玩转云上数据湖,解析Serverless 技术落地
导读:
本文主要介绍Serverless计算相关技术与其在华为云数据湖探索服务(后文简称DLI)中的技术落地。Serverless是DLI将计算能力服务化和产品化关键技术,与传统IAAS和PAAS技术不同,DLI运用Serverless技术向客户提供了一种高效易用易扩展的计算框架,使得客户更能聚焦业务,避免牵扯集群运维的细枝末节。本文将从以下几点解读Serverless技术:
1. serverless计算简介
2. 云计算架构演进—从IaaS到Serverless
3. Serverless计算应用场景与潜力
4. DLI Serverless 计算
serverless计算简介
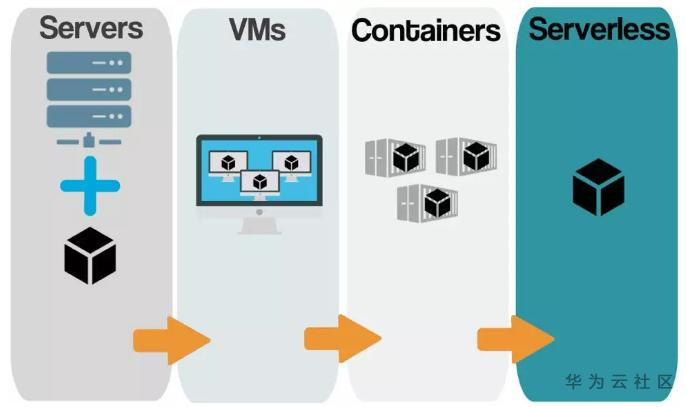
图 Serverless与传统云计算比较
无服务器计算(Serverless)是一种新型的云计算范式,在业界也被称为FaaS(函数即服务),它有别于传统的IaaS(基础设施即服务)和PaaS(平台即服务)技术,旨在帮助开发者摆脱减少甚至免去底层基础架构管理上的诸多烦扰。Serverless计算服务允许客户在不构建一个复杂的基础设施的情况下开发,运行和管理应用程序。在2014年10月先由http://hook.io提供给业界,接着AWS推出Lambda,2016年Google Cloud Functions,Microsoft Azure Functions对外提供服务,接下来IBM的OpenWhisk并开源。目前华为云也提供类似FaaS产品FunctionStage,而DLI服务也向用户提供Serverless Spark产品。
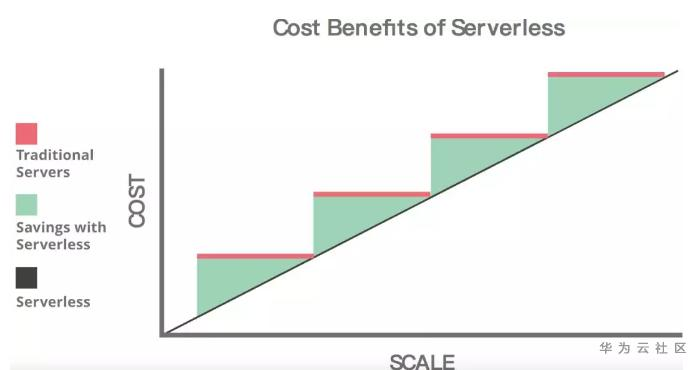
图 Serverless成本优势
Serverless计算并非旨在实现真正意义上的“无服务器”,而是指企业将后端基础结构的维护交由可靠云服务公司,云服务公司以服务的方式为开发者提供所需各类功能等,加快企业产品研发和发布周期,同时增强服务的扩展性。
Serverless计算免去后端基础服务的诸多事宜,开发者可以专注在产品代码,不需要维护任何的服务器。服务器由云服务商提供,服务扩容的便捷性、灵活性大大提升。Serverless应用程序运行应用的服务默认提供高可用、容错高。无服务器计算,相比传统服务性价比高,企业只需要支付所使用的部分,没有任何与无服务器计算相关的成本,尤其是应用程序使用随时间变化大的企业是非常划算的。
云计算架构演进—从IaaS到Serverless
云服务第一阶段的云主要解决硬件资源(网络,计算,存储)的运维和供给问题,也就是 IaaS 云,可以理解成基于硬件资源的共享经济。IaaS 云的交付的主要是资源,接口以及控制台也是面向资源的,尽量以模拟物理机房环境来降低应用的迁移成本。而云发展到当前阶段来看,出现了两种需求:
真正的按需计算
原来云的按需计算只是虚拟机维度的,按时间计费以及弹性伸缩,并不能正真做到按需计算,计算和内存资源都是预申请规划的,和服务的请求并发数并没有明确的关系,哪怕一段时间一个请求没有,资源还是依然占用。而 Serverless计算可以做到按请求计费,不需要为等待付费,可以做到更高效的资源利用率。
面向应用
本质上用户对云的期望是应用的运行环境,并且最好是只让用户关心业务逻辑,而不需要关心,或者尽量少关心技术逻辑(比如监控,性能,弹性,高可用,日志追踪等)。这也是云原生应用(Cloud Native Application)这个概念提出的背景。
随着两种需求日益强烈,Serverless计算模式孕育而生。它给出的方案就是应用只需要把包含自己业务逻辑的功能模块提交给云,其他的事情由云来完成。这样,云相当于直接接管了业务逻辑模块,然后其他的技术功能直接由云来提供,不依赖开发者在自己应用中引入标准化框架来实现。
