selenium 开源UI测试工具

简介
selenium是一个用于Web应用程序测试的工具。selenium测试直接运行于浏览器网页上,可以模拟用户操作网页。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。
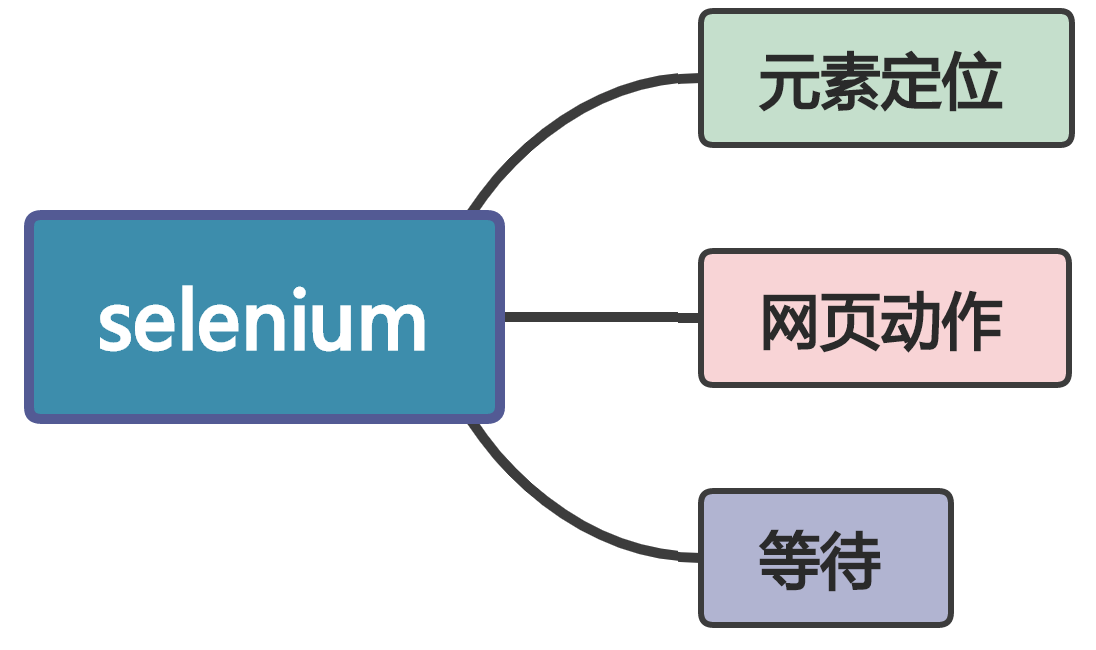
Selenium 能够实现的功能包括:定位网页元素、模拟点击、滑动、键盘输入等等操作。
selenium 支持的语言包括:
- Python
- CSharp
- Ruby
- JavaScript
- Kotlin
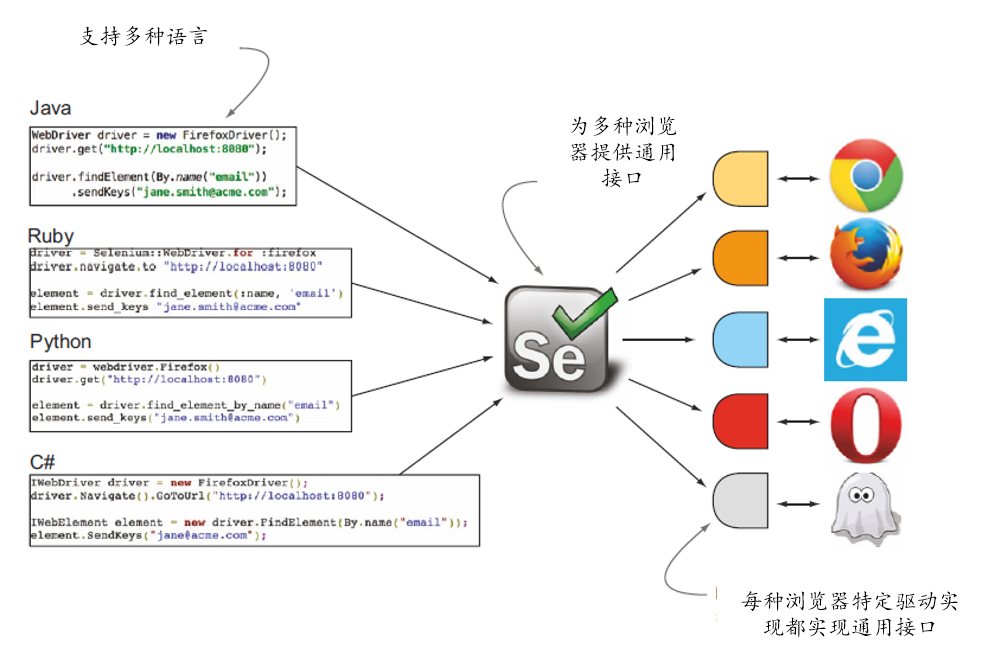
本教程以python操作selenium为例,说明selenium的使用方法。
简单使用
selenium 是第三方模块,首先安装该模块
pip install selenium >= 4.10.0
selenium模块 一共有4个大的版本,最新的4.x版本和之前的版本在语法上有较大的变化,所以安装最新的4.x版本,避免低版本带来的混乱。
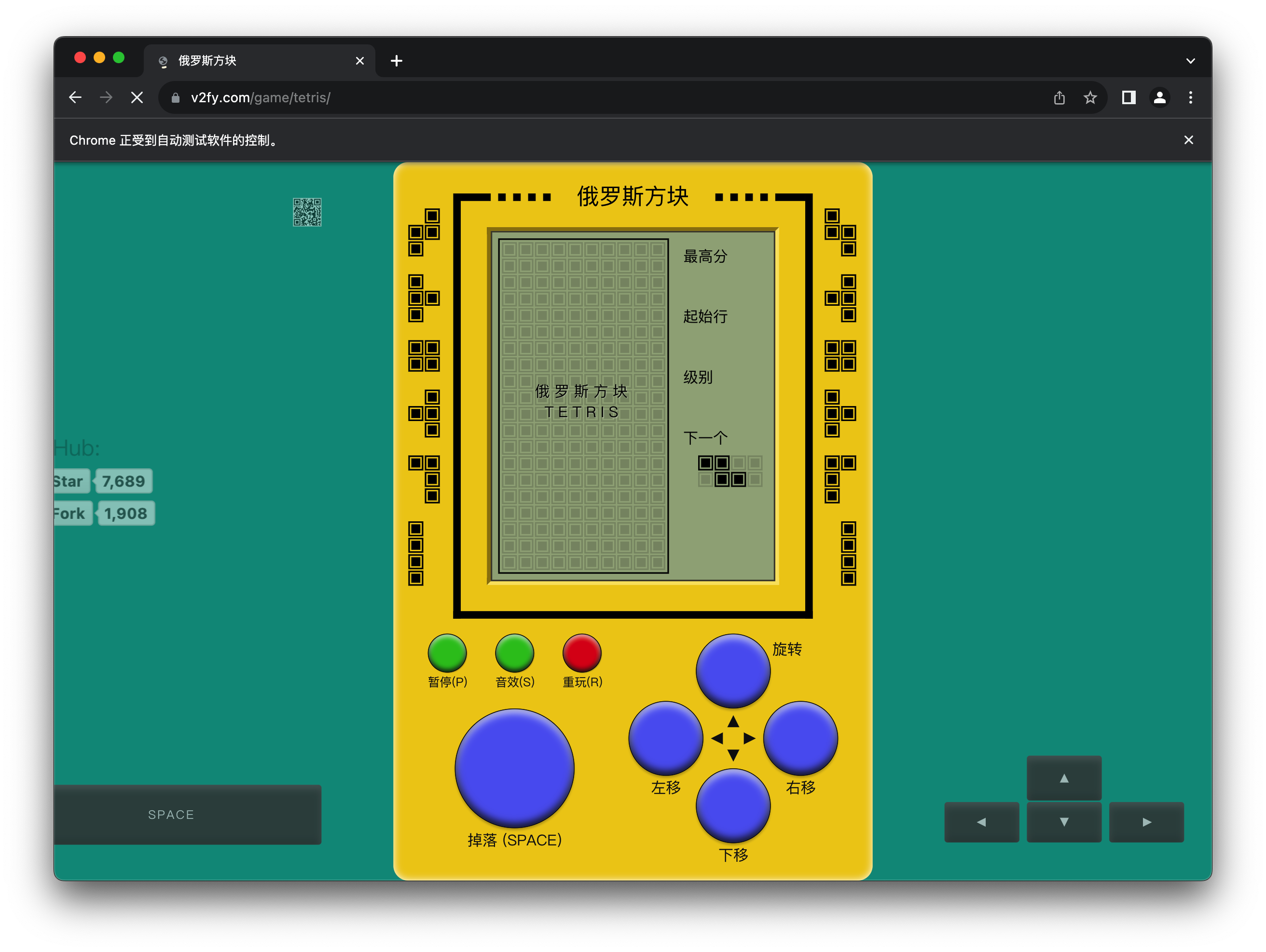
打开浏览器请求网页
import time
from selenium import webdriver
driver = webdriver.Chrome() # 初始化浏览器
driver.get("https://www.v2fy.com/game/tetris/") # 请求网页
time.sleep(10) # 为避免直接退出,睡眠10s
执行该代码,打开chrome浏览器,请求网页
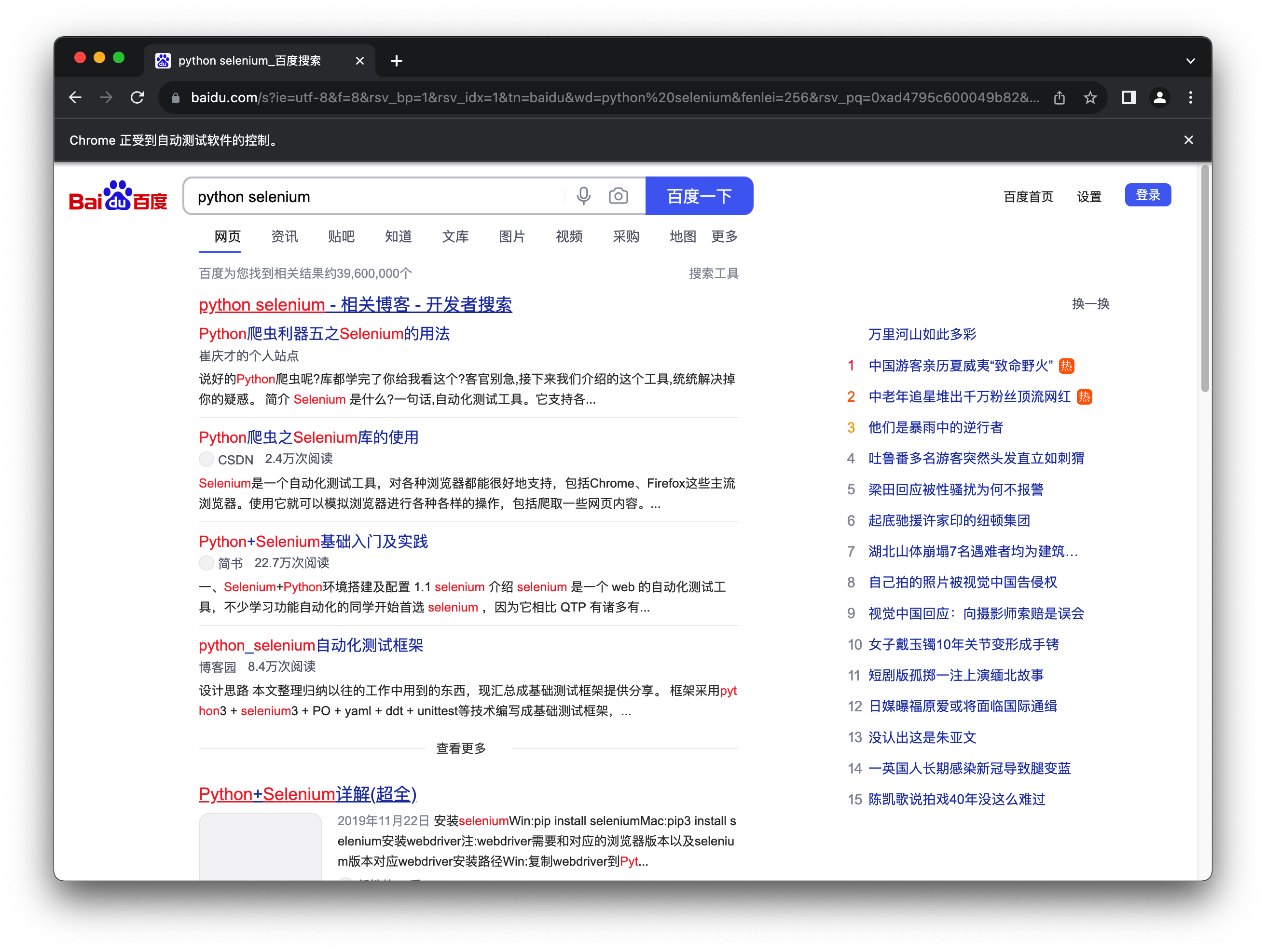
操作网页元素
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
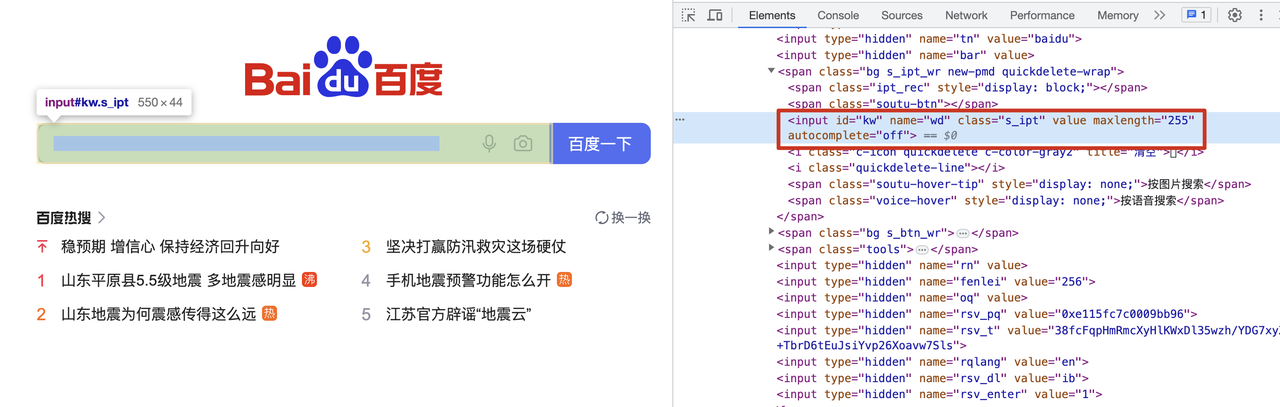
search_input = driver.find_element(By.NAME, "wd")
search_query = "python selenium"
search_input.send_keys(search_query)
search_input.send_keys(Keys.ENTER)
time.sleep(10)
操作网页的原理就是首先根据元素name定位找到了输入框
search_input = driver.find_element(By.NAME, "wd") # 定位名字叫wd的元素,也就是输入框
然后向输入框填充 python selenium,
search_query = "python selenium"
search_input.send_keys(search_query)
最后触发输入框的回车键。
search_input.send_keys(Keys.ENTER)
selenium 拥有的能力简单来说就是定位html中元素,操作元素。
元素定位
selenium 可以定位网页中元素,其拥有的方法和JavaScript类似,可以通过元素的特征定位,一共拥有8种定位元素的方法,分别是:
driver.find_element(By.ID,'ID')
