[CVPR2018] Context-aware Deep Feature Compression for High-speed Visual Tracking
基于内容感知深度特征压缩的高速视觉跟踪
论文下载:http://cn.arxiv.org/abs/1803.10537 本文有趣的地方在于: |
摘要
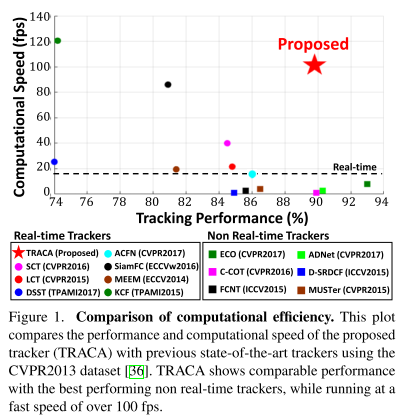
作者提出了一种在实时跟踪领域高速且state-of-the-art表现的基于context-aware correlation filter的跟踪框架。这个方法的高速性依赖于会根据内容选择对应的专家自编码器来对图片进行压缩;context在本文中表示根据要跟踪目标的外观大致分的类。在预训练阶段,每个类训练一个自编码器。在跟踪阶段,根据给定目标选择最佳的自编码器——专家自编码器,并且在下面阶段中仅使用这个网络。为了在压缩后的特征图上达到好的跟踪效果,作者分别在与训练阶段和微调专家自编码器阶段提出了一种去噪过程和新的正交损失函数。多方认证这个方法表现良好且达到了显著的效果,超过100fps。
1. Introduction
视觉跟踪因为深度学习的出现效果提升显著。近年来,跟踪领域主要流行两种方法。一种是持续微调网络来学习目标的改变。虽然网络表现正确率高且具有鲁棒性,但是计算速度不足以满足在线跟踪的要求。第二种是先用深度网络提取特征,再接上correlation filters。但是表示大规模数据的特征如ImageNet,往往是高维度的。这往往也满足不了在线跟踪的速度需求。
本工作中,作者提出了一种基于correlation filter跟踪器,使用了context-aware的深度特征压缩来节省计算时间。这做法的动机是因为相比于分类和检测任务,低层次的特征图能充分表示单目标物体。更具体地说,作者训练了多个自编码器,每个种类一个。我们介绍一种无监督学习来对训练样本进行聚类,再根据每个类别训练一个自编码器。在跟踪阶段,给定特定的目标,context-aware网络会选择一个合适的自编码器。在使用新损失函数微调选定的专家网络后,网络输出压缩后的特征图。压缩的特征图降低了冗余性和稀疏性,并提升了追踪的正确率。
3. Methodology
TRAcker使用多个自编码器来压缩特征(TRACA)。每个专家自编码器根据各自类别对VGG-Net的特征图进行压缩。
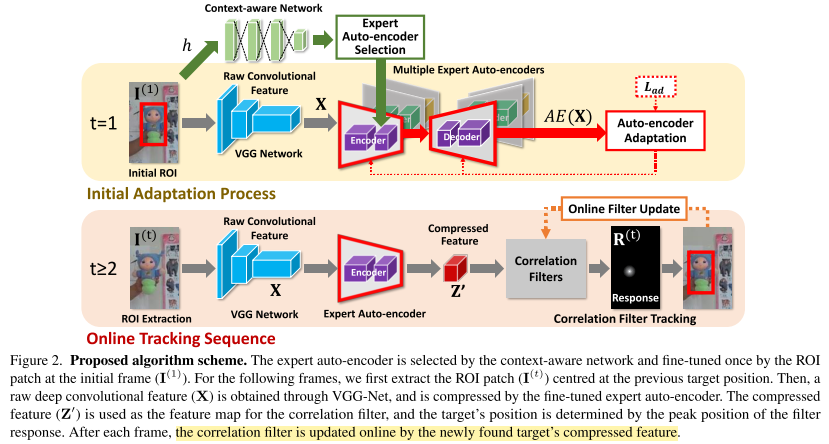
3.1 Expert Auto-encoders
Architecture:自编码器提供了一种无监督的方法学习特征。假设有Ne个相同结构的专家自编码器。自编码器堆积了Nl个编码器和解码器,来对通道数进行压缩和解压。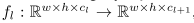 ,
, 。所有卷积层kernel size为3x3 + ReLU。
。所有卷积层kernel size为3x3 + ReLU。
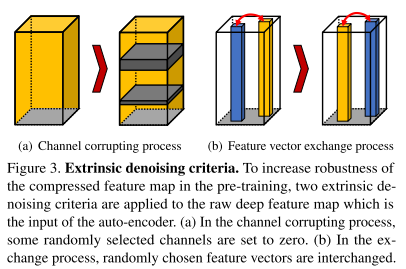
Pre-training:预阶段分为三部分。首先用所有样本(VGG-Net的输出)训练一个初始自编码器AE0,然后使用AE0的压缩特征图进行聚类来得到Ne个类。训练初始自编码的目的是为了后面更好收敛和更好finetune。为了初始自编码器更具有鲁棒性,作者加入了两个噪声的操作。一是固定数量的特征通道置0。二是交换特征图的一些向量来模拟现实生活中遮挡的情况。
考虑到初始自编码器重输入和最终输出有一段距离不好学,实验也观察到经常出现过拟合和不平稳收敛。作者提出了基于multi-stage距离的损失函数。假设Xj为输入的特征图,AE(X)为一部分的编码和解码层。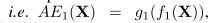

