MySQL索引Innodb存储引擎
MySQL索引优化
一、基础理解
MySQL语句的查询效率主要和索引树的高度有关,想要降低查询的次数提高查询的速度,减少直接对磁盘的I/O流的次数,就要让索引树的高度越低越好。
索引的定义:索引是帮助MySQL高效获取数据的排好序的数据结构。
1、innodb存储引擎
- 使用B+树,表数据文件本身就是按B+Tree组织的一个索引结构文件。
- 聚集索引---叶子节点包含了完整的数据记录。
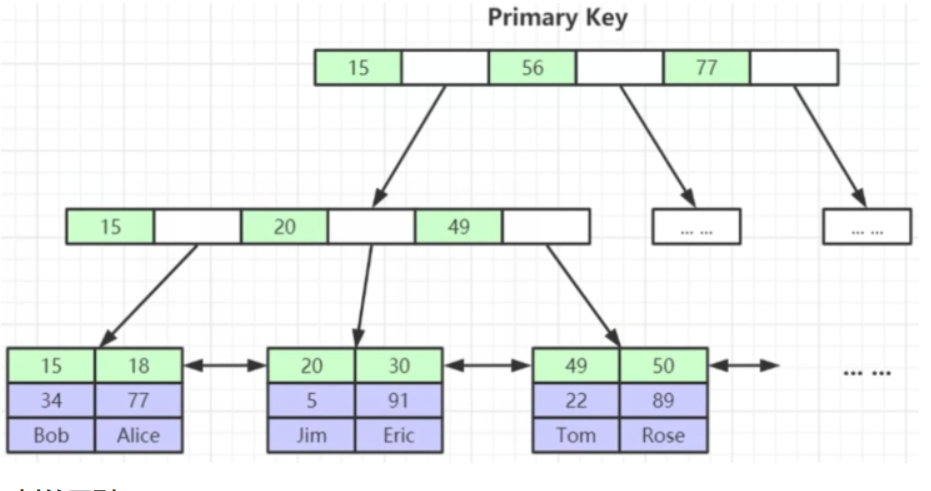
1.1、B+树和B树的区别
- 非叶子节点不存储data,只存储冗余索引,可以放更多的索引
- 叶子节点包含所有的索引字段。
- 叶子节点用双向指针连接,提高区间访问性能。
2、思考问题
2.1、为什么建议Innodb表必须建主键,并且推荐使用整型的自增主键?
- 聚集索引、聚簇索引:索引文件和数据文件是聚集在一起的,(非聚集索引的数据文件和索引文件是分离的)。
- 主键索引:主键索引下存储的是所有数据值。
- 非主键索引:非主键索引下存储的是主键值。
- 建主键的原因:Innodb的设计初衷就是根据主键来建立索引来整理和组织整个数据表。
- 如果用户创建了一个没有主键的表,那么数据库会自动搜寻所有列的数据,去帮助你找到一列没有重复值,适合作为整张表的主键的数据列来根据这一列数据组织整张表的数据。
- 如果找不到一列适合做主键的数据列,那么mysql会自动在后台维护一个主键列,这个主键列就是一个整型的自增的变量。
- 使用整型自增主键的好处:查询遍历效率高,使用整型去比较大小要快。
- 自增的原因:因为B+树的构建过程是要保证数据有序,从大到小,所以最好使用从小到大的有序数据。
2.2、为什么非主键索引结构叶子节点存储的是主键值?
- 保证一致性,节省存储空间
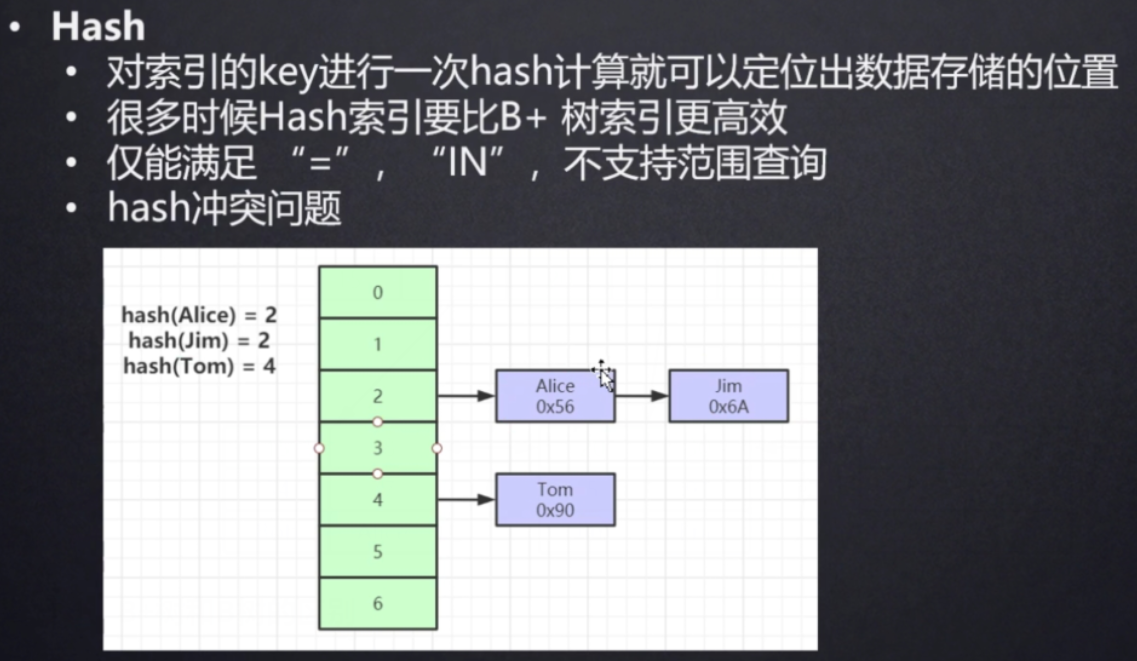
二、hash索引原理
- 对索引的key进行一次hash计算就可以定位出数据存储的位置。
- 很多时候hash索引比B+树索引更加高效。
- 仅仅满足“=”、”IN“,不支持范围查询。
- 存在hash冲突(两个数据计算得出的hash值相同)问题。
三、B树和B+树
1、概念
首先,B树不要和二叉树混淆,在计算机科学中,B树是一种自平衡树数据结构,它维护有序数据并允许以对数时间进行搜索,顺序访问,插入和删除。B树是二叉搜索树的一般化,因为节点可以有两个以上的子节点。与其他自平衡二进制搜索树不同,B树非常适合读取和写入相对较大的数据块(如光盘)的存储系统。它通常用于数据库和文件系统。
2、B树定义
B树是一种平衡的多分树,通常我们说m阶的B树,它必须满足如下条件:
- 每个节点最多只有m个子节点。
- 每个非叶子节点(除了根)具有至少⌈ m/2⌉子节点。
- 如果根不是叶节点,则根至少有两个子节点。
- 具有k个子节点的非叶节点包含k -1个键。
- 所有叶子都出现在同一水平,没有任何信息(高度一致)。