driver.find_element(By.TAG_NAME,'NAME')
driver.find_element(By.CLASS_NAME,'CLASS_NAME')
driver.find_element(By.XPATH,'XPATH')
driver.find_element(By.TAG_NAME,'TAG_NAME')
driver.find_element(By.CSS_SELECTOR,'CSS_SELECTOR')
driver.find_element(By.LINK_TEXT,'LINK_TEXT')
driver.find_element(By.PARTIAL_LINK_TEXT,'PARTIAL_LINK_TEXT')
- 根据元素ID定位
- 根据元素name定位
- 根据元素class_name定位
- 根据元素xpath定位
- 根据元素tag_name定位
- 根据元素css定位
- 根据超链接文本定位
ID
在id定位里,会返回第一个id属性匹配的元素,如果没有元素匹配,会抛出NoSuchElementException异常。
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
</form>
</body>
<html>
可以这样定位表单元素form:
from selenium.webdriver.common.by import By
login_form = driver.find_element(By.ID 'loginForm')
Name
在name定位里,会返回第一个name属性匹配的元素,如果没有元素匹配,会抛出NoSuchElementException异常。
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
</form>
</body>
<html>
username 和 password元素 可以这样定位:
from selenium.webdriver.common.by import By
username = driver.find_element(By.NAME, 'username')
password = driver.find_element(By.NAME, 'password')
class_name
知道class就使用这个定位,只返回匹配的第一个,无元素匹配,会抛出NoSuchElementException异常。
实例:
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
定位p元素:
content = driver.find_element(By.CLASS_NAME, 'content')
xpath
XPath是用来定位XML文档节点的语言。不过HTML可以看成是XML(XHTML)的一种实现。selenium用户可以使用这个强力的语言来瞄准Web应用的元素。 XPath延伸了用id或者name属性来定位的单一方法,开创了许多可能性,例如定位页面的第三个复选框
用XPath的主要理由之一,就是你想定位的元素没有合适的id或者name属性的时候,你可以用XPath来对元素进行绝对定位(不推荐)或者把这个元素和另外一个有确定id或者name的元素关联起来(即相对定位)。XPath定位器也可以用来找出那些具有id,name以外属性的元素。
