python--批量下载豆瓣图片之升级版本
周末下雨没法出门,刷刷豆瓣看看妹子,本想拿以前脚本下载点图片,结果发现运行失败,之前版本为《python--批量下载豆瓣图片》,报错HTTP Error 403: Forbidden,网上一堆的文章都是写在request的header中添加User-Agent模拟浏览器请求就可以解决,但毫无卵用!
在调试过程中无意发现,及时在浏览器地址栏中手动输入图片地址,也出现430 Forbidden的提示,百度一上午没找到答案,略微郁闷,考虑到手动能点击链接能显示图片,于是想通过模拟浏览器操作的方式来自动保存图片,百度一下午Selenium WebDriver,发现图片也显示出来了,就是没法右键保存,百度又是人云亦云的那些东西,折腾很久也没成功。
今天灵光一线,既然手动点击链接变可以,为啥通过地址栏输入的链接就不行呢,两种方式的地址完全相同,不存在手动点击链接后链接变化的问题,那问题会不会就出在两种请求所附带的请求数据上,由于是get方式,请求数据都存放请求头和URL链接中,通过Firefox的开发者工具>>开发者工具栏>>网络选项可以看到请求头内容:

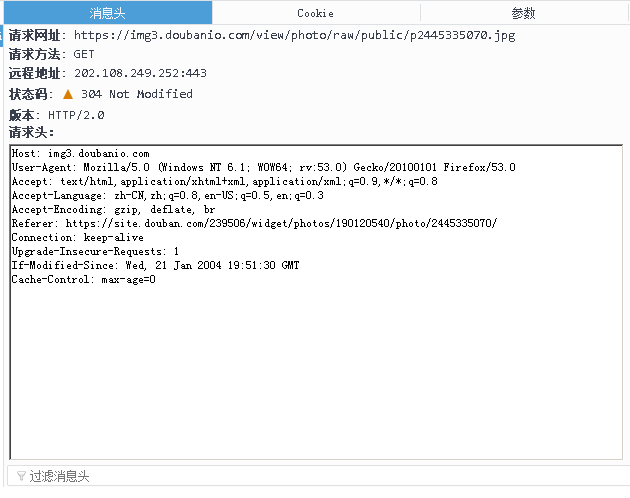
尝试在脚本中也增加请求头中添加Referer项,发现程序顺利通过,看来豆瓣通过这一项来判断,就跟空手去人家婚礼蹭饭一样,不弄个红包装一下,很可能会被打出来!
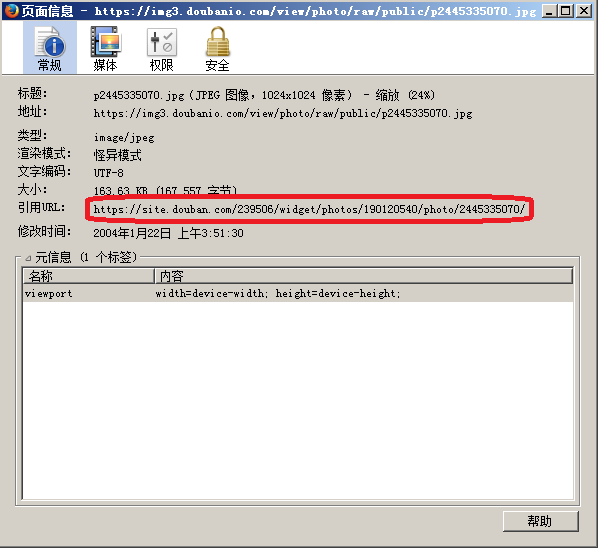
在图片显示窗口,右键“查看页面信息”,也可以很容易找到引用URL一项:
代码附上:
# -*- coding:utf8 -*-
import urllib2, urllib, socket
import re
import requests
from lxml import etree
import os, time, random DEFAULT_DOWNLOAD_TIMEOUT = 30 def check_save_path(save_path):
if not os.path.exists(save_path):
os.makedirs(save_path) def get_image_name(image_link):
file_name = os.path.basename(image_link)
return file_name def get_image_id(file_name):
file_id = file_name[0: file_name.rindex('.')]
