Python:黑板课爬虫闯关第三关
第三关开始才算是进入正题了。
输入网址 http://www.heibanke.com/lesson/crawler_ex02/,直接跳转到了 http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex02/,显示如下

仔细看一下这个网址,显然,这是一个登陆网址,next参数应该是登录成功后跳转网页的地址。注册登录后,显示第三关:
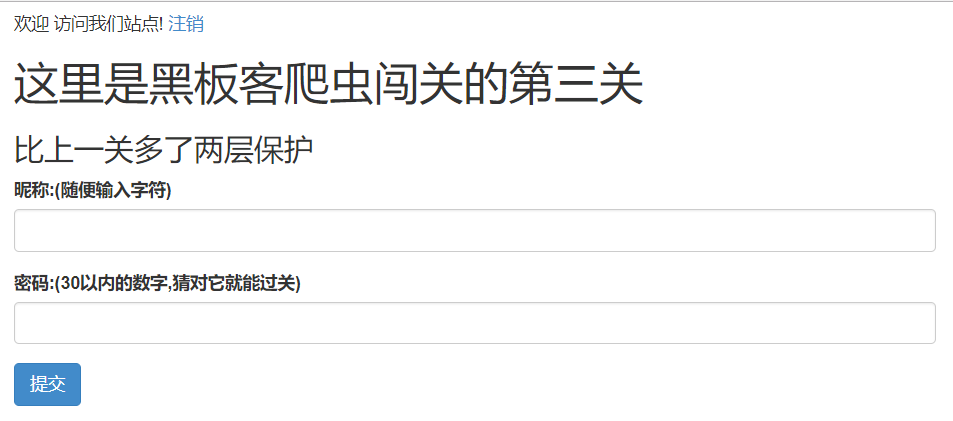
首先可以肯定的是,必须要先登录,并保持登录状态,否则是爬不过关的。界面提示有两层保护,这应该就是第一层。
先注册了一个账号,然后用代码尝试登录,post 用户名密码之后,print 一下响应的 html,发现并不是我看到的第三关的内容,说明登录没有成功。看一下里面有一句话:You are seeing this message because this site requires a CSRF cookie when submitting forms. This cookie is required for security reasons, to ensure that your browser is not being hijacked by third parties.
简单的说,就是为了防止CSRF攻击(其实就是黑板课设的障碍),需要一个cookie。
退出登录,回到登录界面,打开开发者工具(我用的是谷歌浏览器),追踪一下网络请求,发现登录的时候,除了用户名密码,还有一个 csrfmiddlewaretoken 参数,而 csrfmiddlewaretoken 参数来自于 cookie 中的 csrftoken。
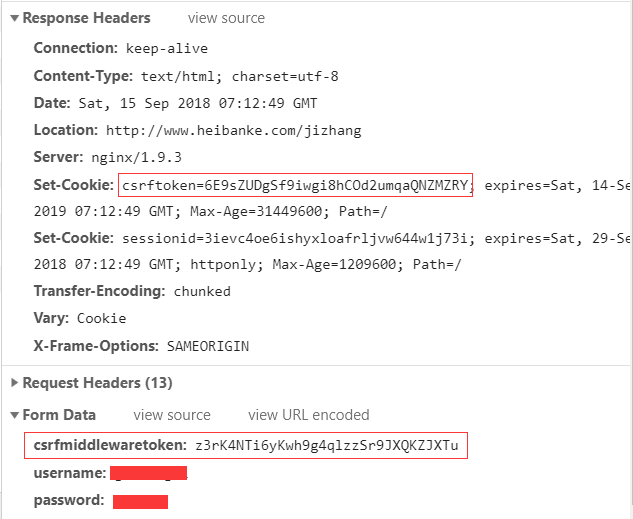
先 get 一下登录页面,从返回的 session 中获取 cookie 值中获取 csrftoken 值,连同用户名密码一起 post,print 响应的 html,结果正确。
然后就是跟第二关一样,暴力破解密码了。保险起见,也追踪了下请求,发现机制跟登录是一样的,也需要csrfmiddlewaretoken 参数,一样处理就好了。
这样思路就理清了,每次 post 用户名密码之前,先 get 请求一下,从服务器发给你的 cookie 中获取 csrftoken 的值作为 post 时的 csrfmiddlewaretoken 参数即可。
代码如下:
import re
import requests
import time def main():
url_login = 'http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex02/'
url = 'http://www.heibanke.com/lesson/crawler_ex02/'
session = requests.Session()
# 获取cookie
session.get(url_login)
token = session.cookies['csrftoken']
# 登录
session.post(url_login, data={'csrfmiddlewaretoken': token, 'username': '', 'password': ''})
for psd in range(30):
print(f'test password {psd}')
session.get(url)
token = session.cookies['csrftoken']
r = session.post(url, data={'csrfmiddlewaretoken': token, 'username': 'aa', 'password': psd})
html = r.text
if '密码错误' not in html:
m = re.search('(?<=\<h3\>).*?(?=\</h3\>)', html)
print(m.group())
m = re.search('(\<).*?href="([^"]*?)".*?(\>下一关\</a\>)', html)
print(f'下一关 http://www.heibanke.com{m.group(2)}')
return
else:
time.sleep(1) if __name__ == '__main__':
main()
Python:黑板课爬虫闯关第三关的更多相关文章
- Python:黑板课爬虫闯关第一关
近日发现了[黑板课爬虫闯关]这个神奇的网页,练手爬虫非常的合适 地址:http://www.heibanke.com/lesson/crawler_ex00/ 第一关非常的简单 get 请求网址,在响 ...