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
<html>
form元素可以这样定位:
login_form = driver.find_element(By.xpath, "/html/body/form[1]")
login_form = driver.find_element(By.xpath, "//form[1]")
login_form = driver.find_element(By.xpath,"//form[@id='loginForm']")
这里下标表示是从1开始的
- 绝对路径(如果HTML有细微的改变就会失效)
- HTML的第一个form元素
- id属性为'loginForm'的form元素
username元素可以这样定位:
username = driver.find_element(By.xpath,"//from[input/@name='username']")
username = driver.find_element(By.xpath,"//form[@id='loginForm']/input[1]")
username = driver.find_element(By.xpath,"//input[@name='username']")
- 第一个form元素的 name属性是'username'的input子元素
- id属性为'loginForm'的form元素的第一个input子元素
- name属性为'username'的第一个input元素
clear 按钮可以这样定位:
clear_button = driver.find_element(By.xpath, "//input[@name='continue'][@type='button']")
clear_button = driver.find_element(By.xpath, "//form[@id='loginForm']/input[4]")
- type属性为'button',name属性为'continue'的第一个input元素
- id为'loginForm'的表单的第四个input子元素
tag_name
知道元素标签名就使用这个定位,如果没有元素匹配,会抛出NoSuchElementException异常。
实例:
<html>
<body>
<h1>Welcome</h1>
<p>Site content goes here.</p>
</body>
<html>
可以这样定位标题元素(h1):
heading1 = driver.find_element(By.TAG_NAME, 'h1')
css
如果你能用css选择器的语法来表述一个元素,那么就选这个,只返回匹配的第一个,无元素匹配,会抛出NoSuchElementException异常。
实例:
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
定位p元素:
content = driver.find_element(By.CSS_SELECTOR, 'p.content')
