使用 Go 语言实现二叉搜索树
原文链接: 使用 Go 语言实现二叉搜索树
二叉树是一种常见并且非常重要的数据结构,在很多项目中都能看到二叉树的身影。
它有很多变种,比如红黑树,常被用作 std::map 和 std::set 的底层实现;B 树和 B+ 树,广泛应用于数据库系统中。
本文要介绍的二叉搜索树用的也很多,比如在开源项目 go-zero 中,就被用来做路由管理。
这篇文章也算是一篇前导文章,介绍一些必备知识,下一篇再来介绍具体在 go-zero 中的应用。
二叉搜索树的特点
最重要的就是它的有序性,在二叉搜索树中,每个节点的值都大于其左子树中的所有节点的值,并且小于其右子树中的所有节点的值。
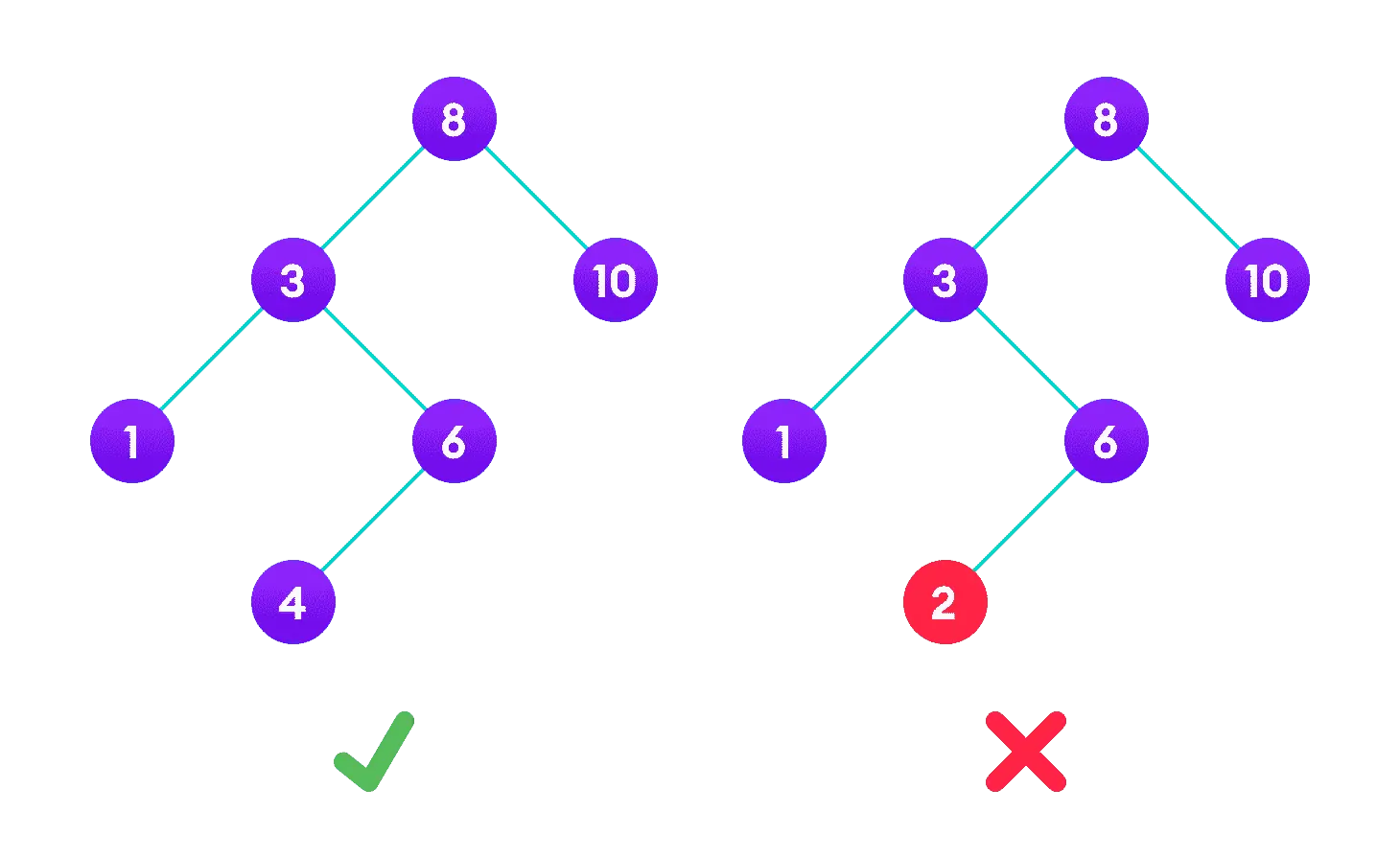
这意味着通过二叉搜索树可以快速实现对数据的查找和插入。
Go 语言实现
本文主要实现了以下几种方法:
Insert(t):插入一个节点Search(t):判断节点是否在树中InOrderTraverse():中序遍历PreOrderTraverse():前序遍历PostOrderTraverse():后序遍历Min():返回最小值Max():返回最大值Remove(t):删除一个节点String():打印一个树形结构
下面分别来介绍,首先定义一个节点:
type Node struct {
key int
value Item
left *Node //left
right *Node //right
}
定义树的结构体,其中包含了锁,是线程安全的:
type ItemBinarySearchTree struct {
root *Node
lock sync.RWMutex
}
插入操作:
func (bst *ItemBinarySearchTree) Insert(key int, value Item) {
bst.lock.Lock()
defer bst.lock.Unlock()
n := &Node{key, value, nil, nil}
if bst.root == nil {
bst.root = n
} else {
insertNode(bst.root, n)
}
}
// internal function to find the correct place for a node in a tree
func insertNode(node, newNode *Node) {
if newNode.key < node.key {
if node.left == nil {
node.left = newNode
} else {
insertNode(node.left, newNode)
}
} else {
if node.right == nil {
node.right = newNode
} else {
insertNode(node.right, newNode)
}
}
}
在插入时,需要判断插入节点和当前节点的大小关系,保证搜索树的有序性。
中序遍历:
func (bst *ItemBinarySearchTree) InOrderTraverse(f func(Item)) {
bst.lock.RLock()
defer bst.lock.RUnlock()
inOrderTraverse(bst.root, f)
}
// internal recursive function to traverse in order
func inOrderTraverse(n *Node, f func(Item)) {
if n != nil {
inOrderTraverse(n.left, f)
f(n.value)
inOrderTraverse(n.right, f)
}
}
前序遍历:
func (bst *ItemBinarySearchTree) PreOrderTraverse(f func(Item)) {
bst.lock.Lock()
defer bst.lock.Unlock()
preOrderTraverse(bst.root, f)
}
// internal recursive function to traverse pre order
func preOrderTraverse(n *Node, f func(Item)) {
if n != nil {
f(n.value)
preOrderTraverse(n.left, f)
preOrderTraverse(n.right, f)
}
}
后序遍历:
func (bst *ItemBinarySearchTree) PostOrderTraverse(f func(Item)) {
bst.lock.Lock()
defer bst.lock.Unlock()
postOrderTraverse(bst.root, f)
}
// internal recursive function to traverse post order
func postOrderTraverse(n *Node, f func(Item)) {
if n != nil {
postOrderTraverse(n.left, f)
postOrderTraverse(n.right, f)
f(n.value)
}
}
返回最小值:
func (bst *ItemBinarySearchTree) Min() *Item {
bst.lock.RLock()
defer bst.lock.RUnlock()
n := bst.root
if n == nil {
return nil
}
for {
if n.left == nil {
return &n.value
}
n = n.left
}
}
由于树的有序性,想要得到最小值,一直向左查找就可以了。
返回最大值:
func (bst *ItemBinarySearchTree) Max() *Item {
bst.lock.RLock()
defer bst.lock.RUnlock()
n := bst.root
if n == nil {
return nil
}
for {
if n.right == nil {
return &n.value
}
n = n.right
}
}
查找节点是否存在:
func (bst *ItemBinarySearchTree) Search(key int) bool {
bst.lock.RLock()
defer bst.lock.RUnlock()
return search(bst.root, key)
}
// internal recursive function to search an item in the tree
func search(n *Node, key int) bool {
if n == nil {
return false
}
if key < n.key {
return search(n.left, key)
}
if key > n.key {
return search(n.right, key)
}
return true
}
删除节点:
func (bst *ItemBinarySearchTree) Remove(key int) {
bst.lock.Lock()
defer bst.lock.Unlock()
remove(bst.root, key)
}
// internal recursive function to remove an item
func remove(node *Node, key int) *Node {
if node == nil {
return nil
}
if key < node.key {
node.left = remove(node.left, key)
return node
}
if key > node.key {
node.right = remove(node.right, key)
return node
}
// key == node.key
if node.left == nil && node.right == nil {
node = nil
return nil
}
if node.left == nil {
node = node.right
return node
}
if node.right == nil {
node = node.left
return node
}
leftmostrightside := node.right
for {
//find smallest value on the right side
if leftmostrightside != nil && leftmostrightside.left != nil {
leftmostrightside = leftmostrightside.left
} else {
break
}
}
node.key, node.value = leftmostrightside.key, leftmostrightside.value
node.right = remove(node.right, node.key)
return node
}