- Python:黑板课爬虫闯关第五关
第五关是最后一关了,至此之后黑板课就没有更新过关卡了. 第五关地址:http://www.heibanke.com/lesson/crawler_ex04/ 可以看到,是在第三关的基础上加了验证码. ...
- Python:黑板课爬虫闯关第四关
第四关地址:http://www.heibanke.com/lesson/crawler_ex03/ 一开始看到的时候有点蒙,不知道啥意思,说密码需要找出来但也没说怎么找啊. 别急,随便输了个昵称和密 ...
- Python:黑板课爬虫闯关第二关
第二关依然是非常的简单 地址:http://www.heibanke.com/lesson/crawler_ex01/ 随便输入昵称呢密码,点击提交,显示如下: 这样看来就很简单了,枚举密码循环 po ...
- python3 黑板客爬虫闯关游戏(一)
这是学习python爬虫练习很好的网站,强烈推荐! 地址http://www.heibanke.com/lesson/crawler_ex00/ 第一关猜数字 很简单,直接给出代码 import ur ...
- python3 黑板客爬虫闯关游戏(四)
这关较第三关难度增加许多,主要多了并发编程 密码一共有100位,分布在13页,每页打开的时间在15秒左右,所以理所当然的想到要用并发,但是后来发现同IP访问间隔时间不能小于8秒,不然会返回404,所以 ...
- python3 黑板客爬虫闯关游戏(三)
第三关,先登录,再猜密码,这关难度较第二关大幅增加,要先去注册一个登录账号,然后打开F12,多登录几次,观察headers数据的变化 给出代码,里面注释很详细 import urllib.reques ...
- python3 黑板客爬虫闯关游戏(二)
第二关猜登录密码,需要用到urllib.request和urllib.parse 也很简单,给代码 import urllib.request as ur import urllib.parse as ...
- <爬虫>黑板爬虫闯关02
import requests from lxml import etree ''' 黑板爬虫闯关02 网址:http://www.heibanke.com/lesson/crawler_ex01/ ...
随机推荐
- BZOJ_1774_[Usaco2009 Dec]Toll 过路费_floyd
BZOJ_1774_[Usaco2009 Dec]Toll 过路费_floyd 题意: 跟所有人一样,农夫约翰以着宁教我负天下牛,休叫天下牛负我的伟大精神,日日夜夜苦思生 财之道.为了发财,他设置了一 ...
- BZOJ_1029_ [JSOI2007]建筑抢修_贪心+堆
BZOJ_1029_ [JSOI2007]建筑抢修_贪心+堆 Description 小刚在玩JSOI提供的一个称之为“建筑抢修”的电脑游戏:经过了一场激烈的战斗,T部落消灭了所有z部落的入侵者.但是 ...
- C# 利用VS自带的WSDL工具生成WebService服务类
C# 利用VS自带的WSDL工具生成WebService服务类 WebService有两种使用方式,一种是直接通过添加服务引用,另一种则是通过WSDL生成. 添加服务引用大家基本都用过,这里就不讲 ...
- 树莓派使用modbus与stm32通信
树莓派+stm32开发板通信树莓派上使用java+jamod实现.jamod官网stm32使用freemodbus实现
- Hadoop3.0 WordCount测试一直Accept 状态,Nodes of the cluster 页面node列表个数为0
起因是我运行wordcount测试一直卡主,不能执行,一直处于 Accept 状态,等待被执行,刚开始是各种配置yarn参数,以及host配置,后来发现还是不行 hadoop 集群安装完成后,在500 ...
- 基于Orangpi Zero和Linux ALSA实现WIFI无线音箱(三)
作品已经完成,先上源码: https://files.cnblogs.com/files/qzrzq1/WIFISpeaker.zip 全文包含三篇,这是第三篇,主要讲述接收端程序的原理和过程. 第一 ...
- 为啥程序会有bug?
如果这是第二次看到我的文章,欢迎右侧扫码订阅我哟~
- Windows下Goland的Terminal设置为Git Bash
Windows下Terminal默认的使用的是系统自带的cmd,功能实在太少,用起来远不如Git Bash来得方利和高效.其实要在Goland的Terminal中使用Bash设置起来也很简单,设置位置 ...
- java游戏开发杂谈 - 画布和画笔
在Eclipse里,编写如下两个类: package game2; import java.awt.Color; import java.awt.Graphics; import javax.swin ...
- javascript入门篇(五)
将日期转换为数字 全局方法 Number() 可将日期转换为数字 d = new Date(); Number(d) // 返回 1404568027739 日期方法 getTime ...