Link text
链接标签使用了什么文本,那么通过链接的文本进行定位。在超链接定位里,会返回第一个文本属性匹配的链接,如果没有元素匹配,会抛出NoSuchElementException异常。
实例:
<html>
<body>
<p>Are you sure you want to do this?</p>
<a href="continue.html">Continue</a>
<a href="cancel.html">Cancel</a>
</body>
<html>
可以这样定位 continue.html链接:
# LINK_TEXT 需要完全匹配
continue_link = driver.find_element(By.LINK_TEXT, 'Continue')
# PARTIAL_LINK_TEXT 可以模糊匹配
continue_link = driver.find_element(By.PARTIAL_LINK_TEXT, 'Conti')
知识加油站: find_element 方法特点是查找到匹配的元素,返回第一个。如果想返回所有的元素可以使用方法find_elements。参考"登录算法仓"中的使用。
网页动作
用selenium做自动化,有时候会遇到需要模拟鼠标操作才能进行的情况,比如单击、双击、点击鼠标右键、拖拽等等。而selenium给我们提供了一个类来处理这类事件——ActionChains。ActionChains 能够模拟键盘、鼠标等设备的操作。
ActionChains基本用法
首先需要了解ActionChains的执行原理,当你调用ActionChains的方法时,不会立即执行,而是会将所有的操作按顺序存放在一个队列里,当你调用perform()方法时,队列中的时间会依次执行。
这种情况下我们可以有两种调用方法:
链式写法
menu = driver.find_element_by_css_selector(".nav")
hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1")
ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform()
分步写法
menu = driver.find_element_by_css_selector(".nav")
hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1")
actions = ActionChains(driver)
actions.move_to_element(menu)
actions.click(hidden_submenu)
actions.perform()
两种写法本质是一样的,ActionChains都会按照顺序执行所有的操作。
动作列表
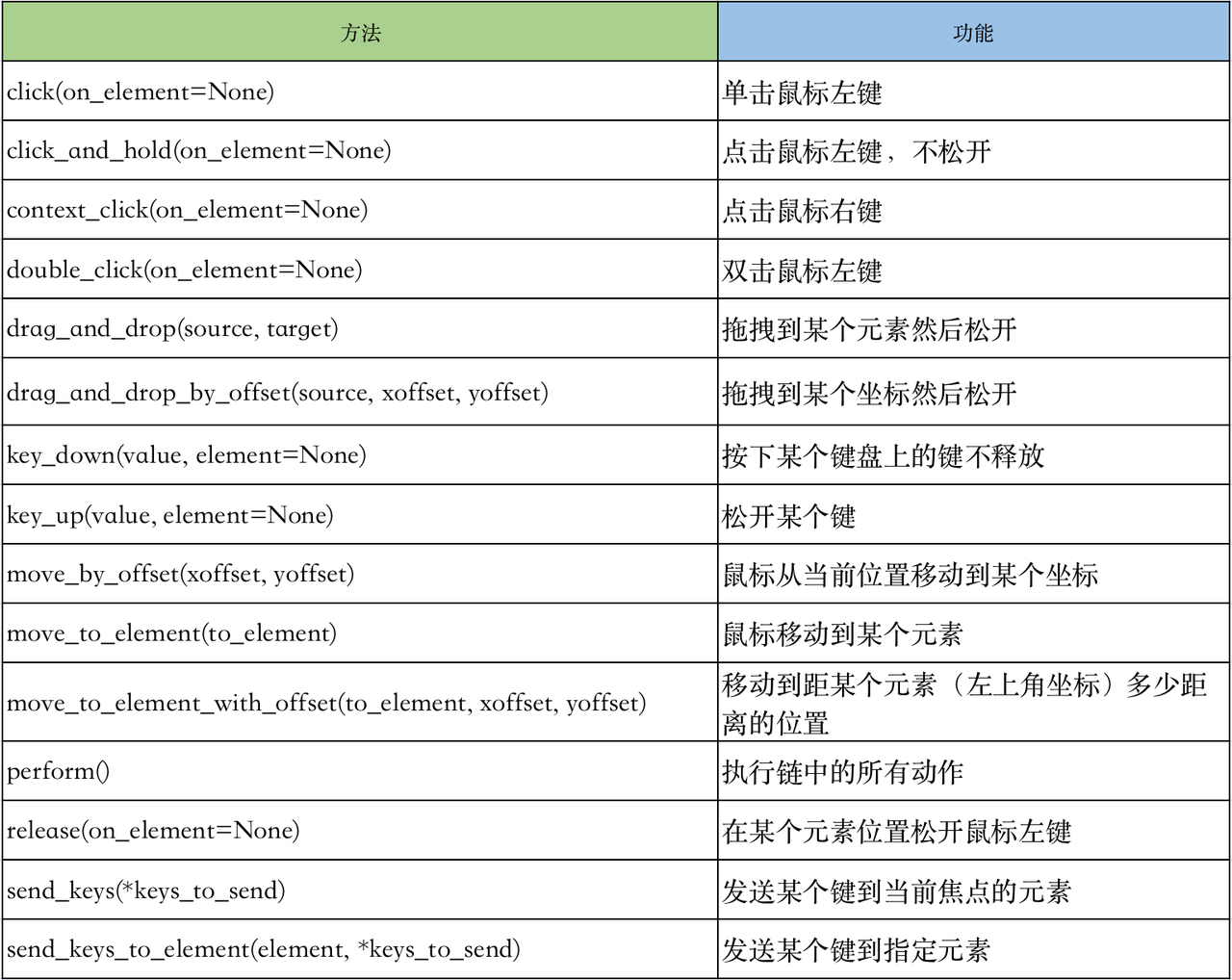
Click
Click 模拟鼠标左键的点击事件,也就是最常用的鼠标点击
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
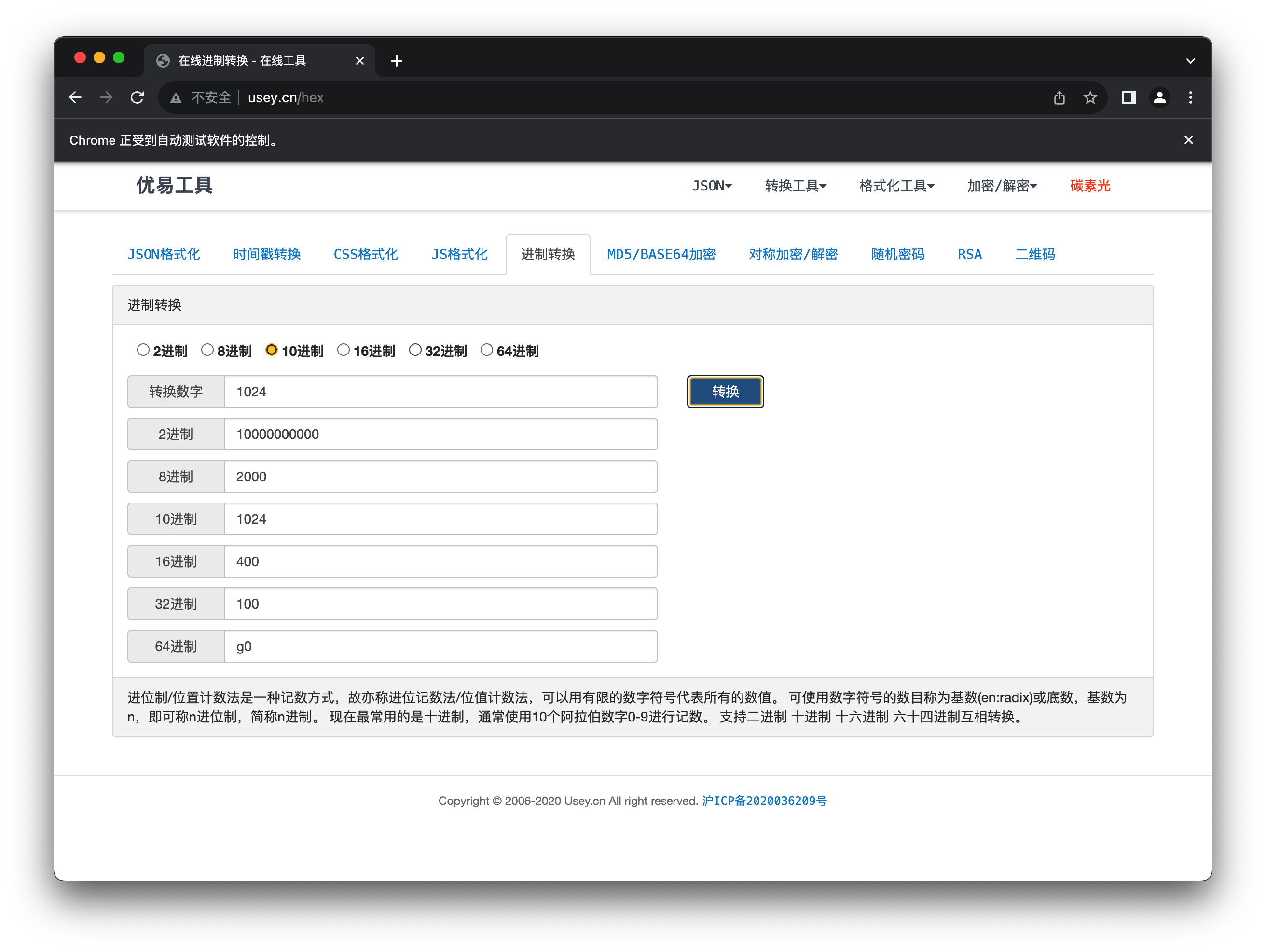
driver.get("http://www.usey.cn/hex")
