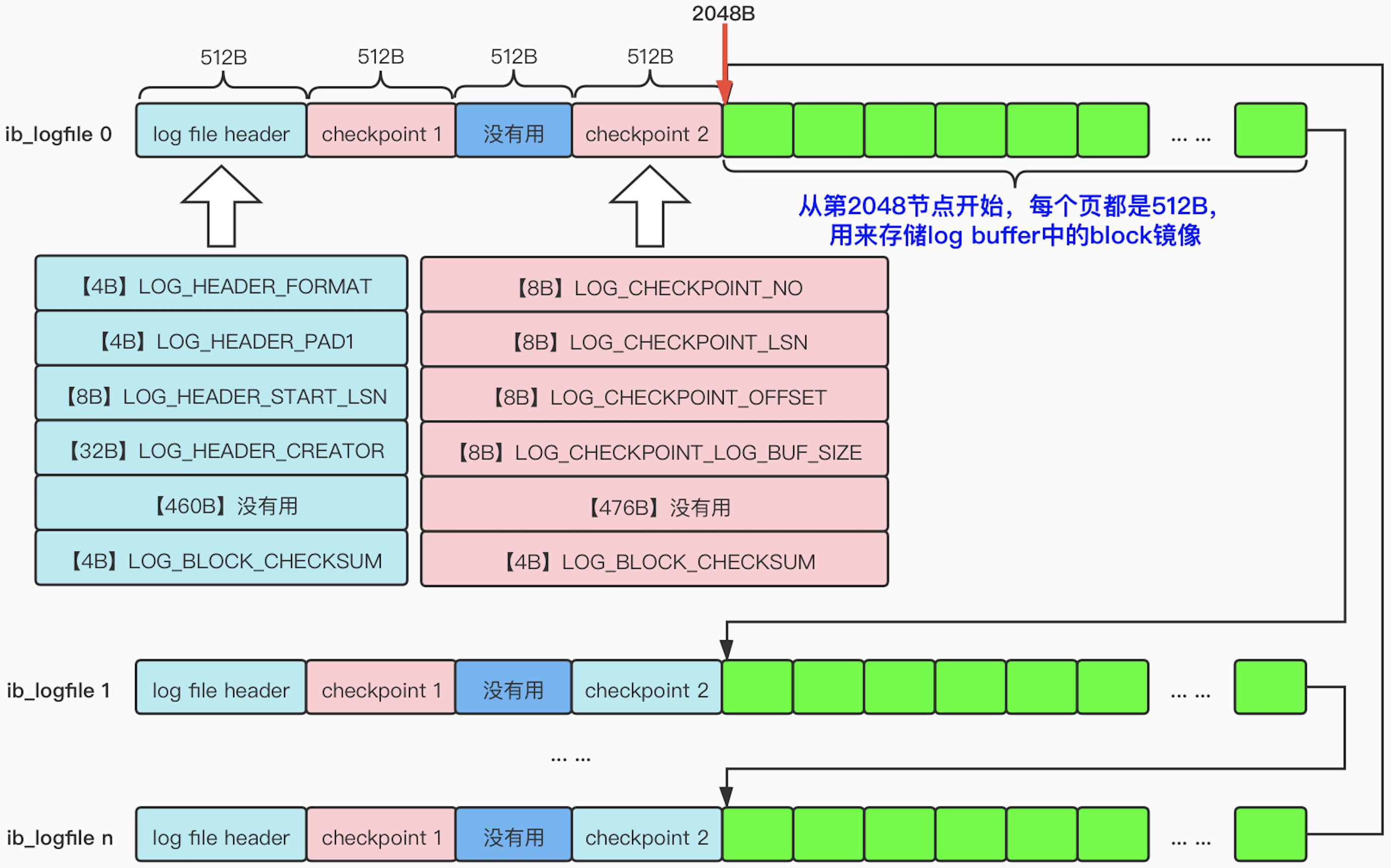
首先对于 log file header 部分,关键的字段如下:
LOG_HEADER_START_LSN:redo 日志具体内容距离文件开始位置的偏移量,默认为 2048(512*4)
对于 checkpoint 部分,关键的是两个字段:
LOG_CHECKPOINT_LSN:checkpoint 在文件中的偏移量LOG_CHECKPOINT_OFFSET:checkpoint 在日志组中的偏移量
undo 日志
redo log 用于处理容灾恢复的操作,主要是为了防止由于受到异常情况导致数据未能真正写入到磁盘而造成的数据丢失的情况,具体一点,就是说当事务提交时,需要有手段来保证数据的一致性。而 undo log 则是为了处理事务处理时出现异常,需要回滚事务的情况
需要明确的是,undo log 与 redo log 的不同点在于 undo log 的目的在于回滚数据,因此它保留的事务操作是和实际事务操作是相反的。
INSERT 对应的 undo log
使用 TRX_UNDO_INSERT_REC 日志结构,对应的具体结构如下图所示:

关键的字段解释如下:
undo no :从 0 开始计数,每生成一条 undo log,则增加这个字段的值
undo Type:该 undo log 所属的日志类型,在这里为
TRX_UNDO_INSERT_RECtable id : 在
information_schema.INNODB_TABLES中可以查看对应的 Table Id,该字段值由 MySQL 自动生成主键各列信息:以
<len, value>组成的映射关系,其中len表示主键字段类型的长度,value表示实际值
DELETE 对应的 undo log
删除操作对应的日志结构为 TRX_UNDO_DEL_MARK_REC,具体的结构如下图所示:

关键的字段解释如下:
- info bits:记录头信息比特位(不太重要)
- len of index_col_info:索引列每列的字段长度总和(主键索引、二级索引)
- 索引的各列信息:
pos表示在记录中相对于真实记录数据的开始位置,比如,trx_id为 1,roller_pointer为 2
删除一条记录的一般步骤如下:
- delete mark 阶段,这个阶段会将待删除的记录的
deleted_flag标记置为 1,表示这条记录在逻辑上已经被删除了,但是此时这条记录并没有直接进入到PAGE_FREE(垃圾链表)中,即上一条记录与这条记录之间的链接关系依旧存在 - purge 阶段,当提交
DELETE事务时,MySQL 会通过专门的线程将记录链表中deleted_flag标记为 1 的记录从记录链表中移除出来,然后加入到垃圾链表中,作为垃圾链表的头节点
执行删除操作之后对应的 undo log 的内容可能类似下图所示:

