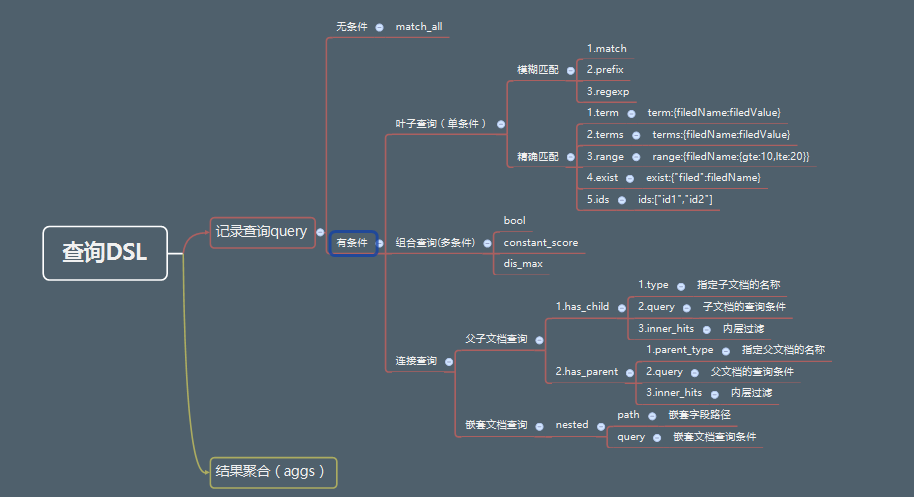
Elasticsearch 索引与文档的常用操作总结二:复杂条件查询
本文为博主原创,未经允许不得转载:
1. 查询所有:match_all
GET /es_db/_doc/_search
{
"query":{
"match_all":{}
}
}
2.有查询条件
2.1 模糊匹配
模糊匹配主要是针对文本类型的字段,文本类型的字段会对内容进行分词,对查询时,也会对搜索条件进行分词,然后通过倒排索引查找到匹配的数据,模糊匹配主要通过match等参数来实现。
match : 通过match关键词模糊匹配条件内容,,模糊匹配,需要指定字段名,但是输入会进行分词
prefix : 前缀匹配
regexp : 通过正则表达式来匹配数据
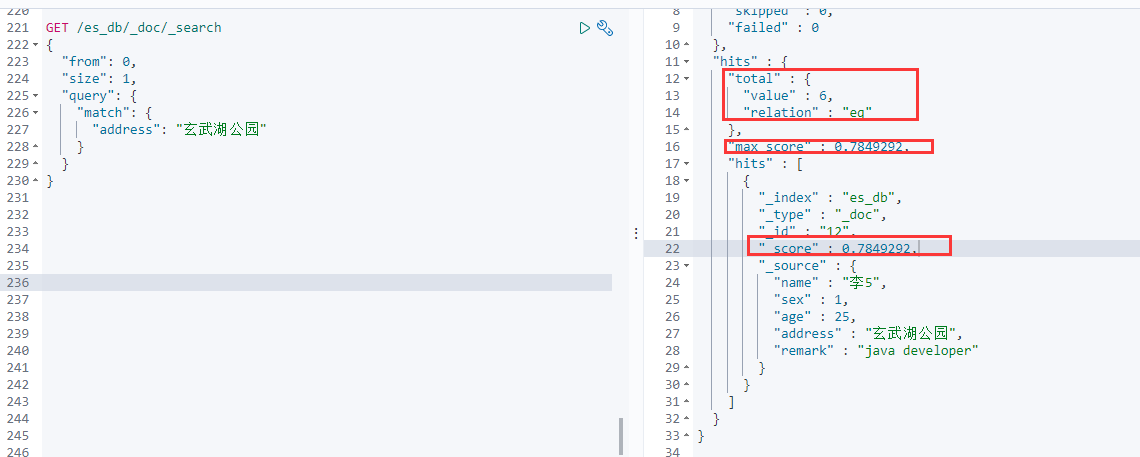
GET /es_db/_doc/_search
{
"from": 0,
"size": 1,
"query": {
"match": {
"address": "玄武湖公园"
}
}
}
多字段模糊匹配查询与精准查询 multi_match
POST /es_db/_doc/_search
{
"query": {
"multi_match": {
"query": "张三",
"fields": [
"address",
"name"
]
}
}
}
类比 mysql :
SQL: select * from student where name like '%张三%' or address like '%张 三%
POST /es_db/_doc/_search
{
"query": {
"term": {
"name": "admin"
}
}
}
POST /es_db/_doc/_search
{
"query": {
"query_string": {
"query": "admin OR 南京",
"fields": [
"name",
"address"
]
}
}
}
POST /es_db/_doc/_search
{
"query": {
"range": {
"age": {
"gte": 25,
"lte": 28
}
}
},
"from": 0,
"size": 2,
"_source": [
"name",
"age",
"book"
],
"sort": {
"age": "desc"
}
}
Elasticsearch 索引与文档的常用操作总结二:复杂条件查询的更多相关文章
- 007-elasticsearch5.4.3【一】概述、Elasticsearch 访问方式、Elasticsearch 面向文档、常用概念
一.概述 Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上. Elasticsearch 也是使用 Java 编写的,它的内部使用 L ...
