【信创】 JED on 鲲鹏(ARM) 调优步骤与成果
项目背景
基于国家对信创项目的大力推进,为了自主可控的技术发展,基础组件将逐步由国产组件替代,因此从数据库入手,将弹性库JED部署在 国产华为鲲鹏机器上(基于ARM架构)进行调优,与Intel (X86)进行性能对比。
物理机配置
| 处理器厂商 | 架构设计 | CPU型号 | CPU | 睿频 | 内存频率 | 操作系统 |
|---|---|---|---|---|---|---|
| 华为 | ARM | kunpeng920-7262C | 128C | 无 | 3200 MT/s | 欧拉 |
| Intel | X86 | platium-8338C-3rd | 128C | 开启 | 3200 MT/s | centos 8 |
| Intel | X86 | platium-8338C-3rd | 128C | 开启 | 3200 MT/s | centos 8 |
数据库配置
| 部署机房 | 廊坊 |
|---|---|
| 部署方式 | 容器 |
| 网关配置 | 16C/12G 磁盘:/export:30G |
| 数据库架构 | 1个集群,一主一从 |
| 数据库配置 | 8C/24G 磁盘:/export:512G |
调优成果
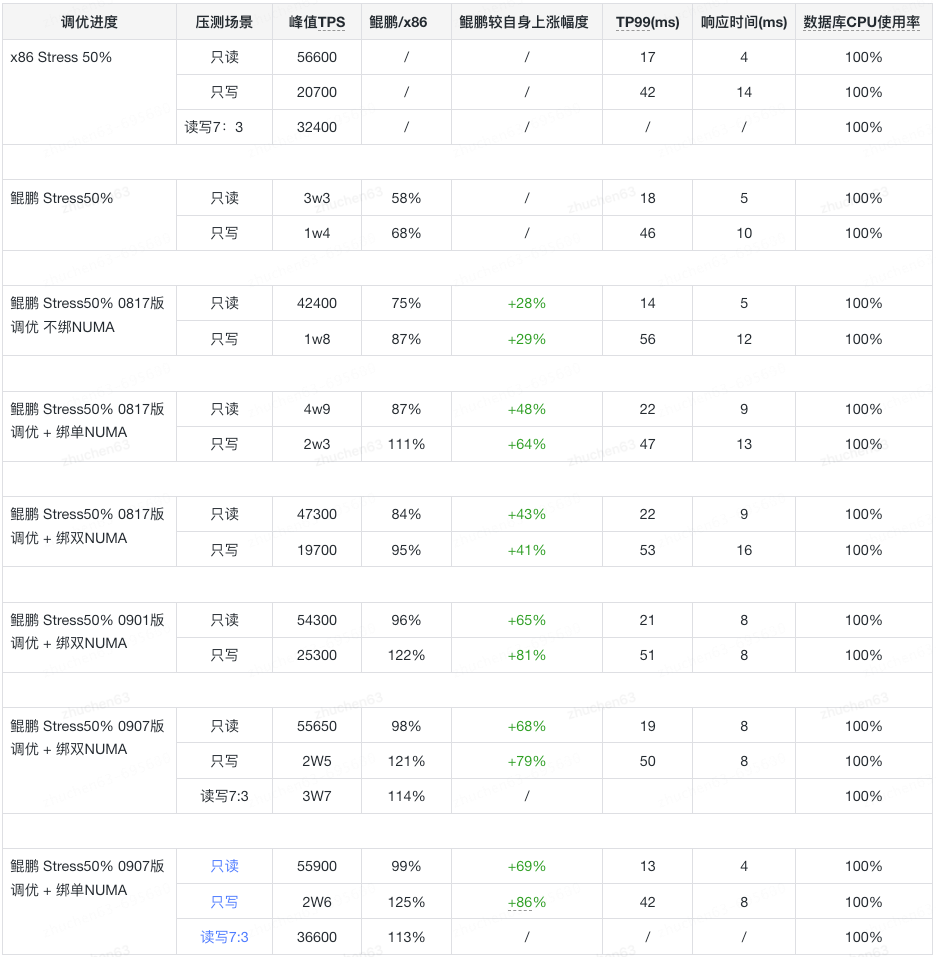
调优前:背景压力50%时,JED on 鲲鹏 读性能是 Intel 的 58%,写性能为68%
调优后: JED on 鲲鹏读性能至 Intel的99%,写性能至 Intel 的 121%,读写混合7:3时达到113% ,TP99和响应时间表现较优,数据库CPU使用率此时均达100%,调优过程中的主要场景与性能数据记录如下:
具体调优流程
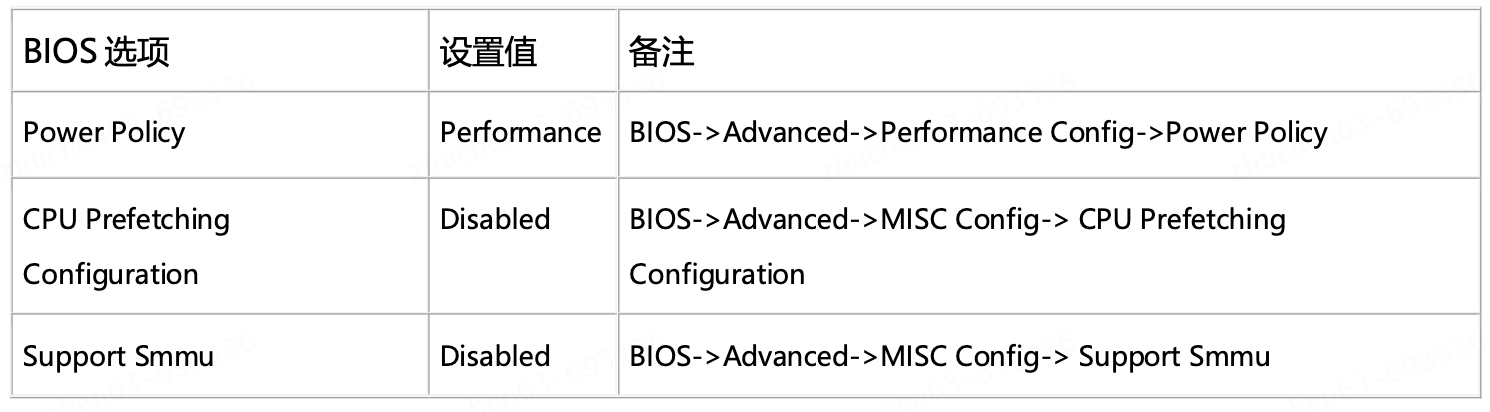
1、BIOS优化
需要机房修改,并重启宿主机
预期:CPU prefetching 对数据库性能有影响,需要关闭; Power Policy 开箱即为Performance;Smmu可不关闭
2、宿主机pagesize改大页 4K改为64K
原配置:


页表大小对数据库性能有影响,请确认 x86 和鲲鹏的宿主机系统的页表大小是否一致 更改宿主机操作系统的页表大小需要重新编译内核,不同 OS 上操作有差异,可与运维团队 联系更改
rpm -ivh http://storage.jd.local/k8s-node/kernel/5.10-jd_614-arm64/kernel-5.10.0-1.64kb.oe.jd_614.aarch64.rpm --force
3、宿主机OS内优化
3.1 关闭防火墙
线上机器已关闭,无需修改
systemctl status firewalld.service
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld.service
3.2 网络内核参数优化(宿主机重启后会失效)
读写性能未看到明显提升 不改动
echo 1024 >/proc/sys/net/core/somaxconn