删除操作会复杂一些,分三种情况来考虑:
- 如果要删除的节点没有子节点,只需要直接将父节点中,指向要删除的节点指针置为
nil即可 - 如果删除的节点只有一个子节点,只需要更新父节点中,指向要删除节点的指针,让它指向删除节点的子节点即可
- 如果删除的节点有两个子节点,我们需要找到这个节点右子树中的最小节点,把它替换到要删除的节点上。然后再删除这个最小节点,因为最小节点肯定没有左子节点,所以可以应用第二种情况删除这个最小节点即可
最后是一个打印树形结构的方法,在实际项目中其实并没有实际作用:
func (bst *ItemBinarySearchTree) String() {
bst.lock.Lock()
defer bst.lock.Unlock()
fmt.Println("------------------------------------------------")
stringify(bst.root, 0)
fmt.Println("------------------------------------------------")
}
// internal recursive function to print a tree
func stringify(n *Node, level int) {
if n != nil {
format := ""
for i := 0; i < level; i++ {
format += " "
}
format += "---[ "
level++
stringify(n.left, level)
fmt.Printf(format+"%d\n", n.key)
stringify(n.right, level)
}
}
单元测试
下面是一段测试代码:
func fillTree(bst *ItemBinarySearchTree) {
bst.Insert(8, "8")
bst.Insert(4, "4")
bst.Insert(10, "10")
bst.Insert(2, "2")
bst.Insert(6, "6")
bst.Insert(1, "1")
bst.Insert(3, "3")
bst.Insert(5, "5")
bst.Insert(7, "7")
bst.Insert(9, "9")
}
func TestInsert(t *testing.T) {
fillTree(&bst)
bst.String()
bst.Insert(11, "11")
bst.String()
}
// isSameSlice returns true if the 2 slices are identical
func isSameSlice(a, b []string) bool {
if a == nil && b == nil {
return true
}
if a == nil || b == nil {
return false
}
if len(a) != len(b) {
return false
}
for i := range a {
if a[i] != b[i] {
return false
}
}
return true
}
func TestInOrderTraverse(t *testing.T) {
var result []string
bst.InOrderTraverse(func(i Item) {
result = append(result, fmt.Sprintf("%s", i))
})
if !isSameSlice(result, []string{"1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11"}) {
t.Errorf("Traversal order incorrect, got %v", result)
}
}
func TestPreOrderTraverse(t *testing.T) {
var result []string
bst.PreOrderTraverse(func(i Item) {
result = append(result, fmt.Sprintf("%s", i))
})
if !isSameSlice(result, []string{"8", "4", "2", "1", "3", "6", "5", "7", "10", "9", "11"}) {
t.Errorf("Traversal order incorrect, got %v instead of %v", result, []string{"8", "4", "2", "1", "3", "6", "5", "7", "10", "9", "11"})