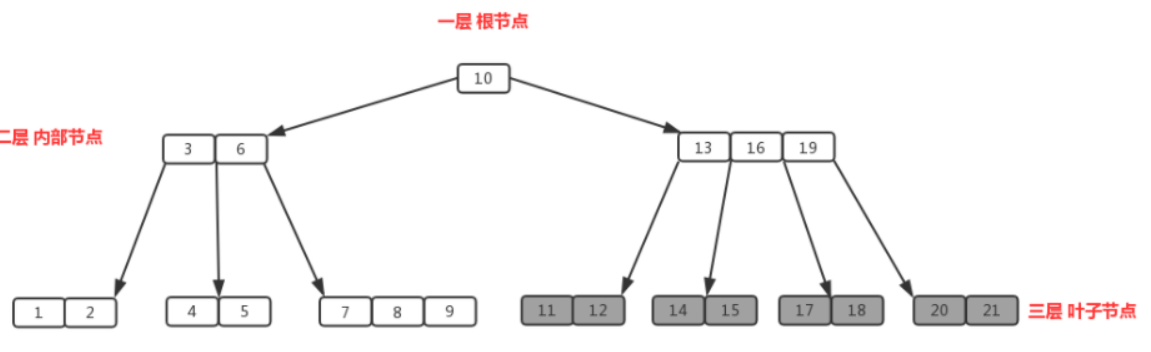
所有节点中,节点【13,16,19】拥有的子节点数目最多,四个子节点(灰色节点),所以可以定义上面的图片为4阶B树,现在懂什么是阶了吧
什么是根节点 ?
节点【10】即为根节点,特征:根节点拥有的子节点数量的上限和内部节点相同,如果根节点不是树中唯一节点的话,至少有两个个子节点(不然就变成单支了)。在m阶B树中(根节点非树中唯一节点),那么有关系式2<= M <=m,M为子节点数量;包含的元素数量 1<= K <=m-1,K为元素数量。
什么是内部节点 ?
节点【13,16,19】、节点【3,6】都为内部节点,特征:内部节点是除叶子节点和根节点之外的所有节点,拥有父节点和子节点。假定m阶B树的内部节点的子节点数量为M,则一定要符合(m/2)<= M <=m关系式,包含元素数量M-1;包含的元素数量 (m/2)-1<= K <=m-1,K为元素数量。m/2向上取整。
什么是叶子节点?
节点【1,2】、节点【11,12】等最后一层都为叶子节点,叶子节点对元素的数量有相同的限制,但是没有子节点,也没有指向子节点的指针。特征:在m阶B树中叶子节点的元素符合(m/2)-1<= K <=m-1。
插入
针对m阶高度h的B树,插入一个元素时,首先在B树中是否存在,如果不存在,即在叶子结点处结束,然后在叶子结点中插入该新的元素。
- 若该节点元素个数小于m-1,直接插入;
- 若该节点元素个数等于m-1,引起节点分裂;以该节点中间元素为分界,取中间元素(偶数个数,中间两个随机选取)插入到父节点中;
- 重复上面动作,直到所有节点符合B树的规则;最坏的情况一直分裂到根节点,生成新的根节点,高度增加1;
上面三段话为插入动作的核心,接下来以5阶B树为例,详细讲解插入的动作;
5阶B树关键点:
- 2<=根节点子节点个数<=5
- 3<=内节点子节点个数<=5
- 1<=根节点元素个数<=4
- 2<=非根节点元素个数<=4
 插入8
插入8 
图(1)插入元素【8】后变为图(2),此时根节点元素个数为5,不符合 1<=根节点元素个数<=4,进行分裂(真实情况是先分裂,然后插入元素,这里是为了直观而先插入元素,下面的操作都一样,不再赘述),取节点中间元素【7】,加入到父节点,左右分裂为2个节点,如图(3)