echo 16777216 >/proc/sys/net/core/rmem_max
echo 16777216 >/proc/sys/net/core/wmem_max
echo "4096 87380 16777216" >/proc/sys/net/ipv4/tcp_rmem
echo "4096 65536 16777216" >/proc/sys/net/ipv4/tcp_wmem
echo 360000 >/proc/sys/net/ipv4/tcp_max_syn_backlog
3.3 IO参数优化
性能未见提升 不改动
echo deadline > /sys/block/nvme0n1/queue/scheduler;
echo deadline > /sys/block/nvme1n1/queue/scheduler;
echo deadline > /sys/block/nvme2n1/queue/scheduler;
echo deadline > /sys/block/nvme3n1/queue/scheduler;
echo deadline > /sys/block/sda/queue/scheduler;
echo 2048 > /sys/block/nvme0n1/queue/nr_requests;
echo 2048 > /sys/block/nvme1n1/queue/nr_requests;
echo 2048 > /sys/block/nvme2n1/queue/nr_requests;
echo 2048 > /sys/block/nvme3n1/queue/nr_requests;
echo 2048 > /sys/block/sda/queue/nr_requests
3.4 缓存参数优化
性能未见提升 不改动
echo 5 >/proc/sys/vm/dirty_ratio;
echo 1 > /proc/sys/vm/swappiness
3.5 网卡中断绑核
整体方案不落地,但ethxx网卡队列数可修改
ethtool -l ethxxx 查看ethxxx网卡队列数
ethtool -L ethxxx combined 8 ethxxx 网卡队列数需要设成8,和x86一致,修改后性能有提升 (所有流量都是从eth 网卡进去的)。
systemctl stop irqbalance
systemctl disable irqbalance
ethtool -L eth0 combined 1 #将网卡eth0的队列配置为 combined 模式,将所有队列合并为一个。
#eth0 修改为实际使用的网卡设备名 这项参数对性能有影响
# 查看网卡队列信息
ethtool -l ethxxx
netdevice=eth0
cores=31
#查看网卡所属的 NUMANODE
cat /sys/class/net/${netdevice}/device/numa_node
#查看网卡中断号