# 向转换数字输入框中输入1024
search_input = driver.find_element(By.ID, "ipt_hex")
search_input.send_keys("1024")
time.sleep(3)
# 定位转换按钮
send_btn = driver.find_element(By.CLASS_NAME, "btn-primary")
# 点击转换按钮
ActionChains(driver).click(send_btn).perform()
time.sleep(10)
key_down key_up
key_down动作是按下一个按键,对应的key_up是释放一个按键。通常这两个操作时成对出现的。模拟在数据框中以shfit + 小写字母 输入,将小写字母变成大写字母。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
time.sleep(3)
search_input = driver.find_element(By.ID, "kw")
ActionChains(driver).key_down(Keys.SHIFT)
actions = ActionChains(driver)
# 模拟按下 Shift 键
actions.key_down(Keys.SHIFT)
# 在输入框中输入文字
actions.send_keys_to_element(search_input, "hello world")
# 模拟释放 Shift 键
actions.key_up(Keys.SHIFT)
# 执行以上的操作
actions.perform()
time.sleep(10)
send_keys
send_keys的功能有两个:
- 向当前元素发送文字
- 向当前元素发送按键
在搜索框上有两种方法可以触发搜索,一种是点击搜索按钮;另一种是搜索框绑定回车键。其中bing.com支持第二种方法,所以可以在输入框输入完成之后发送回车按键完成搜索。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("https://www.bing.com/")
time.sleep(3)
search_input = driver.find_element(By.ID, "sb_form_q")
search_input.send_keys("中国最大的城市")
search_input.send_keys(Keys.ENTER)
time.sleep(10)
等待
为什么要使用等待?
在自动化测试脚本的运行过程中,webdriver操作浏览器的时候,对于元素的定位是有一定的超时
时间,大致在1-3秒
如果这个时间内仍然定位不到元素,就会抛出异常,中止脚本执行
我们可以通过在脚本中设置等待的方式来避免由于网络延迟或浏览器卡顿导致的偶然失败
常用的三种等待方式
- 强制等待
- 隐式等待
- 显示等待
强制等待
利用time模块的sleep方法来实现,最简单粗暴的等待方法
强制等待,不管你浏览器是否加载完成,都得给我等待3秒,3秒一到,继续执行下面的代码
# -*- coding: utf-8 -*-
import time
