HashMap的底层原理
简单说: 底层原理就是采用数组加链表:

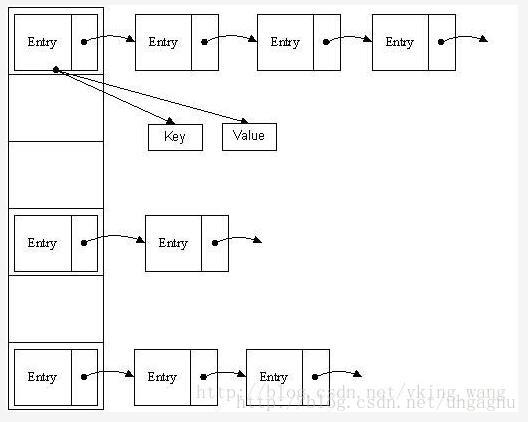
两张图片很清晰地表明存储结构:
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:
// 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
HashMap的底层原理的更多相关文章
- HashMap的底层原理(jdk1.7.0_79)
前言 在Java中我们最常用的集合类毫无疑问就是Map,其中HashMap作为Map最重要的实现类在我们代码中出现的评率也是很高的. 我们对HashMap最常用的操作就是put和get了,那么你知道它 ...
- 谈一下HashMap的底层原理是什么?
底层原理:Map + 无序 + 键唯一 + 哈希表 (数组+Entry)+ 存取值 1.HashMap是Map接口的实现类.实现HashMap对数据的操作,允许有一个null键,多个null值. Co ...
- HashMap的底层原理 cr:csdn:zhangshixi
1. HashMap概述: HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操作,并允许使用null值和null键.此类不保证映射的顺序,特别是它不保证该顺序恒久不变 ...
- 深度解析HashMap集合底层原理
目录 前置知识 ==和equals的区别 为什么要重写equals和HashCode 时间复杂度 (不带符号右移) >>> ^异或运算 &(与运算) 位移操作:1<&l ...
- 浅谈HashMap 的底层原理
本文整理自漫画:什么是HashMap? -小灰的文章 .已获得作者授权. HashMap 是一个用于存储Key-Value 键值对的集合,每一个键值对也叫做Entry.这些个Entry 分散存储在一个 ...
- HashMap 的底层原理
1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二分查找时间复杂度小,为O(1 ...
- 最简单的HashMap底层原理介绍
HashMap 底层原理 1.HashMap底层概述 2.JDK1.7实现方式 3.JDK1.8实现方式 4.关键名词 5.相关问题 1.HashMap底层概述 在JDK1.7中HashMap采用的 ...
- HashMap的底层实现原理
HashMap的底层实现原理1,属性static final int MAX_CAPACITY = 1 << 30;//1073741824(十进制)0100000000000000000 ...
- HashMap底层原理分析(put、get方法)
1.HashMap底层原理分析(put.get方法) HashMap底层是通过数组加链表的结构来实现的.HashMap通过计算key的hashCode来计算hash值,只要hashCode一样,那ha ...
随机推荐
- Caused by: java.lang.ClassNotFoundException: org.hibernate.annotations.common.reflection.MetadataPro
1.错误描述 信息: MLog clients using java 1.4+ standard logging. 2014-7-12 19:29:20 com.mchange.v2.c3p0.C3P ...
- FAT32文件系统的存储组织结构(一)
对磁盘的物理结构,逻辑结构和存储结构有了比较深入的了解后,我们来仔细探讨FAT32文件系统的存储组织结构.说到文件系统的组织结构,我们应该马上意识到,这指的是文件系统在同一个分区内的组织结构,在这个话 ...
- jquery中ajax序列化提交form表单的几种方法。
一,ajax主流的方法 $.ajax({ type: 'post', url: 'your url', data: $("form").serialize(), success: ...
- cisco linksys ea3500 刷机 openwrt
家中router改造成千兆华为A1,淘汰下来的cisco linksys ea3500 终于可以去刷机 openwrt,尽情折腾啦! 分享步骤: 准备文件 https://archive.openw ...
- 关于transform的3D变形函数
继续transform的3D用法: translate3d(x,y,z)定义3D转换 transformX(x)只用x轴的值进行转换: transformY(y)只用y轴的值进行转换: transfo ...
- Codeforces Round #466 (Div. 2)
所有的题目都可以在CodeForces上查看 中间看起来有很多场比赛我没有写了 其实是因为有题目没改完 因为我不想改,所以就没有写了(大部分题目还是改完了的) 我还是觉得如果是打了的比赛就一场一场写比 ...
- 【BZOJ2333】棘手的操作(左偏树,STL)
[BZOJ2333]棘手的操作(左偏树,STL) 题面 BZOJ上看把... 题解 正如这题的题号 我只能\(2333\) 神TM棘手的题目... 前面的单点/联通块操作 很显然是一个左偏树+标记 ( ...
- 杜教筛:Bzoj3944: sum
题意 求\(\sum_{i=1}^{n}\varphi(i)和\sum_{i=1}^{n}\mu(i)\) \(n <= 2^{31}-1\) 不会做啊... 只会线性筛,显然不能线性筛 这个时 ...
- [BZOJ1207] [HNOI2004] 打鼹鼠 (dp)
Description 鼹鼠是一种很喜欢挖洞的动物,但每过一定的时间,它还是喜欢把头探出到地面上来透透气的.根据这个特点阿Q编写了一个打鼹鼠的游戏:在一个n*n的网格中,在某些时刻鼹鼠会在某一个网格探 ...
- 一个10年Java程序员的年终总结,献给还在迷茫中的你
我越来越担心我作为一个Java程序员的未来. 恍然间,发现自己在这个行业里已经摸爬滚打将近10年了,原以为自己就凭已有的项目经验和工作经历怎么着也应该算得上是一个业内比较资历的人士了,但是今年在换工作 ...