}
}
func TestPostOrderTraverse(t *testing.T) {
var result []string
bst.PostOrderTraverse(func(i Item) {
result = append(result, fmt.Sprintf("%s", i))
})
if !isSameSlice(result, []string{"1", "3", "2", "5", "7", "6", "4", "9", "11", "10", "8"}) {
t.Errorf("Traversal order incorrect, got %v instead of %v", result, []string{"1", "3", "2", "5", "7", "6", "4", "9", "11", "10", "8"})
}
}
func TestMin(t *testing.T) {
if fmt.Sprintf("%s", *bst.Min()) != "1" {
t.Errorf("min should be 1")
}
}
func TestMax(t *testing.T) {
if fmt.Sprintf("%s", *bst.Max()) != "11" {
t.Errorf("max should be 11")
}
}
func TestSearch(t *testing.T) {
if !bst.Search(1) || !bst.Search(8) || !bst.Search(11) {
t.Errorf("search not working")
}
}
func TestRemove(t *testing.T) {
bst.Remove(1)
if fmt.Sprintf("%s", *bst.Min()) != "2" {
t.Errorf("min should be 2")
}
}
上文中的全部源码都是经过测试的,可以直接运行,并且已经上传到了 GitHub,需要的同学可以自取。
以上就是本文的全部内容,如果觉得还不错的话欢迎点赞,转发和关注,感谢支持。
源码地址:
推荐阅读:
参考文章:
使用 Go 语言实现二叉搜索树的更多相关文章
- 二叉搜索树(Binary Search Tree)--C语言描述(转)
图解二叉搜索树概念 二叉树呢,其实就是链表的一个二维形式,而二叉搜索树,就是一种特殊的二叉树,这种二叉树有个特点:对任意节点而言,左孩子(当然了,存在的话)的值总是小于本身,而右孩子(存在的话)的值总 ...
- 小白专场-是否同一颗二叉搜索树-python语言实现
目录 一.二叉搜索树的相同判断 二.问题引入 三.举例分析 四.方法探讨 4.1 中序遍历 4.2 层序遍历 4.3 先序遍历 4.4 后序遍历 五.总结 六.代码实现 一.二叉搜索树的相同判断 二叉 ...
- 小白专场-是否同一颗二叉搜索树-c语言实现
目录 一.题意理解 二.求解思路 三.搜索树表示 程序框架搭建 3.1 如何建搜索树 3.2 如何判别 3.3 清空树 更新.更全的<数据结构与算法>的更新网站,更有python.go.人 ...
- Go语言实现:【剑指offer】二叉搜索树的第k个的结点
该题目来源于牛客网<剑指offer>专题. 给定一棵二叉搜索树,请找出其中的第k小的结点.例如,(5,3,7,2,4,6,8) 中,按结点数值大小顺序第三小结点的值为4. Go语言实现: ...
- Go语言实现:【剑指offer】二叉搜索树与双向链表
该题目来源于牛客网<剑指offer>专题. 输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表.要求不能创建任何新的结点,只能调整树中结点指针的指向. Go语言实现: type T ...
- Go语言实现:【剑指offer】二叉搜索树的后序遍历序列
该题目来源于牛客网<剑指offer>专题. 输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果.如果是则输出Yes,否则输出No.假设输入的数组的任意两个数字都互不相同. Go ...
- 二叉搜索树 C语言实现
1.二叉搜索树基本概念 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是一棵具有如下特性的非空二叉树: (1)若它的左子树非空,则左子树上所有结点的关键字均小于根结点的关键字: (2)若它的右子树非 ...
