多语言ASR?没有什么听不懂,15种语言我全都要
摘要:在这篇博文中,我们介绍来自Google的一篇论文《Scaling End-to-End Models for Large-Scale Multilingual ASR》,来看看如何构建一个能够识别15种语言的多语ASR系统。
本文分享自华为云社区《多语言ASR 没有什么听不懂,15种语言我全都要》,作者:xiaoye0829 。
在这篇博文中,我们介绍来自Google的一篇论文《Scaling End-to-End Models for Large-Scale Multilingual ASR》。建立一个能识别多种语言的ASR系统,是十分有挑战的,因为这些语言之间存在着非常大的差异,并且数据量十分不均衡。现有的工作中,我们可以观察到利用有丰富语料的语言,可以帮助只有少量语料的语言的学习,但是这往往也伴随着,有丰富语料的语言的效果会下降。我们在15种语言上进行了研究,每种语言的大小从7.7千小时到54.7千小时,我们发现增大模型的参数量,是解决容量瓶颈的有效方法,我们500M参数的模型,已经超过了单语的baseline模型,当我们把模型参数进一步增大到1B或者10B时,我们能获得更大的收益。另外,我们发现大模型不仅在数据利用上更有效,在训练时间上也更有效率,我们的1B(10亿)参数的模型达到和500M参数的模型相同的准确率,只花了34%的时间。当模型容量有限时,增加模型的深度,通常比增加模型的宽度要好,更大的encoder,也往往比更大的decoder要好。
多语言ASR的关注点通常在于提高低资源(只有少量语料)语言的性能,背后的思想是,利用相似语言的数据,多种语言一起联合优化,以及连续的正向迁移从高资源语言的迁移。在这篇文章中,我们从容量(capacity)的视角来研究下,在多语言的模型中,高资源语言的性能下降问题。
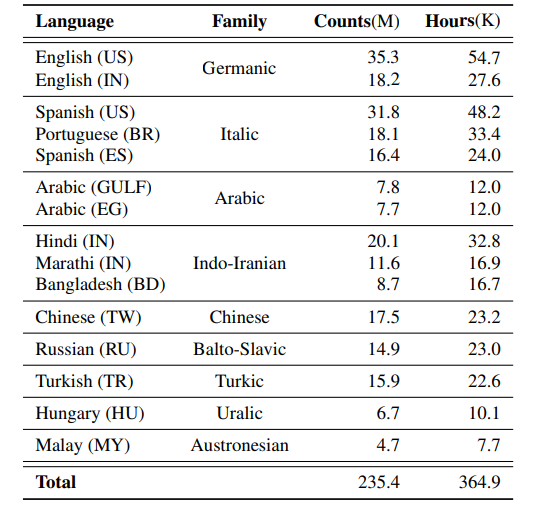
先前的工作探索过50到100种语言,但是数据集的大小十分有限,最大的数据集仅仅只有1k小时的演讲数据。在我们的实验中,每种语言的数据量从7.7千小时到54.7千小时(如下图,counts代表语音的条数,hours代表语音的时长),这使得我们可以有一个高质量的单语模型,那么我们就是要训练一个多语的模型,能够超过每个单语的模型。我们从容量的角度展示了如何去解决这个问题。
随着模型容量上升,我们成功恢复了所有高资源单语模型的性能。我们做了很多对比试验,并发现增加深度通常能取得比增加宽度更好的效果,并且我们发现,encoder的容量往往与模型的识别效果很相关。我们观察到,在固定的模型容量下,如何分配语言的信息变得不那么重要了。而且,大模型更简单,并且更有效率,需要更少的训练轮次,和更少的TPU时间,去达到相似的实验效果。
在本文的多语言ASR系统中,使用的是一个基于attention的encoder-decoder模型。对于encoder,我们使用Conformer架构,包含一个输入映射层,一个相对位置嵌入层,以及一些conformer层。第一个conformer块,包含4个conformer层。第二个conformer块,包含一个conformer层。我们的decoder尝试了两种不同的架构,一种是单向的LSTM,另一种是带有掩码的自注意和跨注意力机制的Transformer。我们的输出词表大小为一个有3328个token的表,在这个表中, 3315个token是在训练集中至少出现了1000次,剩下的token是一些特殊的token,类似“<s>”</s>“”,和一些占位填充符。词表中的大部分词来自于中文,并且中文由于在训练集中的覆盖面,是唯一一个有OOV问题的语言。我们将语言信息也编码成一个one-hot向量,作为一个额外的输入。我们在训练的时间,简单地把所有数据放在一起,并且根据数据分布,在每个batch里,去进行采样。整个eocoder-decoder模型是在网络的输出和真实文字间,用交叉熵进行优化的。
实际上,我们有很多方法,去缩放一个基于encoder-decoder的多语言模型,在这篇文章中,我们主要研究下面四种模式的影响:
- 深度 vs 宽度;
- encoder vs decoder;
- 语言相关的模型容量 vs 语言无关的模型容量;
- 架构 vs 容量。
严格来说,模型容量并不完全等于模型的参数量,比如模型大小。对于有语言依赖的模型内容,推理时的模型容量,要小于训练时候的模型容量,这是因为在推理的时候,只有贡献的参数和对应于特定语言的参数被激活。为了简化本文的讨论,我们关注在训练时的模型容量,并且混用模型大小和容量。缩放模型大小,也会带来很多实际问题,比如模型的并行化支持。