cat /proc/interrupts | grep $(ethtool -i $netdevice | grep -i bus-info | awk -F ': ' '{print $2}') | awk -F ':' '{print $1}'
# 网卡中断绑核
for i in `cat /proc/interrupts | grep $(ethtool -i $netdevice | grep -i bus-info | awk -F ': ' '{print $2}')| awk -F ':' '{print $1}'`;do echo ${cores} > /proc/irq/$i/smp_affinity_list;done
netdevice=eth0
# 查看绑核后的结果
for i in `cat /proc/interrupts | grep $(ethtool -i $netdevice | grep -i bus-info | awk -F ': ' '{print $2}')| awk -F ':' '{print $1}'`;do cat /proc/irq/$i/smp_affinity_list;done
netdevice=eth1
cores=31
# 网卡中断绑核
for i in `cat /proc/interrupts | grep $(ethtool -i $netdevice | grep -i bus-info | awk -F ': ' '{print $2}')| awk -F ':' '{print $1}'`;do echo ${cores} > /proc/irq/$i/smp_affinity_list;done
# 查看绑核后的结果
for i in `cat /proc/interrupts | grep $(ethtool -i $netdevice | grep -i bus-info | awk -F ': ' '{print $2}')| awk -F ':' '{print $1}'`;do cat /proc/irq/$i/smp_affinity_list;done
4、业务容器绑NUMA (升级调度器并部署混部agent)
平台部署前,如果需要测试,可自行修改容器的cgroup配置进行绑核,将CPU与内存与背景压力所在的NUMA隔离。
举例操作如下
# 进入业务容器cgroup配置地址
cd /sys/fs/cgroup/cpuset/kubepods/burstable/poded***********/7b40a68a************
# 停docker,如果重启会重置cgroup配置
systemctl stop docker
# 压测过程中注意观察配置文件是否生效,如果docker服务会不停重启,可写个小脚本一直停服务或者覆盖写cgroup配置
echo 16-23 > cpu.set
echo 0 > mem.set
5、mysql-crc32 软编改成硬编 针对ARM
数据库侧编译,可统一部署
cd /mysql-5.7.26
git apply crc32-mysql5.7.26.patch
6、mysqld反馈编译优化
数据库侧编译,可统一部署
需要确认使用openEuler gcc 10.3.1