Serverless计算应用场景与潜力
Serverless计算敏捷灵活,适用门槛低,综合成本低的优势,特别适合以下几个场景:
视频,图片以及流式事件处理
其本质上是需要一种通用的,可自定义的,工作流应用。当前的工作流一般都是针对具体场景的,尚无支持自定义逻辑并且适用于各种类型事件的分布式工作流。而基于 Serverless计算有可能诞生这样一种工作流。通过与Flink,Spark Streaming这样的流式大数据处理平台结合,Serverless计算模型将充分发挥其价值。
事件驱动以及响应式架构
这个场景和视频图片流场景有相似之处,只不过前一个关注的是应用场景,这条单指技术架构场景。服务器端的事件驱动和响应式架构和客户端技术相比,一直缺少一种统一的体系解决方案,主要原因是服务器端缺少分布式系统级别的支持,纯开发框架的方式实现比较困难,如果调度系统和开发框架配合,实现这种架构就比较容易了。
IoT
物联网场景实际上和前面的流式事件处理以及事件驱动架构都有关系。这里单独作为一条阐述,主要是物联网对应用开发带来的不仅仅是架构上的变化。互联网主要是信息技术,主要是面向人的应用,要求及时把信息展示给用户,所以应用多是 http 的请求响应模式,对延迟比较敏感(毫秒级)。而物联网场景下,多是事件触发,哪怕有人参与的场景,比如智能开关,也是触发事件后控制另外的设备,对延迟忍耐度较高(秒级),协议多也不是 http,而是物联网相关的消息协议。
应用系统的自定义扩展需求
任何一个标准的系统,发展到一定程度都会有不同的自定义扩展需求。一种是提供内置扩展机制,比如 Java 的许多应用,可以允许在应用中增加扩展,应用自己通过 jvm 的隔离机制提供插件运行环境。另外一种是通过远程接口(无论是 http 还是其他远程协议),由用户按照协议实现自定义需求,然后整合,应用本身不提供扩展运行环境。前者对编程语言有约束,隔离性差,后者开发运维成本比较高。如果基于Serverless计算支持一种分布式的扩展运行环境,自动和应用整合,相当于兼有了二者的优势。可以预见,在未来几年里,大多数 SaaS 以及 API 服务都会提供类似Serverless计算的环境来托管用户的自定义扩展。如果私有环境中也有标品,私有部署的应用也会逐渐提供这种整合能力。
跨云与混合云场景
当前大多数混合云解决方案都只能做到基础设施的混合,至于用户的应用要实现多云,则只能在用户自己的应用中处理,云平台能提供的帮助有限。但因为Serverless计算侵入了应用的架构,接管了应用的事件输入,乃至事件输出,所以它可以做的更多,也可能提供一种基于Serverless计算的混合云开发框架,用户按照架构模式实现逻辑就天然跨云。
边缘计算场景
边缘计算当前的应用场景还没凸显出来,但可以预见的是,边缘的计算能力肯定不如云端,更小的资源使用粒度对边缘更友好。此外,边缘的具体资源要对用户透明。从以上两点来看, Serverless计算对边缘计算是天然友好的。同时,边缘计算要解决的很多问题和混合云场景类似。
DLI Serverless 计算
图 DLI Serverless Spark作业管理
现在DLI服务已经上线了Serverless Spark/FLINK产品,提供用户简单易用的流批一体的计算引擎。用户只要简单地创建集群和上传自己的功能代码,就能将应用跑在DLI已经为您优化好的云环境里,并使用DLI内置的跨源分析功能,轻松玩转华为云上多种数据源。DLI让客户专注业务创新,其他的杂事就交给我们DLI处理!
玩转云上数据湖,解析Serverless 技术落地的更多相关文章
- 使用 Iceberg on Kubernetes 打造新一代云原生数据湖
背景 大数据发展至今,按照 Google 2003年发布的<The Google File System>第一篇论文算起,已走过17个年头.可惜的是 Google 当时并没有开源其技术,& ...