return file_id def save_image(image_link, save_path):
file_name = get_image_name(image_link)
file_id = get_image_id(file_name)
file_path = save_path + "\\" + file_name
print("准备下载{0} 到{1}".format(image_link, file_path))
try: headers = {}
headers["User-Agent"] = 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0'
headers["Referer"] = 'https://site.douban.com/239506/widget/photos/190120540/photo/{0}/'.format(file_id)
file_handler = open(file_path, "wb")
req = urllib2.Request(url=image_link, headers=headers)
opener = urllib2.build_opener()
image_handler = opener.open(req).read()
file_handler.write(image_handler)
return True
except Exception, ex:
print(ex.args)
print("下载文件出错:{0}".format(ex.message))
return False def get_thumb_picture_link(thumb_page_link):
try:
html_content = urllib2.urlopen(url=thumb_page_link, timeout=DEFAULT_DOWNLOAD_TIMEOUT).read()
html_tree = etree.HTML(html_content)
# print(str(html_tree))
link_tmp_list = html_tree.xpath('//div[@class="photo-item"]/a/img/@src')
page_link_list = []
for link_tmp in link_tmp_list:
page_link_list.append(link_tmp)
return page_link_list
except Exception, ex:
print(ex.message)
return [] def download_pictures(album_link, min_page_id, max_page_id, picture_count_per_page, save_path):
check_save_path(save_path)
min_page_id = 0
while min_page_id < max_page_id:
thumb_page_link = album_link + "?start={0}".format(min_page_id * picture_count_per_page)
thumb_picture_links = get_thumb_picture_link(thumb_page_link)
for thumb_picture_link in thumb_picture_links:
full_picture_link = thumb_picture_link.replace("photo/thumb", "photo/raw")
print('<img src="{0}"/>'.format(full_picture_link))
print("thumb:" + thumb_picture_link)
full_picture_link = thumb_picture_link.replace("photo/thumb", "photo/raw")
save_flag = save_image(image_link=full_picture_link, save_path=save_path)
if not save_flag:
full_picture_link = thumb_picture_link.replace("photo/thumb", "photo/photo")
save_image(image_link=full_picture_link, save_path=save_path)
time.sleep(1)
min_page_id += 1
print("下载完成") # 设置图片保存的本地文件夹
save_path = "E:\\PIC\\douban_11\\"
# 设置相册地址,注意以反斜杠结尾
album_link = "https://site.douban.com/239506/widget/photos/190120540/"
# 设置相册总页数
max_page_id = 20
# 设置每页图片数量,默认为18张
picture_count_per_page = 30 download_pictures(album_link=album_link,
min_page_id=1,
max_page_id=max_page_id,
picture_count_per_page=picture_count_per_page,
save_path=save_path)
##====================================================================##
感叹下,以前学html以及做网页开发的时候,很少关心请求头,顶多就知道GET和POST的区别,白白浪费一个周末研究,可惜!
幸好失败是成功它妈妈,吃一堑长一智!
##====================================================================##
没点好图你们是不会罢休的,哇咔咔!

python--批量下载豆瓣图片之升级版本的更多相关文章
- 用 Python 批量下载百度图片
为了做一个图像分类的小项目,需要制作自己的数据集.要想制作数据集,就得从网上下载大量的图片,再统一处理. 这时,一张张的保存下载,就显得很繁琐.那么,有没有一种方法可以把搜索到的图片直接下载到本地 ...
- 批量下载网站图片的Python实用小工具
定位 本文适合于熟悉Python编程且对互联网高清图片饶有兴趣的筒鞋.读完本文后,将学会如何使用Python库批量并发地抓取网页和下载图片资源.只要懂得如何安装Python库以及运行Python程序, ...
- 批量下载网站图片的Python实用小工具(下)
引子 在 批量下载网站图片的Python实用小工具 一文中,讲解了开发一个Python小工具来实现网站图片的并发批量拉取.不过那个工具仅限于特定网站的特定规则,本文将基于其代码实现,开发一个更加通用的 ...