- 二叉搜索树BST(C语言实现可用)
1:概述 搜索树是一种可以进行插入,搜索,删除等操作的数据结构,可以用作字典或优先级队列.二叉搜索树是最简单的搜索树.其左子树的键值<=根节点的键值,右子树的键值>=根节点的键值. 如果共 ...
- 《数据结构与算法分析——C语言描述》ADT实现(NO.03) : 二叉搜索树/二叉查找树(Binary Search Tree)
二叉搜索树(Binary Search Tree),又名二叉查找树.二叉排序树,是一种简单的二叉树.它的特点是每一个结点的左(右)子树各结点的元素一定小于(大于)该结点的元素.将该树用于查找时,由于二 ...
- 98. 验证二叉搜索树 前序遍历解法以及后续遍历解法(go语言)
leetcode题目 98. 验证二叉搜索树 前序遍历 最简洁的答案版本,由于先判断的是根节点,所以直接判断当前root的值v,是否满足大于左子树最大,小于右子树最小,然后再遍历左子树,右子树是否是这 ...
随机推荐
- Typora+MinIO+Python代码打造舒适协作环境
作者:IT王小二 博客:https://itwxe.com 不知不觉大半年没更新了...前面小二介绍过使用Typora+MinIO+Java代码打造舒适写作环境,然后有很多大佬啊,说用Java来实现简 ...
- Jupyter Notebook(或vscode插件) 一个cell有多个输出
方法一 在文件的开头加上如下代码,该方法仅对当前文件有效 from IPython.core.interativeshell import InteractiveShell InteractiveSh ...
- selenium 执行js脚本
使用 selenium 直接在当前页面中进行js交互 使用selenium 执行 Js 脚本 要使用 js 首先要知道 js 怎么用,现在举个简单得例子,就用12306举例子, 它的首页日期选择框是只 ...
- 2022-12-22:给定一个数字n,代表数组的长度, 给定一个数字m,代表数组每个位置都可以在1~m之间选择数字, 所有长度为n的数组中,最长递增子序列长度为3的数组,叫做达标数组。 返回达标数组的
2022-12-22:给定一个数字n,代表数组的长度, 给定一个数字m,代表数组每个位置都可以在1~m之间选择数字, 所有长度为n的数组中,最长递增子序列长度为3的数组,叫做达标数组. 返回达标数组的 ...
- Mybatis查询
查询 查询的数据为单条实体类 使用实体类进行接受即可,或者使用list,map接口均可.后面两者比较浪费 使用实体类接受 mapper接口: User selectUserById(int useri ...
- Linux 创建 Python 虚拟环境
Linux 创建 Python 虚拟环境 0. 前言 网上教程太杂太乱,要么排版不好看,要么讲半天讲不到重点,故做此篇,精简干练. 1. 安装virtualenv 先用pip安装virtualenv第 ...
- [MAUI]在.NET MAUI中复刻苹果Cover Flow
@ 目录 原理 3D旋转 平行变换 创建3D变换控件 绘制封面图片 应用3D旋转 应用平行变换 绘制倒影 创建绑定属性 创建绑定数据 创建布局 计算位置 计算3D旋转 创建动效 项目地址 Cover ...
- Multiserver游戏服务器Demo[C++&Lua]
代码参考 代码文件参考下述详解的类图,工程参考第零章工程说明 关键特性 对Socket库进行封装,抹平Socket的Window&Linux的平台差异. C++嵌入lua脚本,增加开发者编码效 ...
- jquery页面搜索关键词突出显示
页面搜索关键词突出 // 页面搜索关键词突出 $(function () { $(".list_r").find('span').css({ // 每次搜索开始,先把所有字体颜色恢 ...
- bugku xxx二手交易市场
打开靶场 分析 很明显需要先注册一个账号才行 完成后发现两个上传图片的地方 一个是更换头像, 一个是发布内容 先更换头像试试 首先上传一个木马图片,会发现一直转圈圈,(卡住了) 只能先上传正常的图片了 ...