- elasticsearch查询篇索引映射文档数据准备
elasticsearch查询篇索引映射文档数据准备 我们后面要讲elasticsearch查询,先来准备下索引,映射以及文档: 我们先用Head插件建立索引film,然后建立映射 POST http ...
- Elastic Stack 笔记(四)Elasticsearch5.6 索引及文档管理
博客地址:http://www.moonxy.com 一.前言 在 Elasticsearch 中,对文档进行索引等操作时,既可以通过 RESTful 接口进行操作,也可以通过 Java 也可以通过 ...
- Elasticsearch 7.x文档基本操作(CRUD)
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html 1.添加文档 1.1.指定文档ID PUT ...
- es之对文档进行更新操作
5.7.1:更新整个文档 ES中并不存在所谓的更新操作,而是用新文档替换旧文档: 在内部,Elasticsearch已经标记旧文档为删除并添加了一个完整的新文档并建立索引.旧版本文档不会立即消失 ,但 ...
- elasticsearch 基础 —— 分布式文档存储原理
路由一个文档到一个分片中 当索引一个文档的时候,文档会被存储到一个主分片中. Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 ...
- ElasticSearch 集群基本概念及常用操作汇总(建议收藏)
内容来源于本人的印象笔记,简单汇总后发布到博客上,供大家需要时参考使用. 原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94 目录: Elas ...
- shift+alt 可对notepadplusplus 打开的文档进行列操作
shift+alt 可对notepadplusplus 打开的文档进行列操作
- flask - fastapi (python 异步API 框架 可以自动生成swagger 文档) 常用示例 以及整合euraka nacos
flask - fastapi (python 异步API 框架 可以自动生成swagger 文档) 常用示例: 之前使用 flask 需要手动写文档, 这个可以自动生成, fastapi ...
- Elasticsearch技术解析与实战(二)文档的CRUD操作
启动Elasticsearch和kibana 访问Elasticsearch:http://localhost:9200/?pretty 访问kibana:http://localhost:5601 ...
随机推荐
- Java在指定路径下执行cmd命令的方法
目前状态:毕业设计ing 背景: 做毕设时,由于需要将python的运行效果展示出来,所以使用了Java写了一个前端的界面.但是在使用Java对python的脚本进行调用时就尴尬了,出错-- 这里也许 ...
- 性能测试常见面试题(Loadrunner)
https://blog.csdn.net/xiangxiupp/article/details/53862056
- 痞子衡嵌入式:Farewell, 我的写博故事2023
-- 题图:苏州虎丘塔 2023 年的最后一天,照旧写个年终总结.昨晚和同门师兄弟一起吃饭,有个师弟告诉痞子衡,微博上一个拥有 22.3W 粉丝的嵌入式同行今年 4 月发过一个吐槽微博,说恩智浦 MC ...
- Javac多模块化编译
转载:原文链接 从SDK9开始,Java支持多模块编译.那么,怎么用javac实现多模块编译呢? 项目介绍 先来看看我们的项目. 首先lib文件夹下是依赖模块,有一个hello模块.hello模块包含 ...
- 文心一言 VS 讯飞星火 VS chatgpt (25)-- 算法导论4.2 7题
七.设计算法,仅使用三次实数乘法即可完成复数 a+bi和c+di 相乘.算法需接收a.b.c和d 为输入,分别生成实部 ac-bd 和虚部ad+bc. 文心一言: 可以使用如下算法来计算复数 a+bi ...
- maven系列:依赖管理和依赖范围
目录 一.依赖管理 使用坐标导入jar包 使用坐标导入 jar 包 – 快捷方式 使用坐标导入 jar 包 – 自动导入 二.依赖范围 三.可选依赖 四.排除依赖 一.依赖管理 使用坐标导入jar包 ...
- 华为云GaussDB城市沙龙活动走进安徽,助力金融行业数字化转型
本文分享自华为云社区<华为云GaussDB城市沙龙活动走进安徽,助力金融行业数字化转型>,作者: GaussDB 数据库 . 近日,华为云GaussDB数据库城市沙龙·安徽站圈层活动顺利举 ...
- 解析Stream foreach源码
摘要:串行流比较简单,对于parallelStream,站在它背后的是ForkJoin框架. 本文分享自华为云社区<深入理解Stream之foreach源码解析>,作者:李哥技术 . 前言 ...
- 再谈BOM和DOM(4):DOM0/DOM2事件处理分析
JavaScript能够让网站对用户的各种操作及时做出"反馈",响应用户交互行为,而这些就是:DOM,事件以及事件处理 DOM就是操作的元素,这个看<再谈BOM和DOM(1) ...
- 【教程】app备案流程简单三部曲即可完成
[教程]app备案流程简单三部曲即可完成 APP备案流程包括以下步骤: 1. 开发者实名认证:在提交备案申请之前,开发者需要通过移动应用开发平台进行实名认证.这个步骤需要提供身份证号码.姓名.联系 ...