from selenium import webdriver
driver = webdriver.Chrome()
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 强制等待3秒
time.sleep(3)
driver.find_element_by_css_selector("#kw").send_keys("selenium")
# 退出
driver.quit()
弊端
不建议用这种等待方法,严重影响代码的执行速度
隐式等待
implicitly_wait()方法用来等待页面加载完成(直观的就是浏览器tab页上的小圈圈转完)网页加载完成则执行下一步
隐式等待只需要声明一次,一般在打开浏览器后进行声明。声明之后对整个drvier的生命周期都有效,后面不用重复声明
import time
from selenium import webdriver
driver = webdriver.Chrome()
# 打开百度首页
driver.get(r'https://www.baidu.com/')
# 隐性等待5秒
driver.implicitly_wait(5)
driver.find_element_by_css_selector("#kw").send_keys("selenium")
# 退出
driver.quit()
弊端
程序会一直等待整个页面加载完成,直到超时
有时候我需要的那个元素早就加载完成了,只是页面上有个别其他元素加载特别慢,我仍要等待页
面全部加载完成才能执行下一步
显示等待
WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了。
它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步。否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
显示等待必须在每个需要等待的元素前面进行声明
class WebDriverWait:
def __init__(
self,
driver,
timeout: float,
poll_frequency: float = POLL_FREQUENCY,
ignored_exceptions: typing.Optional[WaitExcTypes] = None,
):
pass
参数说明:
- driver:浏览器驱动
- timeout:等待时间
- poll_frequency:检测的间隔时间,默认0.5s
- ignored_exceptions:超时后的异常信息,默认抛出NoSuchElementException
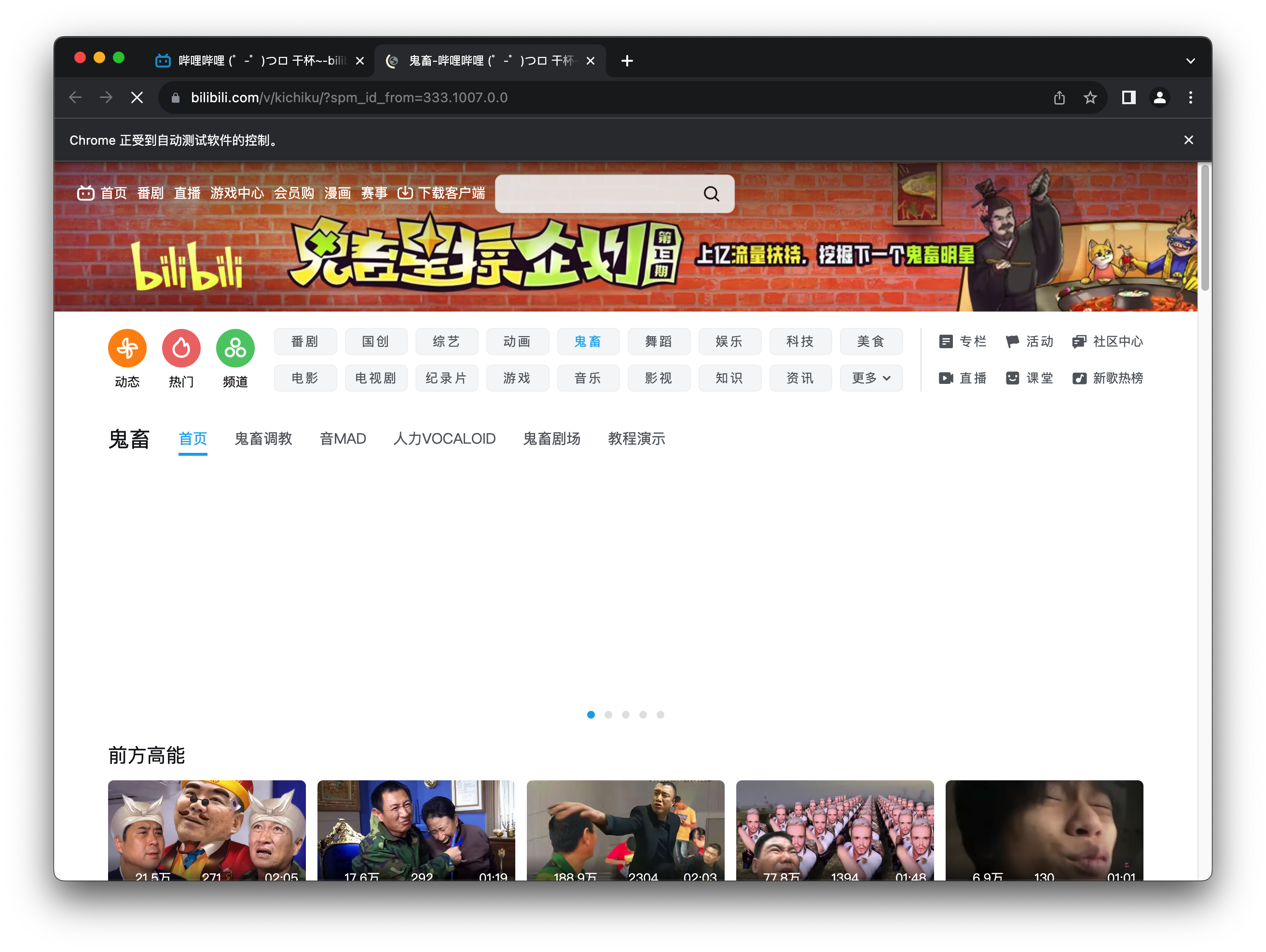
打开b站鬼畜区示例
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://www.bilibili.com/")
time.sleep(3)
login_btn = WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located((By.LINK_TEXT, "鬼畜")))
#点击元素
login_btn.click()