https://gitee.com/openeuler/A-FOT/wikis/README
环境准备(在测试环境和编译环境执行)
git clone https://gitee.com/openeuler/A-FOT.git
yum install -y A-FOT (仅支持 openEuler 22.03 LTS)
yum -y install perf
修改配置文件 a-fot.ini(在测试环境和编译环境执行)
cd /A-FOT
vim ./a-fot.ini # 修改内容如下
# 文件和目录请使用绝对路径
# 优化模式(AutoFDO、AutoPrefetch、AutoBOLT、Auto_kernel_PGO)(选择 AutoBolt) opt_mode=AutoBOLT
# 脚本工作目录(用来编译应用程序/存放 profile、日志,中间过程文件可能会很大,确保有 150G 的空 间)
work_path=/pgo-opt
# 应用运行脚本路径(空文件占位即可,使用 chmod 777 /root/run.sh 赋予可执行权限) run_script=/root/run.sh
# GCC 路径(bin、lib 的父目录,修改成所要使用的 gcc 的目录)
gcc_path=/usr
# AutoFDO、AutoPrefetch、AutoBOLT
# 针对应用的三种优化模式,请填写此部分配置
# 应用进程名
application_name=mysqld
# 二进制安装后可执行文件
bin_file=/usr/local/mysql-pgo/bin/mysqld
# 应用构建脚本路径(文件内填写源码编译 mysql 的相关命令, 赋予可执行权限)
chmod 777 /root/ build.sh
build_script=/root/build.sh
# 最大二进制启动时间(单位:秒)
max_waiting_time=700
# Perf 采样时长(单位:秒)(设置采样时间为 10min)
perf_time=600
# 检测是否优化成功(1=启用,0=禁用) check_success=1
# 构建模式 (Bear、Wrapper) build_mode=Wrapper
# auto_kernel_PGO
# 针对内核的优化模式,请填写此部分配置
# 内核 PGO 模式(arc=只启用 arc profile,all=启用完整的 PGO 优化) pgo_mode=all
# 执行阶段(1=编译插桩内核阶段,2=编译优化内核阶段) pgo_phase=1
# 内核源码目录(不指定则自动下载) kernel_src=/opt/kernel
# 内核构建的本地名(将根据阶段添加"-pgoing"或"-pgoed"后缀) kernel_name=kernel
# 内核编译选项(请确保选项修改正确合法,不会造成内核编译失败) #CONFIG_...=y
# 重启前的时间目录(用于将同一套流程的日志存放在一起)
last_time=
