利用Python进行数据分析
最近在阅读《利用Python进行数据分析》,本篇博文作为读书笔记 ,记录一下阅读书签和实践心得。
准备工作
python环境配置好了,可以参见我之前的博文《基于Python的数据分析(1):配置安装环境》。还需要安装第三方包包括NumPy、pandas、matplotlib、IPython、SciPy。用pip安装工具下载自动安装即可,如果有网络问题,请在自行百度”host google“更新host文件。
接下来是配置IPython,初步感受了这个与之前接触的IDE完全不一样的编程方式,感觉很不错,推荐给大家。
安装主要需要安装IPython和IPython notebook两个第三方包,通过pip install 一下就好了。
安装成功后,启动IPython服务器(?我感觉应该是后台自动开了一个服务器),命令是IPython notebook。
上述步骤都搞定后,在浏览器上输入“http://localhost:8888/tree”,可以看到这个界面准备工作已经就绪了。
Pandas
书本上手用了一个时区的数据对于Pandas的DataFrame和Series两个对象进行简单的操作。我不是很喜欢这种直接上实例教学的方法,所以先在网上找了一些Pandas库的基本对象和常用函数。
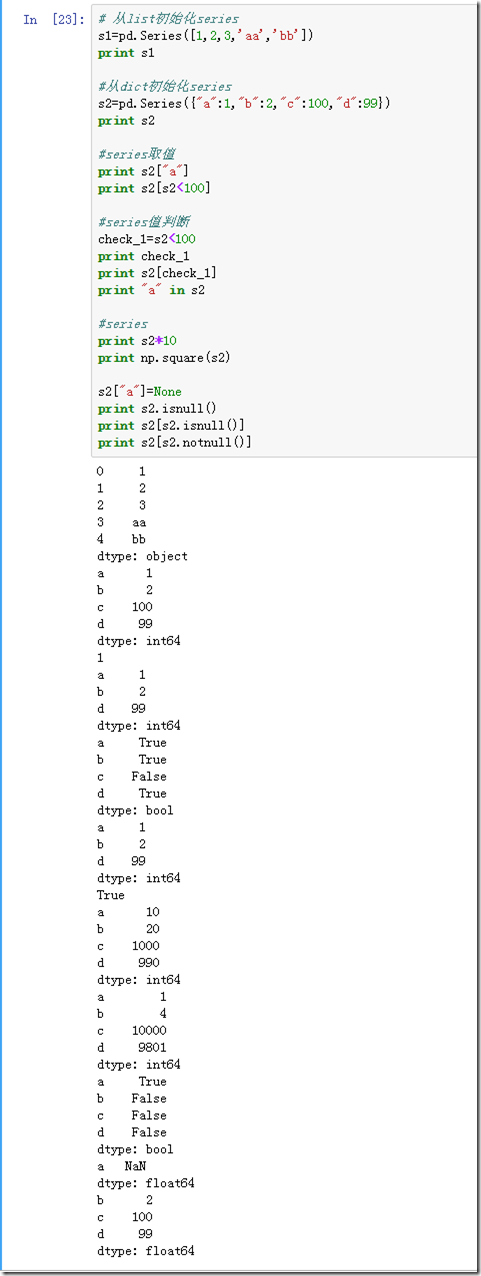
- Series
Series是一个一维数组对象,与list数据结构相近,Series中每个条目都会被分配一个标签索引。默认情况下,每个条目都会收到一个从0到N之间的索引标签,其中N等于Series的长度减一。Series可以从list或者dict初始化,可以多种取值方式,非常有意思:
- DataFrame
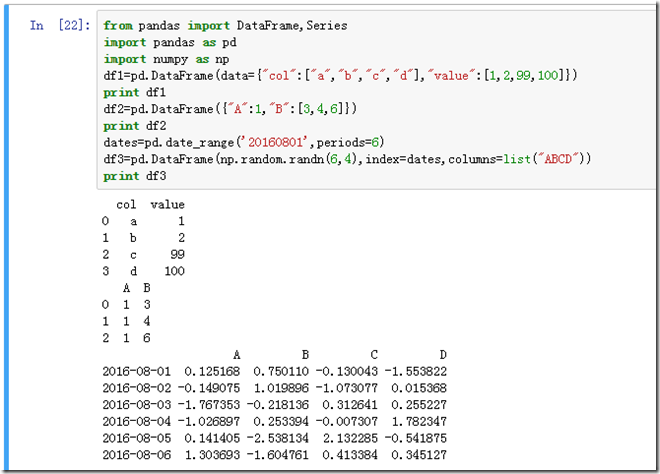
DataFrame是一种由列向量和行向量组成的数据结构,它类似于电子数据表、数据库表格,也可以认为DataFrame是有多个共享索引值的Series对象构成。
对于DataFrame,可以从python的dict中转化得到,也可以从csv或者数据库中获得。通过help(Pandas.DataFrame)可以获得信息:
class DataFrame(pandas.core.generic.NDFrame)
| Two-dimensional size-mutable, potentially heterogeneous tabular data
| structure with labeled axes (rows and columns). Arithmetic operations
| align on both row and column labels. Can be thought of as a dict-like
| container for Series objects. The primary pandas data structure
|
| Parameters
| ----------
| data : numpy ndarray (structured or homogeneous), dict, or DataFrame
| Dict can contain Series, arrays, constants, or list-like objects
| index : Index or array-like
| Index to use for resulting frame. Will default to np.arange(n) if
| no indexing information part of input data and no index provided
| columns : Index or array-like
| Column labels to use for resulting frame. Will default to
| np.arange(n) if no column labels are provided
| dtype : dtype, default None
| Data type to force, otherwise infer
| copy : boolean, default False
| Copy data from inputs. Only affects DataFrame / 2d ndarray input
|
| Examples
| --------
| >>> d = {'col1': ts1, 'col2': ts2}
| >>> df = DataFrame(data=d, index=index)
| >>> df2 = DataFrame(np.random.randn(10, 5))
| >>> df3 = DataFrame(np.random.randn(10, 5),
| ... columns=['a', 'b', 'c', 'd', 'e'])
|
| See also
| --------
| DataFrame.from_records : constructor from tuples, also record arrays
| DataFrame.from_dict : from dicts of Series, arrays, or dicts