为了保证能够恢复数据,通过 roll_pointer 指向对应的删除的记录的插入 undo log
对于已经移除的记录对应的内存空间,这部分的内存空间是可以被重新使用的:
- 回忆一下
Page的结构,在Page的Page Header中存在一个名为PAGE_GABAGE的属性,该属性记录着当前的页面中可复用的内存的总字节数(即已经移除到垃圾链表的所有记录再当前 Page 中所占的内存总和),每当有记录从Page移动到垃圾链表时,都会将对应的记录所占的总字节数加到PAGE_GABAGE中 - 每当新插入数据时,首先判断垃圾链表的头节点的记录的空间大小是否能够容纳新插入的记录,如果可以容纳那么直接将这条新的记录放入到原来已经移除的记录的空间中,再调整记录链表;如果空间不足以容纳新插入的记录,那么直接申请一块新的空间来放入这条记录
- 如果插入数据时当前的
Page的可申请空间不足,那么将会首先会通过PAGE_GABAGE和Free Space的总和来判断是否有足够的空间来放入这条新的记录,如果空间足够,那么首先创建一个临时Page,将当前Page的内容以及新插入的记录复制到临时Page中,然后再从临时Page复制到当前Page,类似于 “标记—复制” 算法
UPDATE 对应的 undo log
UPDATE 操作对应的 undo log 日志类型为 TRX_UNDO_UPD_EXIST_REC, 对应的结构如下图所示:

关键的几个字段的介绍如下:
n_updated:本次
UPDATE语句更新的记录的数量被更新的列更新前的信息:
<pos, old_len, old_value>列表,表示更新列在记录中的位置,更新前该列占用的存储空间的大小,更新前该列的真实值
针对主键的更新操作,InnoDB 对于更新主键和不更新主键这两种情况有不同的处理方式:
不更新主键
如果对于本次记录的更新不会修改主键,那么就会根据更新数据的大小来决定采用 “就地更新” 的方式还是采用 “删除旧记录,再插入新记录” 的方式
就地更新
在更新记录时,对于被更新的每个列来说,如果更新之后的列与更新前的列占用的存储空间一样大,那么就可以就地更新,即直接在原有记录的基础上完成对应列的修改。这是一种最为理想的方式,最终在
roll_pointer中引用一条旧数据的更新日志即可删除旧记录,再插入新记录
如果更新的记录中有任意一列的大小在更新前后不一致,那么就需要首先将这条记录从 Page 中删除,然后再根据更新列之后的值创建一条新的记录再插入到 Page 中
值得注意的是,这里的删除通过
DELETE语句来执行删除操作不同,这里的删除操作是直接将这条记录从记录链表中移动到垃圾链表中,没有设置deleted_flag这个标记步骤,同时,这里的删除也是通过用户线程显式地来删除,而不是通过purge操作时使用的专有线程。如果新创建的记录占用的空间不超过旧记录所占用的空间,那么就可以直接重用原有的旧记录使用到的空间而无需显式地去请求分配内存空间;如果新记录占用的空间超过了原有记录占用的内存空间,那么就需要在 Page 中新申请一块空间供新记录使用;如果当前 Page 已经没有足够的可用空间,那么就需要执行 Page 分裂操作,再将插入新的记录