# 内核源码的 Makefile 地址(用于不自动编译内核的场景) makefile=
# 内核配置文件路径(用于不自动编译内核的场景) kernel_config=
# 内核生成的原始 profile 目录(用于不自动编译内核的场景) data_dir=
/root/build.sh (参考内容如下)
cd /mysql-8.0.25 rm -rf build mkdir build
cd build
cmake .. -DBUILD_CONFIG=mysql_release -DCMAKE_INSTALL_PREFIX=/usr/local/mysql-pgo -
DMYSQL_DATADIR=/data/mysql/data -DWITH_BOOST=/mysql-8.0.25/boost/boost_1_73_0 make -j 96
make -j 96 install

反馈编译
1. 第一次编译
可以跳过,直接把 A-FOT 放在有可执行的 mysql 进程 docker 即可
2. 数据采集 (在测试环境执行)
按照如下方式修改/A-FOT/a-fot 文件:对 409,以及 414-416 的函数进行注释
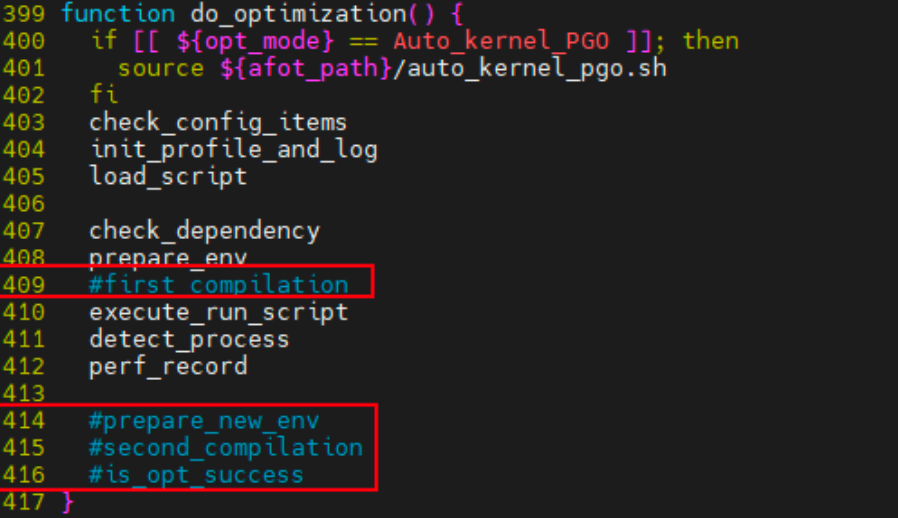
启动mysqld进程,同时压力端开始对mysql发压力,使得mysqld开始处理业务
执行 ./a-fot 屏幕出现如下回显
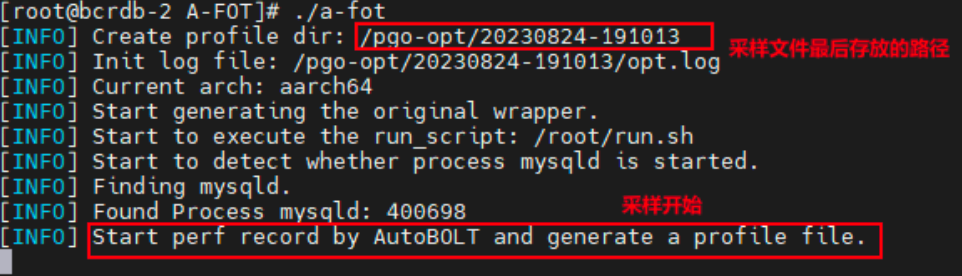
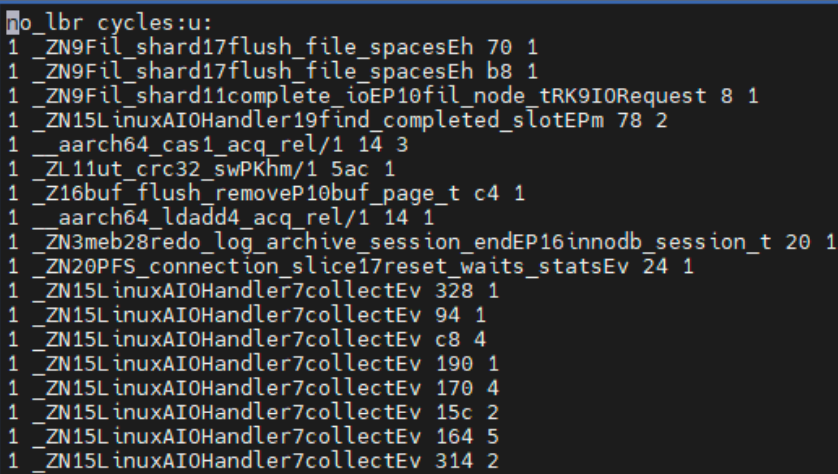
成功后可以在对应的/pgo-opt 目录下观察到 profile.gcov 文件

打开后为如下内容
3. 手动合入 Profile 进行编译
cmake .. -DCMAKE_INSTALL_PREFIX=/usr/local/mysql-5.7.26-pgo/ -
DMYSQL_DATADIR=/data/mysql/data -DSYSCONFDIR=/usr/local/mysql-5.7.26- pgo/etc -DWITH_INNOBASE_STORAGE_ENGINE=1 - DWITH_PERFSCHEMA_STORAGE_ENGINE=1 - DWITH_BLACKH0LE_ST0RAGE_ENGINE=1 -DDEFAULT_CHARSET=utf8 - DDEFAULT_COLLATION=utf8_general_ci - DMYSQL_UNIX_ADDR=/data/mysql/tmp/mysql.sock -DENABLED_LOCAL_INFILE=ON -DENABLED_PROFILING=ON - DWITH_DEBUG=0 -DMYSQL_TCP_PORT=3358 - DCMAKE_EXE_LINKER_FLAGS="-ljemalloc" -Wno-dev -DWITH_BOOST=/mysql-5.7.26/boost/boost_1_59_0 -Wno-dev -DCMAKE_CXX_FLAGS="-fbolt-use=Wl,-q" -DCMAKE_CXX_LINK_FLAGS="-Wl,-q"
PATH_OF_PROFILE 改成 profile 所在的原始路径