time.sleep(10)
显示等待常用方法
#判断当前页面的title是否精确等于预期,返回布尔值
WebDriverWait(driver,10).until(EC.title_is("百度一下,你就知道"))
#判断当前页面的title是否包含预期字符串,返回布尔值
WebDriverWait(driver,10).until(EC.title_contains('new'))
#判断当前页面的url是否精确等于预期,返回布尔值
WebDriverWait(driver,10).until(EC.url_contains('https://www.baidu.com'))
#判断当前页面的url是否包含预期字符串,返回布尔值
WebDriverWait(driver,10).until(EC.url_contains('baidu'))
#判断当前页面的url是否满足字符串正则表达式匹配,返回布尔值
WebDriverWait(driver,10).until(EC.url_matches('.+baidu.+'))
#判断元素是否出现,只要有一个元素出现,返回元素对象
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.ID,'kw')))
#判断元素是否可见,返回元素对象
WebDriverWait(driver,10).until(EC.visibility_of(driver.find_element(By.ID,'kw'))
)
#判断元素是否包含指定文本,返回布尔值
WebDriverWait(driver,10).until(EC.text_to_be_present_in_element((By.NAME,'tj_trn
ews'),'新闻'))
#判断该frame是否可以switch进去,如果可以的话,返回True并且switch进去
WebDriverWait(driver,10,).until(EC.frame_to_be_available_and_switch_to_it(By.xpa
th,'//iframe'))
#判断某个元素是否可见并且是可点击的,如果是的就返回这个元素,否则返回False
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.NAME,'tj_trnews'))
)
#判断某个元素是否被选中,一般用在下拉列表
WebDriverWait(driver,10).until(EC.element_to_be_selected(driver.find_element(By.
xpath,'//input[@type="checkbox"]')))
#判断页面上是否存在alert,如果有就切换到alert并返回alert的内容
WebDriverWait(driver,10).until(EC.alert_is_present())
selenium 开源UI测试工具的更多相关文章
- 2014 非常好用的开源 Android 测试工具
http://www.php100.com/html/it/mobile/2014/1015/7495.html 当前有很大的趋势是转向移动应用平台,Android 是最广泛使用的移动操作系统,201 ...