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- Fluid + GooseFS 助力云原生数据编排与加速快速落地
前言 Fluid 作为基于 Kubernetes 开发的面向云原生存算分离场景下的数据调度和编排加速框架,已于近期完成了 v0.6.0 版本的正式发布.腾讯云容器 TKE 团队一直致力于参与 Flui ...
- 用OkHttpGo和FastJson获取OneNET云平台数据(解析嵌套数组)
JSON数据格式有两种,一种是 { } 大括号表示的JSON对象,一种是 [ ] 中括号表示的JSON数组.从OneNET获取到的数组是这样的,并用Json解析网址查看https://jsonform ...
- DeltaLake数据湖解决方案
Delta Lake 是DataBricks公司推出的一种数据湖解决方案,Delta为该方案的核心组件.围绕数据流走向(数据入湖从流入数据湖.数据组织管理.数据查询到流出数据湖)推出了一系列功能特性, ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(下)
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 作为微软Azure上最新 ...
- Apache Hudi表自动同步至阿里云数据湖分析DLA
1. 引入 Hudi 0.6.0版本之前只支持将Hudi表同步到Hive或者兼容Hive的MetaStore中,对于云上其他使用与Hive不同SQL语法MetaStore则无法支持,为解决这个问题,近 ...
- COS 数据湖最佳实践:基于 Serverless 架构的入湖方案
01 前言 数据湖(Data Lake)概念自2011年被推出后,其概念定位.架构设计和相关技术都得到了飞速发展和众多实践,数据湖也从单一数据存储池概念演进为包括 ETL 分析.数据转换及数据处理的下 ...
- 云上快速搭建Serverless AI实验室
Serverless Kubernetes和ACK虚拟节点都已基于ECI提供GPU容器实例功能,让用户在云上低成本快速搭建serverless AI实验室,用户无需维护服务器和GPU基础运行环境,极大 ...
- 基于 DataLakeAnalytics 的数据湖实践
随着软硬件各方面条件的成熟,数据湖(Data Lake)已经越来越受到各大企业的青睐, 与传统的数仓实践不一样的是,数据湖不需要专门的“入仓”的过程,数据在哪里,我们就从哪里读取数据进行分析.这样的好 ...
随机推荐
- WPF 中引入依赖注入(.NET 通用主机)
WPF 中引入依赖注入(.NET 通用主机) 在网上看到的文章都是通过 App.cs 中修改配置进行的,这样侵入性很高而且服务主机是通过 App 启动时加载的而不是服务主机加载的 App 有一点违反原 ...
- 文心一言 VS 讯飞星火 VS chatgpt (110)-- 算法导论10.2 1题
一.用go语言,单链表上的动态集合操作 INSERT 能否在 O(1)时间内实现?DELETE 操作呢? 文心一言: 在单链表中,INSERT 和 DELETE 操作的时间复杂度通常是 O(n),其中 ...
- LVS负载均衡概念+三种模式
1.LVS负载均衡概念剖解: 1)LVS技术全称:Linux virtual Server ,Linux虚拟机服务器集群,1998由章文嵩博士设计.并且开源的,是中国最早的开源软件项目之一. 2) ...
- P1522 [USACO2.4] 牛的旅行 Cow Tours
Problem 题目简述 给你两个独立的联通块,求:在两个联通块上各找一个点连起来,使得新的联通块的直径的最小值. 思路 本题主要做法:\(Floyd\). 首先,Floyd求出任意两个点之间的最短路 ...
- JavaScript用策略模式消除if else 和 switch
js程序中最常用的if else循环,如果分枝很多的的情况下难免使写出的程序又臭又长,但是根据需求又必须将这些分支处理,此时稍有经验的程序员可能会想到用switch case优化但是只是仅仅做到利于阅 ...
- Mybatis-plus 生成代码
引入依赖 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-g ...
- Null return value from advice does not match primitive return type for
1.org.springframework.aop.AopInvocationException:Null return value from advice does not match primit ...
- 火山引擎ByteHouse:如何优化ClickHouse物化视图能力?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 近期,火山引擎 ByteHouse 升级了基于 ClickHouse 的物化视图能力,为解决数据量爆炸式增长带来的 ...
- 2023第十四届极客大挑战 — MISC WP
Misc方向题解:来自本人 cheekin 请前往"三叶草小组Syclover"微信公众号输入flag获得flag 我的解答: 关注公众号回复就可以得到一张图片,图片隐写zsteg ...
- [ABC309G] Ban Permutation
Problem Statement Find the number, modulo $998244353$, of permutations $P=(P_1,P_2,\dots,P_N)$ of $( ...