更新主键
分为以下两个步骤:
- 将旧记录进行 delete mark 操作,即将该记录的
deleted_flag置为 1,只有当当前事务提交时,才会有专门的线程执行purge操作。这是由于可能当前的记录被多个事务所并发地访问,直接purge将会导致别的事务出现不可预见的问题 - 根据更新后各个列的值创建一条新的记录,并将其插入到聚簇索引中
针对更新主键这种类型的操作,首先在 delete mark 阶段会记录一条
TRX_UNDO_DEL_MARK_REC的删除 undo log,然后再插入新的数据时会产生一条TRX_UNDO_INSERT_REC的插入 undo log,即,每次对主键的更新都会产生两条 undo log- 将旧记录进行 delete mark 操作,即将该记录的
MySQL 基础(二)日志的更多相关文章
- 02 mysql 基础二 (进阶)
mysql 基础二 阶段一 表约束 1.not null 非空约束 例子: create table tb1( id int, name varchar(20) not null ); 注意 空字符不 ...
- mysql基础之日志管理(查询日志、慢查询日志、错误日志、二进制日志、中继日志、事务日志)
日志文件记录了MySQL数据库的各种类型的活动,MySQL数据库中常见的日志文件有 查询日志,慢查询日志,错误日志,二进制日志,中继日志 ,事务日志. 修改配置或者想要使配置永久生效需将内容写入配置文 ...
- MySQL基础二
视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,并可以将其当作表来使用. SELECT * FROM ( SEL ...
- Mysql基础(二)
多表连接 #多表查询 /* sql99标准 等值连接 ①多表等值连接的结果为多表的交集部分 ② n个连接至少需要 n-1个连接 ③一般需要为表起别名 ④可以搭配前面介绍的所有子句的使用,比如排序,分组 ...
- MySQL 基础二 创建表格
1.界面创建 2.SQL创建 教程地址:http://blog.csdn.net/brucexia/article/details/53738596 提供学习视频下载 链接:http://pan.ba ...
- (3.12)mysql基础深入——mysql日志文件/其他文件(socket/pid/表结构/Innodb)
(3.12)mysql基础深入——mysql日志文件/其他文件(socket/pid/表结构/Innodb) 关键词:mysql日志文件,mysqldumpslow分析工具 目录:日志文件的分类 1. ...