| DataFrame.from_csv : from CSV files
| DataFrame.from_items : from sequence of (key, value) pairs
| pandas.read_csv, pandas.read_table, pandas.read_clipboard
基本上可以对如何构建DataFrame对象有一个基本的概念,如果不从外部数据(csv、数据库)中导入文件的话,可以通过字典或者numpy来构建输入数据:
利用Python进行数据分析的更多相关文章
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(5) NumPy基础: ndarray索引和切片
概念理解 索引即通过一个无符号整数值获取数组里的值. 切片即对数组里某个片段的描述. 一维数组 一维数组的索引 一维数组的索引和Python列表的功能类似: 一维数组的切片 一维数组的切片语法格式为a ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(4) NumPy基础: ndarray简单介绍
一.NumPy 是什么 NumPy 是 Python 科学计算的基础包,它专为进行严格的数字处理而产生.在之前的随笔里已有更加详细的介绍,这里不再赘述. 利用 Python 进行数据分析(一)简单介绍 ...
- 《利用python进行数据分析》读书笔记 --第一、二章 准备与例子
http://www.cnblogs.com/batteryhp/p/4868348.html 第一章 准备工作 今天开始码这本书--<利用python进行数据分析>.R和python都得 ...
- 利用python进行数据分析之绘图和可视化
matplotlib API入门 使用matplotlib的办法最常用的方式是pylab的ipython,pylab模式还会向ipython引入一大堆模块和函数提供一种更接近与matlab的界面,ma ...
- 利用Python进行数据分析——Numpy基础:数组和矢量计算
利用Python进行数据分析--Numpy基础:数组和矢量计算 ndarry,一个具有矢量运算和复杂广播能力快速节省空间的多维数组 对整组数据进行快速运算的标准数学函数,无需for-loop 用于读写 ...
- 利用Python进行数据分析——Ipython
利用Python进行数据分析--Ipython 一.Ipython一些常用命令 1.TAB自动补全 2.变量+? 显示相关信息 3.函数名+??可以获取函数的代码 4.使用通配符* np.load? ...
随机推荐
- HTML5 在<a>标签内放置块级元素
原文地址:HTML5: Wrap Block-Level Elements with A's 原文日期: 2010年06月26日 翻译日期: 2013年08月22日 对比起XHTML来说,HTML5通 ...
- 【一天一道LeetCode】#72. Edit Distance
一天一道LeetCode 本系列文章已全部上传至我的github,地址:ZeeCoder's Github 欢迎大家关注我的新浪微博,我的新浪微博 欢迎转载,转载请注明出处 (一)题目 Given t ...
- 识别你的ADFS是什么版本的(Which version of ADFS is running)
各版本的ADFS版本识别见如下链接: http://jorgequestforknowledge.wordpress.com/2014/02/23/gathering-architectural-de ...
- 如何设计一个web容器
开发一个web容器涉及很多不同方面不同层面的技术,例如通信层的知识,程序语言层面的知识等等,且一个可用的web容器是一个比较庞大的系统,要说清楚需要很长的篇幅,本文旨在介绍如何设计一个web容器,只探 ...
- 开源数字媒体资产管理系统:Razuna安装方法
Razuna以一个使用Java语言编写的开源的数字媒体资产管理(Digital Asset Management)系统.在这里翻译一下它的安装步骤. Razuna包含以下版本: Razuna Stan ...
- RB-tree (红黑树)相关问题
今天被问到了红黑树的规则,简述总结一下: 1.每个节点不是红色就是黑色. 2.根节点为黑色. 3.如果节点为红,其子节点必须为黑. 4.任一节点至NULL(树尾端)的任何路径,所含之黑节点数必须相同. ...
- UML之部署图
部署图,英文名曰:Deployment Diagram,通常也称配置图,她是用来显示系统中软件和硬件的物理结构,从部署图中,我们可以了解到软件和硬件组件之间的物理关系以及处理节点的组件分布情况,使用部 ...
- 股票K线图
代码链接地址:点击打开链接
- Java基本数据类型和长度
转自:http://lysongfei.iteye.com/blog/602546 java数据类型 字节 表示范围 byte(字节型) 1 -128-127 short(短整型 ...
- Android特效专辑(十一)——仿水波纹流量球进度条控制器,实现高端大气的主流特效
Android特效专辑(十一)--仿水波纹流球进度条控制器,实现高端大气的主流特效 今天看到一个效果挺不错的,就模仿了下来,加上了一些自己想要的效果,感觉还不错的样子,所以就分享出来了,话不多说,上图 ...