- 开源负载测试工具k6比JMeter更容易的5件事
k6是GitHub上提供的开源负载测试工具.它是用Go编写的,并运行用JavaScript编写的测试脚本.它受到了开发人员,测试人员和DevOps团队的强烈兴趣,并拥有超过4400名GitHub明星. ...
- 推荐10款免费的在线UI测试工具
发布网站之前至关重要的一步是网站测试.网站测试要求我们全面地运行网站并通过所有基本测试,如响应式设计测试.安全测试.易用性测试.跨浏览器兼容性.网站速度测试等. 网站测试对SEO.搜索引擎排名.转换率 ...
- 开源API测试工具 Hitchhiker v0.8 - 自动化测试结果统计
Hitchhiker 是一款开源的支持多人协作的 Restful Api 测试工具,支持自动化测试, 数据对比,压力测试,支持脚本定制请求,可以轻松部署到本地,和你的team成员一起协作测试Api. ...
- 开源Web测试工具介绍
HtmlUnitHtmlUnit 是 JUnit 的扩展测试框架之一.HtmlUnit 将返回文档模拟成 HTML,这样您便可以直接处理这些文档了.HtmlUnit 使用例如 table.form 等 ...
- 开源API测试工具 Hitchhiker v0.4更新 - 没有做不到,只有想不到
Hitchhiker 是一款开源的 Restful Api 测试工具,支持Schedule, 数据对比,压力测试,支持上传脚本定制请求,可以轻松部署到本地,和你的team成员一起管理Api. 详细介绍 ...
- 开源API测试工具 Hitchhiker v0.5更新 - 完善细节
Hitchhiker 是一款开源的支持多人协作的 Restful Api 测试工具,支持Schedule, 数据对比,压力测试,支持上传脚本定制请求,可以轻松部署到本地,和你的team成员一起管理Ap ...
- 开源API测试工具 Hitchhiker v0.6更新 - 改进压力测试
Hitchhiker 是一款开源的支持多人协作的 Restful Api 测试工具,支持Schedule, 数据对比,压力测试,支持上传脚本定制请求,可以轻松部署到本地,和你的team成员一起协作测试 ...
- 开源API测试工具 Hitchhiker v0.7更新 - Schedule的对比diff
Hitchhiker 是一款开源的支持多人协作的 Restful Api 测试工具,支持Schedule, 数据对比,压力测试,支持脚本定制请求,可以轻松部署到本地,和你的team成员一起协作测试Ap ...
- 开源API测试工具 Hitchhiker v0.10 - 中文版
Hitchhiker 是一款开源的支持多人协作的 Restful Api 测试工具,支持自动化测试, 数据对比,压力测试,支持脚本定制请求,可以轻松部署到本地,和你的team成员一起协作测试Api. ...
随机推荐
- Ansible自动化部署工具-组件及语法介绍
大家好,我是蓝胖子,我认为自动化运维要做的事情就是把运维过程中的某些步骤流程化,代码化,这样在以后执行类似的操作的时候就可以解放双手了,让程序自动完成.避免出错,Ansible就是这方面非常好用的工具 ...
- P-III曲线水文频率计算程序(方法)
P-III曲线水文频率计算程序(方法) 最近遇到水文频率曲线拟合计算相关的问题,在网上查阅了一下,毕竟是专业性比较强的知识内容,好像没有比较系统全面的资料,一时兴起,做了一些研究,总结了一下所了解的一 ...
- 在 Ubuntu 22.04 系统上为 SSH 开启基于时间的 TOTP 认证
前言 一次性密码(英语:one-time password,简称OTP),又称动态密码或单次有效密码,是指电脑系统或其他数字设备上只能使用一次的密码,有效期为只有一次登录会话或一段短时间内.基于时间的 ...
- 平稳扩展:可支持RevenueCat每日12亿次API请求的缓存
平稳扩展:可支持RevenueCat每日12亿次API请求的缓存 目录 平稳扩展:可支持RevenueCat每日12亿次API请求的缓存 低延迟 建立连接池 故障检测 Up and warm 对故障做 ...
- 文心一言 VS 讯飞星火 VS chatgpt (148)-- 算法导论12.2 3题
三.用go语言,写出过程 TREE-PREDECESSOR 的伪代码. 文心一言: 以下是使用Go语言编写的TREE-PREDECESSOR函数的伪代码: func TREE-PREDECESSOR( ...
- [CF1364E] X-OR
X-OR 题面翻译 题目描述 本题是交互题. 有一个固定的长度为 \(n\) 的排列 \(P\),其值域为 \([0,n-1]\),你可以进行不超过 \(4269\) 次询问,之后你需要输出这个排列 ...
- [THUPC 2023 初赛] 背包
题目描述 本题中,你需要解决完全背包问题. 有 \(n\) 种物品,第 \(i\) 种物品单个体积为 \(v_i\).价值为 \(c_i\). \(q\) 次询问,每次给出背包的容积 \(V\),你需 ...
- [ABC262C] Min Max Pair
Problem Statement You are given a sequence $a = (a_1, \dots, a_N)$ of length $N$ consisting of integ ...
- vue-test -------style绑定
<template> <p :style="{color:activeColor,fontSize:fontsize+'px'}"></p> & ...
- 关于SpringBoot中出现的循环依赖问题
环境: SpringBoot2.7.8 背景: 在增加出库订单时需要对物品表的的数量进行修改 因此我在OutboundController中创建了几个公共方法,并将其注入到Spring中,结果给我报了 ...