本文的实验,是在来自9种语系的15种语言上进行的实验。总计235.4百万条语音,语音时长共计364.9千小时,这些数据采集自谷歌的声学搜索引擎,数据是完全匿名的,并且由标注人员标注成文本。本文使用的数据是之前论文使用的数据的20倍。据我们所知,这也是第一篇在这么大规模的数据集上做多语言实验的论文。与之前多语言的工作不同,我们关注在不同高资源语言间的干扰问题。在我们的设定里,我们最小的语言有大约7.7千小时的训练数据,大约是之前工作里最大的语言资源的7倍。这个规模的数据集又给训练效率带来了挑战。我们的每种语言的测试集,包含大约3到19k的语音,这些语音是从谷歌语音搜索引擎里面的采样出来的,并且和训练集没有重合。同样地,测试集也是完全匿名和手工转写的。
我们在训练的时候使用了80维的log mel特征,每帧的窗口大小为32ms,每两个窗口间有10ms的重叠。将连续3帧的特征堆叠起来,并做一个下采样,我们能获得240维的输入特征,这个特征的采样率为30ms。一个16维的one-hot语言向量,被送入到encoder中作为额外的输入,SpecAugment数据增强也被用来增强模型的鲁棒性。整个模型利用512个TPU核进行训练,除了10B(100亿)参数的模型,用了1024个TPU进行训练,这主要是由于每核16G的带宽限制。模型使用同步随机梯度下降进行优化。对于LSTM作decoder的模型,我们采样Adam优化器做优化,对于Transformer,我们采样Adafactor做优化器。transformer学习率优化策略也被使用,其中最大学习率为3e-4,warmup的步数为10k。
在这一节,我们展示我们在大规模数据集上建立高质量的多语言模型的研究结果,为了简单,我们只用平均WER作对比,并且只汇报每种语言的性能。
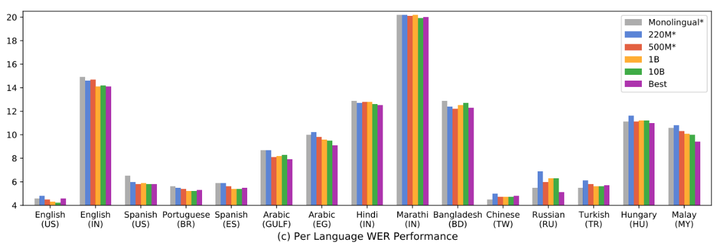
我们使用Conformer作为encoder和LSTM作为decoder,来构建单语的baseline模型,encoder包含17层conformer block,每个conformer层的模型维度为512,有8个head的attention,conformer内部卷积模块中,卷积核的大小为15。decoder是LSTM,包含2层640维的LSTM,隐藏单元的大小为2048。每个单语模型的大小为140M,并被用来预测跟该语言相关的token。平均的WER为9.29%。每种语言的性能如下图所示,其中英语(US)的WER最低,为4.6%,Marathi(IN)的WER最高为20.2%。拥有更多训练数据的语言,往往有更低的WER。
为了证明conformer作为多语言建模的encoder的有效性,我们对比了三种不同encoder,他们都以LSTM作为decoder。1. LSTM作为encoder,包含8层LSTM,每层有2048个隐藏单元,和640维的输出单元。2. ContextNet作为encoder,包含24层contextnet,每层有640维的隐藏单元,通道大小为2。3. Conformer作为encoder,包含17层conformer,每层有512维的隐藏层,这个设置和单语的模型一致。语言适应层(Language Adapter)在每个encoder层之间都被插入。这三种不同encoder结构的选择,是为了使得模型参数的总数尽肯能保持一致,都大约为220M。相比单语模型,多语模型的大小的增加主要来自于额外的语言适应层(Language Adapter)和输出词表的大小的增加。这三个模型的平均WER为11.86%,10.77%,和9.43%。这个结果充分展示了conformer作为多语ASR的encoder的效果。对比单语模型,尽管在质量上还不如单语模型,但是它在同时识别15种语言上,表现得很好。它在大概21个epoch时收敛,训练了大概120万step,而单语模型通常要训练到50个epoch。为了理解语言适应层的效果,我们做了下面的消融实验,为了快速进行实验,我们对比了模型在200k step时候的效果,大约此时是在第3.5个epoch。使用语言适应层,会带来语言依赖的参数,和一些模型大小上的增加。为了帮我们更好理解,我们训练了一个单独的适应模型,能使得所有模型共享相同的adapter transformation。因此,我们的模型能够大小能够摆脱adapter模型。在200k step时,这个模型获得了10.86%的平均WER,相对刚刚的baseline(带语言适应层),获得了10.38%的平均错误率。从这个对比,可以看到,在模型中加入语言适应层很重要。