接着插入元素【5】,【11】,【17】时,不需要任何分裂操作,如图(4)

插入元素【13】

节点元素超出最大数量,进行分裂,提取中间元素【13】,插入到父节点当中,如图(6)

接着插入元素【6】,【12】,【20】,【23】时,不需要任何分裂操作,如图(7)

插入【26】时,最右的叶子结点空间满了,需要进行分裂操作,中间元素【20】上移到父节点中,注意通过上移中间元素,树最终还是保持平衡,分裂结果的结点存在2个关键字元素。

插入【4】时,导致最左边的叶子结点被分裂,【4】恰好也是中间元素,上移到父节点中,然后元素【16】,【18】,【24】,【25】陆续插入不需要任何分裂操作

最后,当插入【19】时,含有【14】,【16】,【17】,【18】的结点需要分裂,把中间元素【17】上移到父节点中,但是情况来了,父节点中空间已经满了,所以也要进行分裂,将父节点中的中间元素【13】上移到新形成的根结点中,这样具体插入操作的完成。

3、B+树定义
B+树的特征:
- 有m个子树的中间节点包含有m个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引;
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息);
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息);


参考:https://blog.csdn.net/qq_35349114/article/details/96157931
MySQL索引Innodb存储引擎的更多相关文章
- MySQL:InnoDB存储引擎的B+树索引算法
很早之前,就从学校的图书馆借了MySQL技术内幕,InnoDB存储引擎这本书,但一直草草阅读,做的笔记也有些凌乱,趁着现在大四了,课程稍微少了一点,整理一下笔记,按照专题写一些,加深一下印象,不枉读了 ...
- MySQL数据库InnoDB存储引擎多版本控制(MVCC)实现原理分析
文/何登成 导读: 来自网易研究院的MySQL内核技术研究人何登成,把MySQL数据库InnoDB存储引擎的多版本控制(简称:MVCC)实现原理,做了深入的研究与详细的文字图表分析,方便大家理解I ...
- MySQL数据库InnoDB存储引擎中的锁机制
MySQL数据库InnoDB存储引擎中的锁机制 http://www.uml.org.cn/sjjm/201205302.asp 00 – 基本概念 当并发事务同时访问一个资源的时候,有可能 ...
- mysql中InnoDB存储引擎的行锁和表锁
Mysql的InnoDB存储引擎支持事务,默认是行锁.因为这个特性,所以数据库支持高并发,但是如果InnoDB更新数据的时候不是行锁,而是表锁的话,那么其并发性会大打折扣,而且也可能导致你的程序出错. ...
- MySQL 温故而知新--Innodb存储引擎中的锁
近期碰到非常多锁问题.所以攻克了后,细致再去阅读了关于锁的书籍,整理例如以下:1,锁的种类 Innodb存储引擎实现了例如以下2种标准的行级锁: ? 共享锁(S lock),同意事务读取一行数据. ? ...
- mysql之innodb存储引擎
mysql之innodb存储引擎 innodb和myisam区别 1>.InnoDB支持事物,而MyISAM不支持事物 2>.InnoDB支持行级锁,而MyISAM支持表级锁 3>. ...
- MySql中innodb存储引擎事务日志详解
分析下MySql中innodb存储引擎是如何通过日志来实现事务的? Mysql会最大程度的使用缓存机制来提高数据库的访问效率,但是万一数据库发生断电,因为缓存的数据没有写入磁盘,导致缓存在内存中的数据 ...
- MySQL数据库InnoDB存储引擎
MySQL数据库InnoDB存储引擎Log漫游 http://blog.163.com/zihuan_xuan/blog/static/1287942432012366293667/