- Linux系统——MySQL基础(二)
# MySQL数据库完全备份与恢复## 数据库备份的分类1. 从物理与逻辑的角度,备份可以分为物理备份和逻辑备份.(1)物理备份:对数据库操作系统的物理文件(数据文件.日志文件)的备份.物理备份又可分 ...
- MySQL基础(二)——DDL语句
MySQL基础(二)--DDL语句 1.什么是DDL语句,以及DDL语句的作用 DDL语句时操作数据库对象的语句,这些操作包括create.drop.alter(创建.删除.修改)数据库对象. 2.基 ...
- { MySQL基础数据类型}一 介绍 二 数值类型 三 日期类型 四 字符串类型 五 枚举类型与集合类型
MySQL基础数据类型 阅读目录 一 介绍 二 数值类型 三 日期类型 四 字符串类型 五 枚举类型与集合类型 一 介绍 存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己 ...
- (3.14)mysql基础深入——mysql 日志分析工具之pt-querty-digest【待完善】
(3.14)mysql基础深入——mysql 日志分析工具之pt-querty-digest 关键字:Mysql日志分析工具.mysqlsla 常用工具 [1]mysqldumpslow:官方提供的慢 ...
随机推荐
- MySQL实战实战系列 07 行锁功过:怎么减少行锁对性能的影响?
在上一篇文章中,我跟你介绍了 MySQL 的全局锁和表级锁,今天我们就来讲讲 MySQL 的行锁. MySQL 的行锁是在引擎层由各个引擎自己实现的.但并不是所有的引擎都支持行锁,比如 MyISAM ...
- 起风了,NCC 云原生项目孵化计划
时间回到 2016 年,彼时 .NET Core 1.0 刚刚发布 1.0 版本,我跟几位好友共同发起 .NET Core 中文学习组(.NET Core China Studying Group)和 ...
- FreeRTOS 中的调度算法
FreeRTOS 中的调度算法 01 调度算法概述 调度算法的作用: 实时系统的调度需求 相应时间要求 任务优先级 资源利用率 FreeRTOS 调度算法的目标 提供可预测的任务调度 实现任务的优先级 ...
- nittest单元测试框架—加载测试用例的3种方法以及测试报告存储管理
项目结构 测试用例 import unittest class LoginTestCase(unittest.TestCase): def test_login_success(self): self ...
- 一次考试的T3
啊这感觉不太可做观察性质,发现这个字符串只由ABC构成这个性质必须利用仅仅由3种字符组成意味着什么呢?这个字符串只有种可能性这个有什么用呢?只是说明暴力枚举的时间复杂度会小一些而已.不止是这些. 首先 ...
- [NOI2014] 字符串(题解)
字符串(题解) 题目描述 近日,园长发现动物园中好吃懒做的动物越来越多了.例如企鹅,只会卖萌向游客要吃的.为了整治动物园的不良风气,让动物们凭自己的真才实学向游客要吃的,园长决定开设算法班,让动物们学 ...
- CF755C
题目简化和分析: 这题不用说怎么分析了吧,这一看就是个并查集求连通分量个数的经典模板. 我们需要将 \(i\) 和 \(p_i\) 进行合并. 遍历每个 \(i\) 与 \(i+1\) 是否属于同一个 ...
- 给wordpress后台侧栏菜单添加自定义字段的方法
我们在使用wordpress做网站的时候,难免有一些需要在后台设置侧栏菜单下添加自定义字段的情况.下面就简单说说一下,如何在后台设置侧栏菜单下添加自定义字段? 在这里我们主要是使用wordpress的 ...
- TerraMoursGPT V1.0 开发总结
TerraMoursGPT V1.0 开发总结 TerraMoursGPT V1.0 是之前gpt项目基于TerraMours后端框架的重构,实现用户登陆和基于SK的多语言模型聊天.基于chatgpt ...
- QT(9)-QStyleOption及其子类
1 QStyleOption QStyleOption及其子类包含QStyle函数绘制图形元素所需的所有信息. 出于性能考虑,成员函数很少,对成员变量的访问是直接的(即使用.或者->运算符).这 ...