除了用一个共享decoder,多头模型(用不同的decoder针对不同的语系)能够被用来增加模型容量,和之前的工作相同,我们为每种语系使用不同的decoder。总共5种语系会被使用,包括Germanic, Italic,Arabic,Indo-Iranan和其他语言。为了对比,我们确保单个decoder和多个decoder模型有相同的参数量:1. 单decoder模型有6层768维的LSTM,每层有3074维的隐藏单元。2. 多decoder,有5个decoder,每个decoder有2层640维的LSTM,每层有2048维的隐藏层单元。这两种模型都有354M的参数。在200k的step时,单个decoder的平均WER为10.13%,多个decoder的平均WER为10.28%,这建议我们在相同的模型大小下,我们用单个decoder,相比多个decoder要好。
为了提高我们多语模型的效果,我们进一步把模型参数从354M增加到500M,通过把模型的宽度从512维,增大到640维。把宽度从17层,增大到22层。这个增大后的模型,在200k step时能够获得9.63%的WER,并在1.1M step时,获得了9.13%的WER,能超过单语模型。然而,相比基本的220M的模型,它的训练速度慢了1/3,这是由于RNN的错误反向传播带来的。这个特性也使得用LSTM做decoder不适合进一步的模型扩增。相比LSTM,基于transformer的decoder模型,在训练时有更高的并行化能力。在相同的encoder架构下,我们建立了一个Transformer decoder模型,参数大约500M,有12层transformer,768维的模型维度,3072维的隐藏层维度,和8个attention head。它的平均WER是9.26%,比LSTM的WER要高一些,但是它的训练速度和220M baseline模型接近。因此,我们在后面的研究中,都用Transformer作为decoder。
在下面的实验中,我们想进一步增大Conformer作为encoder和Transformer作为decoder的模型的容量大小,实验结果如下表所示,L表示模型的层数,W表示模型的维度,loss是训练样本负log混淆,越低越好。speed是每秒训练的样本数。B0是baseline模型,“-”表示和B0没有区别。所有的E模型的参数量大小都为1B。

对比E1和E2,E5和E6,我们可以看到越深的模型取得了相比越宽的模型更好的效果。然而,越深的模型需要更长的时间去训练(2352 vs 3419)。对比E1-E4和E5-E7,增大encoder的容量,相比增大decoder的容量,能获得更好的结果。然而, 更大的decoder往往有更好的training loss。E4,这个模型平均把模型容量分给宽度和深度,在这个task上表现得并不好,相较而言,E3把更多地模型容量分给宽度,要表现得更好一些。最后,E8模型,首先把模型容量,平均分给encoder和decoder,然后把更多的容量分给depth,和E3的性能差不多。E3模型最终在600k step时收敛,大约10个epoch。最终获得了大约9.07%的平均WER。
在这个工作中,我们研究了如何构建一个多语言端到端ASR系统,我们通过增大模型容量来解决这个问题。随着模型的增大,我们观察到模型的效果不断增加,我们也能建立一个单独的多语言识别的ASR系统,这个系统能在高资源的语言上超过不同的单语模型。
想了解更多的AI技术干货,欢迎上华为云的AI专区,目前有AI编程Python等六大实战营供大家免费学习。
多语言ASR?没有什么听不懂,15种语言我全都要的更多相关文章
- ubuntu - 14.04,安装Go语言(谷歌公司开发的一种语言)
Go语言下载地址:https://storage.googleapis.com/golang/go1.5.1.linux-amd64.tar.gz 安装: 1,以root身份在shell里执行: ta ...
- [转自老马的文章]用MODI OCR 21种语言
作者:马健邮箱:stronghorse_mj@hotmail.com发布:2007.12.08更新:2012.07.09按照<MODI中的OCR模块>一文相关内容进行修订2012.07.0 ...
- 用MODI OCR 21种语言
作者:马健邮箱:stronghorse_mj@hotmail.com发布:2007.12.08更新:2012.07.09按照<MODI中的OCR模块>一文相关内容进行修订2012.07.0 ...
- 15. Go 语言“避坑”与技巧
Go 语言"避坑"与技巧 任何编程语言都不是完美的,Go 语言也是如此.Go 语言的某些特性在使用时如果不注意,也会造成一些错误,我们习惯上将这些造成错误的设计称为"坑& ...