7、go的版本升级以及反馈编译
数据库相关代理使用go的才需要操作
7.1 升级golang到1.21
7.2 Go PGO优化
1.import pprof 程序的代码中添加 import _ "net/http/pprof"
2.启动程序,进行压力测试
- 压力启动后,执行下面操作,收集 profiling 文件,second 是采集时间,单位是 s curl -o cpu.pprof http://localhost:8080/debug/pprof/profile?seconds=304、根据生成的 cpu.pprof 重新编译二进制 mv cpu.pprof default.pgo 重新编译程序启用 –pgo 选项 go build –pgo=auto
关于性能的提升情况,Golang官方给出的数据是:
在Go1.21中,一组具有代表性的Go程序的基准测试表明,使用PGO构建可以提高大约2-7%的性能。
作者:京东零售 朱晨
来源:京东云开发者社区 转载请注明来源
【信创】 JED on 鲲鹏(ARM) 调优步骤与成果的更多相关文章
- Spark流处理调优步骤
总体运行状况: 这里的每个批处理任务间隔是10s一次,所以Total Delay是14s,那么对于下一个批处理任务来说就是延迟了14 - 10 = 4s . Total Delay - 每个批处 ...
- 鲲鹏性能优化十板斧(二)——CPU与内存子系统性能调优
1.1 CPU与内存子系统性能调优简介 调优思路 性能优化的思路如下: l 如果CPU的利用率不高,说明资源没有充分利用,可以通过工具(如strace)查看应用程序阻塞在哪里,一般为磁盘,网络或应 ...
- 16-MySQL DBA笔记-调优基础理论和工具
第五部分 性能调优与架构篇 本篇将为读者介绍性能调优的一些背景知识和理论,然后介绍一些工具的运用,最后介绍从应用程序到操作系统.到数据库.到存储各个环节的优化. 性能调优是一个高度专业的领域,它需要一 ...
- Java性能调优笔记
Java性能调优笔记 调优步骤:衡量系统现状.设定调优目标.寻找性能瓶颈.性能调优.衡量是否到达目标(如果未到达目标,需重新寻找性能瓶颈).性能调优结束. 寻找性能瓶颈 性能瓶颈的表象:资源消耗过多. ...
- linux性能调优概述
- 什么是性能调优?(what) - 为什么需要性能调优?(why) - 什么时候需要性能调优?(when) - 什么地方需要性能调优?(where) - 什么人来进行性能调优?(who) - 怎么样 ...
- Kafka实战分析(一)- 设计、部署规划及其调优
1. Kafka概要设计 kafka在设计之初就需要考虑以下4个方面的问题: 吞吐量/延时 消息持久化 负载均衡和故障转移 伸缩性 1.1 吞吐量/延时 对于任何一个消息引擎而言,吞吐量都是至关重要的 ...
- jvm调优的分类
本文部分内容出自https://blog.csdn.net/yang_net/article/details/5830820 调优步骤: 衡量系统现状. 设定调优目标. 寻找性能瓶颈. 性能调优. 衡 ...