- mysql之innodb存储引擎---BTREE索引实现
在阅读本篇文章可能需要一些B树和B+树的基础 一.B树和B+树的区别 1.B树的键值不会出现多次,而B+树的键值一定会出现在叶子节点上,而且在非叶子节点也可能会重复出现2.B数存储真实数据,B+数叶子 ...
- 在MySQL的InnoDB存储引擎中count(*)函数的优化
写这篇文章之前已经看过了很多数据库方面的优化内容,大部分都是加索引.使用事务.要什么select什么等等.然而,只是停留在阅读的层面上,很少有实践,因为没有遇到真实的项目,一切都是纸上谈兵.实践是检验 ...
随机推荐
- Python之密码生成器
介绍 这段程序用来随机批量生成一批安全性相对较高的密码,要了解你当前使用的密码强度到底如何? 可以试一下这个网站: https://howsecureismypassword.net/ 他会告诉你计算 ...
- virtualbox中linux设置NAT和Host-Only上网(实现双机互通同时可上外网)
关于虚拟机中几种网络连接方式请参考其他教程. 平常,我们安装好虚机,用桥接方式也就够了.毕竟它能上内网和外网. 但是有个问题,如果你的网络环境发生变化,虚机的Ip也会随之改变(桥接的Ip和主机ip必须 ...
- win32 - 创建带有标准阴影的无边框窗口
这个框框好像删不掉,就先放这边吧... #define WIN32_LEAN_AND_MEAN #include <unknwn.h> #include <windows.h&g ...
- Fpga开发笔记(二):高云FPGA发开发软件Gowin和高云fpga基本开发过程
前言 本篇安装高云的开发软件Gowin,并且描述了一个基于高云fpga的程序的开发环境和完整的下载运行过程. Gowin软件 概述 Gowin 软件是广东高云半导体股份有限公司的 FPGA ...
- Hi3516开发笔记(十一):通过HiTools使用网口将uboot、kernel、roofts烧写进eMMC
前言 前面烧写一直时烧写进入flush,是按照分区烧写.定制的板子挂的是eMMC,前面的烧写步骤一致,但是在烧写目标则时烧写eMMC了. 重新走一遍从无到有通过网口刷定制板卡的uboot.ker ...
- 第131篇:如何上传一个npm包
好家伙, NPM的全称是Node Package Manager,是一个NodeJS包管理和分发工具,已经成为了非官方的发布Node模块(包)的标准. NPM是世界上最大的软件注册表. 1.首先我们 ...
- HttpClient实现https调用
在HttpClient 4.x版本中引入了大量的构造器设计模式 https请求建立详解 首先建立一个信任任何密钥的策略.代码很简单,不去考虑证书链和授权类型,均认为是受信任的: class AnyTr ...
- 【Azure 环境】向Azure Key Vault中导入证书有输入密码,那么导出pfx证书的时候,为什么没有密码呢?
问题描述 将pfx证书导入Key Vault的证书时,这个PFX需要输入正确的密码导入成功.但是当需要导出时,生成的pfx证书则不需要密码.这是正常的情况吗? 问题解答 是的,这是Azure Key ...
- For 循环跟yield区别?
for循环遍历一个万亿级别的长列表,会将这个列表的全部数据载入到内存中去,如果你的内存很小就会溢出,即使是内存很大,这个操作也是十分占用资源的. 而使用生成器,则会将数据的状态(例如:遍历到列表的哪个 ...
- Java 常用类 JDK 8 之前日期和时间的API测试
1 package com.bytezero.stringclass; 2 3 import org.junit.Test; 4 5 import java.util.Date; 6 7 8 /** ...