- 苹果手机的SB系列(1)听不懂人话的sir
写在前面,因手买错了(至于怎么买错了不解释)手机才买了一个苹果,价格不扉,但实在让人很不爽.记下了SB的点点. Sir听不懂人话,我让他查非洲安哥拉的时间,却屡次返回美国安哥拉洲的时间,很自恋.
- [易学易懂系列|rustlang语言|零基础|快速入门|(15)|Unit Testing单元测试]
[易学易懂系列|rustlang语言|零基础|快速入门|(15)] 实用知识 Unit Testing单元测试 我们知道,在现代软件开发的过程中,单元测试对软件的质量极及重要. 今天我们来看看Rust ...
- C语言中返回字符串函数的四种实现方法 2015-05-17 15:00 23人阅读 评论(0) 收藏
C语言中返回字符串函数的四种实现方法 分类: UNIX/LINUX C/C++ 2010-12-29 02:54 11954人阅读 评论(1) 收藏 举报 语言func存储 有四种方式: 1.使用堆空 ...
- GO学习-(15) Go语言基础之包
Go语言基础之包 在工程化的Go语言开发项目中,Go语言的源码复用是建立在包(package)基础之上的.本文介绍了Go语言中如何定义包.如何导出包的内容及如何导入其他包. Go语言的包(packag ...
- 趣谈编程史第2期-这个世界缺少对C语言的敬畏,你不了解的C语言科普
这是我制作的编程语言科普系列视频的第二期,博客根据视频文案整理而成,提供给有需要的朋友阅读或使用. 视频地址:https://www.bilibili.com/video/av83627932/ ...
- Python 语言特性:编译+解释、动态类型语言、动态语言
1. 解释性语言和编译性语言 1.1 定义 1.2 Python 属于编译型还是解释型? 1.3 收获 2. 动态类型语言 2.1 定义 2.2 比较 2. 动态语言(动态编程语言) 3.1 定义 3 ...
随机推荐
- 【不限框架】超好用的3d开源图片预览插件推荐
今天给大家推荐一款超好用的图片预览插件-image-preview 简单说明 image-preview是一款主要面向移动端web应用,同时兼容pc,基于原生js,不限框架,react,vue,ang ...
- Dynamics CRM中自定义页面实现附件管理包含下载模板、上传、下载、删除
前言 附件使用的Dynamics CRM平台本身的注释表annotation存储,将附件转换成二进制字节流保存到数据库中,因自带的注释在页面中显示附件不够直观,特做了一个单独的附件管理自定义页面,通过 ...
- JVM 学习
目录 1. 类加载器及类加载过程 1.1 基本流程 1.2 类加载器子系统作用 1.3 类加载器角色 1.4 加载过程 (1) 加载 loading (2) 链接 linking 验证 verify ...
- 手算base64
base64人类群星闪耀时 CSP2021考了-- 什么鬼-- 不得不大骂一声--您有毒吧 base64是什么 Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基 ...
- Net 高级调试之六:对象检查之值类型、应用类型、数组和异常的转储
一.简介 今天是<Net 高级调试>的第六篇文章.记得我刚接触 Net 框架的时候,还是挺有信心的,对所谓的值类型和引用类型也能说出自己的见解,毕竟,自己一直在努力.当然这些见解都是书本上 ...
- 比STL还STL?——更全面的解析!
如何更快的使用高级数据结构 Part 1 :__gnu_pbds 库 __gnu_pbds 自带了封装好了的平衡树.字典树.hash等强有力的数据结构,常数还比自己写的小,效率更高 一.平衡树 #de ...
- mysq数据库查询之分组查询
一.什么是分组查询分组查询:将查询结果按照指定字段进行分组二.分组查询的基本语法select 查询字段 from 表名 [where 条件] group by 分组字段名 [having 条件表达式] ...
- C++ LibCurl实现Web指纹识别
Web指纹识别是一种通过分析Web应用程序的特征和元数据,以确定应用程序所使用的技术栈和配置的技术.这项技术旨在识别Web服务器.Web应用框架.后端数据库.JavaScript库等组件的版本和配置信 ...
- 聊一聊 .NET高级调试 内核模式堆泄露
一:背景 1. 讲故事 前几天有位朋友找到我,说他的机器内存在不断的上涨,但在任务管理器中查不出是哪个进程吃的内存,特别奇怪,截图如下: 在我的分析旅程中都是用户态模式的内存泄漏,像上图中的异常征兆已 ...
- 整合SpringBoot + Dubbo + Nacos 出现 Unable to make protected final java.lang.Class java.lang.ClassLoader.defineClass
版本 SpringBoot:2.7.3 Dubbo:3.0.4 Nacos:2.0.3 异常信息如下 Unable to make protected final java.lang.Class ja ...