- python多线程批量下载远程图片
python多线程使用场景:多线程采集, 以及性能测试等 . 数据库驱动类-简单封装下 mysqlDriver.py #!/usr/bin/python3 #-*- coding: utf-8 -*- ...
- 用Python批量下载DACC的MODIS数据
本人初次尝试用Python批量下载DACC的MODIS数据,记下步骤,提醒自己,数据还在下载,成功是否未知,等待结果中...... 若有大佬发现步骤有不对之处,望指出,不胜感激. 1.下载Python ...
- 用python批量下载图片
一 写爬虫注意事项 网络上有不少有用的资源, 如果需要合理的用爬虫去爬取资源是合法的,但是注意不要越界,前一阶段有个公司因为一个程序员写了个爬虫,导致公司200多个人被抓,所以先进入正题之前了解下什么 ...
- 用python批量下载贴吧图片 附源代码
环境:windows 7 64位:python2.7:IDE pycharm2016.1 功能: 批量下载百度贴吧某吧某页的所有帖子中的所有图片 使用方法: 1.安装python2.7,安装re模块, ...
- python批量下载图片的三种方法
一是用微软提供的扩展库win32com来操作IE: win32com可以获得类似js里面的document对象,但貌似是只读的(文档都没找到). 二是用selenium的webdriver: sele ...
- python——批量下载图片
前言 批量下载网页上的图片需要三个步骤: 获取网页的URL 获取网页上图片的URL 下载图片 例子 from html.parser import HTMLParser import urllib.r ...
随机推荐
- C#学习笔记-基础知识篇(不定期更新)
1.父类必须包含构造函数么? 父类必须要有一个构造函数,有参无参都可以. 构造函数是对象的基本,没有构造函数就没有对象,若父类中显示的有参数的构造函数,在子类继承就必须写一个构造函数来调用父类的构造函 ...
- 使用reqire.js 生成二维码
最新项目中使用到 reqiure.js ; 使用了一个月的感觉是: 这个确实是一个利器,如果会使用的话,能轻易理顺js之间的依赖关系,从而可以重复使用js,可以减少代码量,可以提升开发速度,但是 ...
- bootstrap-paginator分页插件的两种使用方式
分页有两种方式: 1. 前台分页:ajax一次请求获取全部数据,适合少量数据(万条数据以下): $.ajax({ type: "GET", url: "",// ...
- Linux下安装PostgreSQL 转载linux社区
Linux下安装PostgreSQL [日期:2016-12-25] 来源:Linux社区 作者:xiaojian [字体:大 中 小] 在Linux下安装PostgreSQL有二进制格式安装和 ...
- [国嵌攻略][163][linux-usb软件系统架构]
软件系统架构 1.主机端软件架构 USB设备驱动->USB核心->USB主控制器驱动->USB主控制器 2.设备端软件架构 Gadget驱动->Gadget API->U ...
- [国嵌攻略][054][NandFlash驱动设计_写]
Nand Flash支持按页写和随机写两种方式,在下面实现的是按页写.闪存在写数据时,只能写入1,不能写入0,所以写函数必须和擦除函数一起使用,并且擦除函数是按块擦除. /************** ...
- URL编码的方法
Global 对象的encodeURI()和encodeURIComponent()方法可以对URI(Uniform ResourceIdentifiers,通用资源标识符)进行编码,以便发送给浏览器 ...
- Web前端性能优化——如何提高页面加载速度
前言: 在同样的网络环境下,两个同样能满足你的需求的网站,一个"Duang"的一下就加载出来了,一个纠结了半天才出来,你会选择哪个?研究表明:用户最满意的打开网页时间是2-5秒, ...
- php中urldecode()和urlencode()起什么作用啊
urlencode()函数原理就是首先把中文字符转换为十六进制,然后在每个字符前面加一个标识符%. urldecode()函数与urlencode()函数原理相反,用于解码已编码的 URL 字符串,其 ...
- js动态生成二维码
一.使用jquery.qrcode生成二维码 1.首先在页面中加入jquery库文件和qrcode插件 <script type="text/javascript" src= ...