- java虚拟机(十三)--GC调优思路
GC调优对我们开发人员来说,如果你想要技术方面一直发展下去,这部分内容的了解是必不可少的,jvm对于工作.面试来说都很重要,GC调优的问题 更是重中之重,因为是对你jvm学习内容的实践,知识只有应用实 ...
- JVM调优和深入了解性能优化
JVM调优的本质: 并不是显著的提高系统性能,不是说你调了,性能就能提升几倍或者上十倍,JVM调优,主要调的是稳定.如果你的系统出现了频繁的垃圾回收,这个时候系统是不稳定的,所以需要我们来进行JVM调 ...
- ETL调优的一些分享(上)(转载)
ETL是构建数据仓库的重要一环.通过该过程用户将所需数据提取出来,并按照已定义的模型导入数据仓库.由于ETL是建立数据仓库的必经过程,它的效率将影响整个数据仓库的构建,因此它的有效调优具有很高的重要性 ...
随机推荐
- Python编程和数据科学中的机器学习:如何处理和可视化具有噪声和干扰的数据
目录 随着数据科学和机器学习的快速发展,处理和分析具有噪声和干扰的数据成为了一个日益重要的挑战.在数据科学和机器学习中,噪声和干扰通常来自于各种因素,例如随机性和非随机性,数据缺失,数据集中的错误或错 ...
- 多个视频文件合成画中画效果(Python、ffmpeg)
Step 1 从视频中分离出音频(MP4->mp3) def separateMp4ToMp3(tmp): mp4 = tmp.replace('.tmp', '.mp4') print('-- ...
- SpringBoot 2 种方式快速实现分库分表,轻松拿捏!
大家好,我是小富- (一)好好的系统,为什么要分库分表? (二)分库分表的 21 条法则,hold 住! 本文是<分库分表ShardingSphere5.x原理与实战>系列的第三篇文章,本 ...
- [渗透测试]—4.2 Web应用安全漏洞
在本节中,我们将学习OWASP(开放网络应用安全项目)发布的十大Web应用安全漏洞.OWASP十大安全漏洞是对Web应用安全风险进行评估的标准,帮助开发者和安全工程师了解并防范常见的安全威胁. 1. ...
- 现代C++(Modern C++)基本用法实践:五、智能指针
概述 c++效率较高的一个原因是我们可以自己定制策略手动申请和释放内存,当然,也伴随着开发效率降低和内存泄漏的风险.为了减少手动管理内存带来的困扰,c++提出了智能指针,可以帮助我们进行内存管理,有三 ...
- 10/28-29_String类_SrtingBuffer类_Interger类_笔记
API:应用程序编程接口 String功能 public String replace (char oldchar ,char newchar); //符串中某一字符被一新字符替换 public St ...
- Stable Diffusion修复老照片-图生图
修复老照片的意义就不多说了,相信大家都明白,这里直接开讲方法. 1.原理 这个方法需要一个真实模型,以便让修复的照片看起来比较真实,我这里选择:realisticVisionV20,大家有更好的给我推 ...
- redis 中的 set
set是String中的无序集合 底层是 是 value为null 的hash表 时间复杂化是o(1): sadd k1 v1 v2 v3 set中添加数据 smembers k1 取出set ...
- 这样拆分和压缩css代码
在[拆分]和[压缩]css代码之前,首先要配置 loader 处理不同的 css 资源,因为 webpack 没有默认可处理 css 资源的规则,具体可参考这一篇 webpack处理css/less资 ...
- [linux]常见内核TCP参数描述与配置
前言 所有的TCP/IP参数都位于/proc/sys/net目录下(请注意,对/proc/sys/net目录下内容的修改都是临时的,任何修改在系统重启后都会丢失),如果需要固化设置,则需要修改/etc ...