其中,第一个求和针对一个mini batch所有样本,m为mini-batch size;第二个求和就是所有特征图和对加噪声的特征图进行不同层数加解码的复原图之间的差。
聚类的时候,首先重复1000次找到2Ne的样本,从中找到他们之间的欧几里得距离最大的初始点,然后聚类。然后减去Ne个拥有最小样本的中心。
3.2 Context-aware Network
Architecture:基于内容的网络根据跟踪的目标选择具体的自编码器。首先加载VGG-M网络,内容网络由{conv1, conv2, conv3}和{fc4, fc5, fc6}组成,其中{conv1, conv2, conv3, fc4}加载VGG-M的权重。fc5输出1024,fc6输出类别,使用交叉熵训练。
3.3 Correlation Filter
本部分不熟悉,略。
3.4 Tracking Process
3.4.1 Initial Adaptation Process
Region of interest extraction:首先根据目标所在ROI扩大2.5倍crop。
Initial sample augmentation:对ROI进行多重高斯过滤和翻转进行数据增强。因为数据量少,所以使用前面提到的加噪声操作和协相关过滤器一起的损失函数。
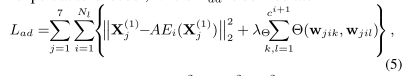
Background channel removal:经过压缩的特征图通过微调的专家编码器得到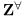 。然后我们删除掉
。然后我们删除掉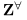 中对背景相应大的通道。定义Zbb操作为,对所有在bounding box(bb)外的像素点设置为0。定义第k通道的bb响应率(如下),删除响应率低的。
中对背景相应大的通道。定义Zbb操作为,对所有在bounding box(bb)外的像素点设置为0。定义第k通道的bb响应率(如下),删除响应率低的。

3.4.2 Online Tracking Sequence
对追踪不熟悉,这部分先hold着。(后补)
4. Experimental Result

[CVPR2018] Context-aware Deep Feature Compression for High-speed Visual Tracking的更多相关文章
- 论文阅读之:Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space
Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space 2018-01-04 ...
- 论文笔记:Deep feature learning with relative distance comparison for person re-identification
这篇论文是要解决 person re-identification 的问题.所谓 person re-identification,指的是在不同的场景下识别同一个人(如下图所示).这里的难点是,由于不 ...
- ICLR 2018 | Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training
为了降低大规模分布式训练时的通信开销,作者提出了一种名为深度梯度压缩(Deep Gradient Compression, DGC)的方法.DGC通过稀疏化技术,在每次迭代时只选择发送一部分比较&qu ...
- 《Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks》论文笔记
论文题目<Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Ne ...
- 《Hyperspectral Image Classification With Deep Feature Fusion Network》论文笔记
论文题目<Hyperspectral Image Classification With Deep Feature Fusion Network> 论文作者:Weiwei Song, Sh ...
- 论文笔记:SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks 2019-04-02 12:44:36 Paper:ht ...
- 论文笔记: Dual Deep Network for Visual Tracking
论文笔记: Dual Deep Network for Visual Tracking 2017-10-17 21:57:08 先来看文章的流程吧 ... 可以看到,作者所总结的三个点在于: 1. ...
- 【论文阅读】Deep Clustering for Unsupervised Learning of Visual Features
文章:Deep Clustering for Unsupervised Learning of Visual Features 作者:Mathilde Caron, Piotr Bojanowski, ...
- Deep Reinforcement Learning with Iterative Shift for Visual Tracking
Deep Reinforcement Learning with Iterative Shift for Visual Tracking 2019-07-30 14:55:31 Paper: http ...
随机推荐
- java设计模式------建造者模式
建造者模式(Builder),将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示. 类图 描述 Builder:定义一个建造者抽象类,以规范产品对象的各个组成部分的建造.这个接口 ...
- 进程与fork()、wait()、exec函数组
进程与fork().wait().exec函数组 内容简介:本文将引入进程的基本概念:着重学习exec函数组.fork().wait()的用法:最后,我们将基于以上知识编写Linux shell作为练 ...
- 201621123062《java程序设计》第五周作业总结
1. 本周学习总结 1.1 写出你认为本周学习中比较重要的知识点关键词 关键词:interface.Comparable.comparator 1.2 尝试使用思维导图将这些关键词组织起来.注:思维导 ...
- spring mvc 整合Quartz
Quartz是一个完全由java编写的开源作业调度框架.不要让作业调度这个术语吓着你.尽管Quartz框架整合了许多额外功能, 但就其简易形式看,你会发现它易用得简直让人受不了!Quartz整合在sp ...
- selenium webdriver API
元素定位 #coding=utf-8 from selenium import webdriver from selenium.webdriver.firefox.firefox_binary imp ...
- java unicode和字符串间的转换
package ykxw.web.jyf; /** * Created by jyf on 2017/5/16. */ public class unicode { public static voi ...
- Linux之用户与用户组
1.Linux是一种 多用户多任务分时操作系统. 2.Linux的用户只有两个等级:root用户和非root用户. Linux系统默认 内置了root用户 和一些非root用户,如nobody,a ...
- loadrunner下载资源时步骤下载超时 (120 seconds) 已过期
下载资源所用时间超过120秒时,就会报出这个错误,解决方法是设置加大超时时间 运行时设置(快捷键F4) Internet 协议--首选项--高级--选项--General--步骤下载超时(秒) 可以把 ...
- 不看就亏了:DELL EqualLogic PS6100详解及数据恢办法
DELL EqualLogic PS6100采用虚拟ISCSI SAN阵列,为远程或分支办公室.部门和中小企业存储部署带来企业级功能.智能化.自动化和可靠性,支持VMware.Solaris.Linu ...
- 通过URL传递PDF名称参数显示PDF
1 <%@ page language="java" import="java.util.*,java.io.*" 2 pageEncoding=&quo ...